Feeds Fun — читалка новостей с тегами и ChatGPT
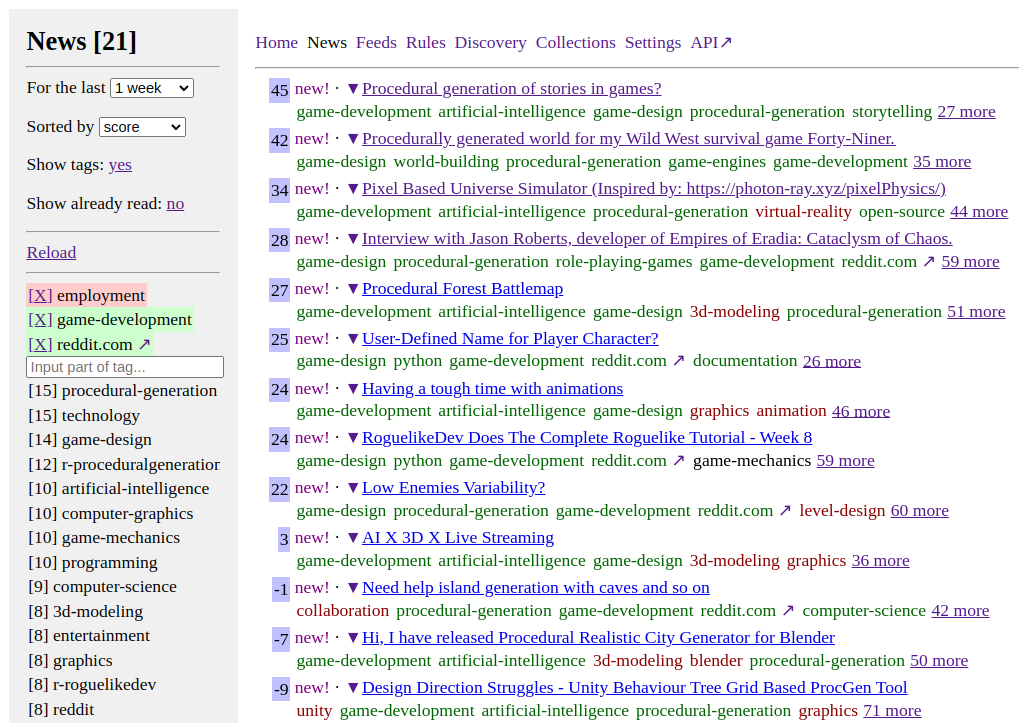
Выглядит неприглядно, но это временно.
Задержался с постом, а между тем читалка уже работает и экономит мне 4-8 часов в неделю.
Для нетерпеливых и ленивых:
- Репозиторий: github.com/tiendil/feeds.fun
- Сайт: feeds.fun — заходите, подписывайтесь на подготовленные коллекции новостей, экспериментируйте.
Суть:
- Читалка автоматически определяет теги для каждой новости. Тут очень кстати пришлась ChatGPT.
- Вы создаёте правила в духе
elon-musk & twitter => score -100500,procedural-content-generation & hentai => score +13. - В интерфейсе сортируете новости по интересности и читаете только самые-самые именно для вас.
Если есть просьбы по фичам — создавайте issue, постараюсь воплощать. Хочется, чтобы штука пошла в народ.
Yet another Тарантога
Не только я пытаюсь собрать всю свою информацию в одном месте.
Вот описание созданной за год инфраструктуры от другого энтузиаста.
Знакомство с блогом karlicoss и подтолкнуло меня делать собственный велосипед. Всегда приятно узнать, что ты не один такой упоротый :-) Там же я позаимствовал пару базовых концепций.
В отличии от меня, karlicoss избрал более прагматичный подход:
- Поставил во главу угла data liberation — освобождение данных — получение копий всех сущенственных данных, которыми пытаются владеть облака и прочие сервисы. Возможно, логика в том, что владение данными первично, а как их обработать всегда можно придумать.
- Не пытается (пока) изобретать универсальные форматы или универсальный софт. Просто делает инфраструктуру экспорта, хранения и обработки информации, которая работает. То есть у него получается сеть из источников, экспортёров, обработчиков и дашбордов.
Какой из подходов лучше, не знаю. Я отказался от такого варианта потому, что не вижу как разумными силами в долгосрочной перспективе гарантировать устойчивость настолько гетерогенной сети к регрессиям. В случае с централизованной базой знаний я это хотябы в теории представлю.
Но из того, что чего-то не вижу, не следует, что этого нет.
Тарантога: модель данных
Постепенно пилю Тарантогу. Дело идёт не быстро: отвлекаюсь то на праздники, то на сторонние эксперименты, то на разбирательства с современными пайплайнами. Но постепенно что-то вырисовывается. Довольно странное :-)
Кстати, я завёл отдельный тег для постов про него.
Так вот, о странном и расскажу — о модели данных. Но без обоснования решений, какие обоснования в прототипе.
О блоге
Пост родился из главы итогов года, которая поясняла всплеск моей активности в блоге. Глава разрослась и была не особо нужна, поэтому вынес в отдельный текст.
Он состоит из трёх частей:
- Исторической справки — как я маялся с блогом, как пришёл туда, куда пришёл.
- Ответа на вопрос почему я веду блог.
- Размышлений о текущем состоянии блога.
Первая часть вряд ли вам будет интересна — это скорее подводка для меня к следующим главам.
Экзокортекс: минимальная функциональность
](https://tiendil.org/static/posts/exocortex-minimal-functionality/images/exocortex-minimal-functionality-cover.png)
В тексте о чертах современного экзокортекса я резюмировал его суть следующим образом: единообразное автоматизируемое взаимодействие с качественной личной информацией из гетерогенных источников.
Давайте теперь подумаем о функциональности подобной системы. Пока без конкретики сформулируем требования и ограничения, которые уместно к ней применить.