DepMesh — делаем зависимости между файлами частью архитектуры проекта
Перед внесением изменений, например в код, агенты часто должны ответить на прикладные вопросы:
- Какие тесты следует прочитать перед изменением этого файла?
- Какие спецификации регулируют этот модуль?
- Какие модули импортирует этот код?
- Какие артефакты затронуты этим изменением спецификации?
- etc.
Иными словами, агент должен обнаружить все зависимости между файлами и добавить их в контекст, чтобы корректно выполнить задачу.
Получение ответов на подобные вопросы требует от агента подумать, сформировать план действий, выполнить его и проанализировать результаты. Всё это съедает токены, контекст и время, без гарантии полноты и корректности результата.
Например, агент должен решить каким способом искать каждый конкретный тип зависимостей. Иногда, как в случае с цепочками импортов, агент должен прочитать и распарсить исходник, чтобы понять какие модули он импортирует, а затем сгенерировать пути к этим модулям и прочитать их — трудоёмко и неэффективно.
Результат такого «агентного поиска» не гарантирован, агент может забыть погрепать по имени функции и потерять важную зависимость, или пропустить нишевую спеку, потому что решил, что именно в данном случае она не нужна.
Более того, для поиска агент задействует кучу инструментов, каждый из которых самим своим использованием увеличивает потребление токенов и отъедает контекст. Для одной и той же задачи агент может раз от раза выбирать разные инструменты или вызывать их с разными параметрами, что убивает предсказуемость и воспроизводимость результата.
Общепринятые способы улучшить ситуацию, это интеграция LSP или чего-то подобного в качестве инструмента агента или разворачивание одной из миллиона RAG-систем. Это помогает делу, но не снимает все проблемы. Например, не гарантирует полноту, минимальность и детерминированность результата.
В то же время, с древних времён у нас есть огромный пул утилит и библиотек для поиска файлов и анализа исходного кода, которые умеют делать это быстро и эффективно, без всяких там LLM. Каждая из них в своей конкретной области работает намного лучше вероятностной модели.
Было бы здорово, подумал я, иметь одну абстракцию над всеми этими инструментами, которая предоставляет агенту универсальный интерфейс для извлечения любых зависимостей между файлами (какие настроите) и не требует от него думать что и каким образом искать.
Чтобы её можно было использовать, например, вот так:
> depmesh dependencies -r governed_by -r tested_by ./depmesh/cli/application.py
## governed_by
Specifications that apply to the artifact.
- @/specs/architecture/entities.md
- @/specs/architecture/errors.md
- @/specs/architecture/modules_layout.md
- @/specs/architecture/naming.md
- @/specs/architecture/static_analysis.md
- @/specs/architecture/tests.md
- @/specs/behavior/cli.md
- @/specs/behavior/file_paths.md
## tested_by
Tests that verify the artifact.
- @/depmesh/cli/tests/test_application.py
Так и появился DepMesh.
Donna готова к использованию
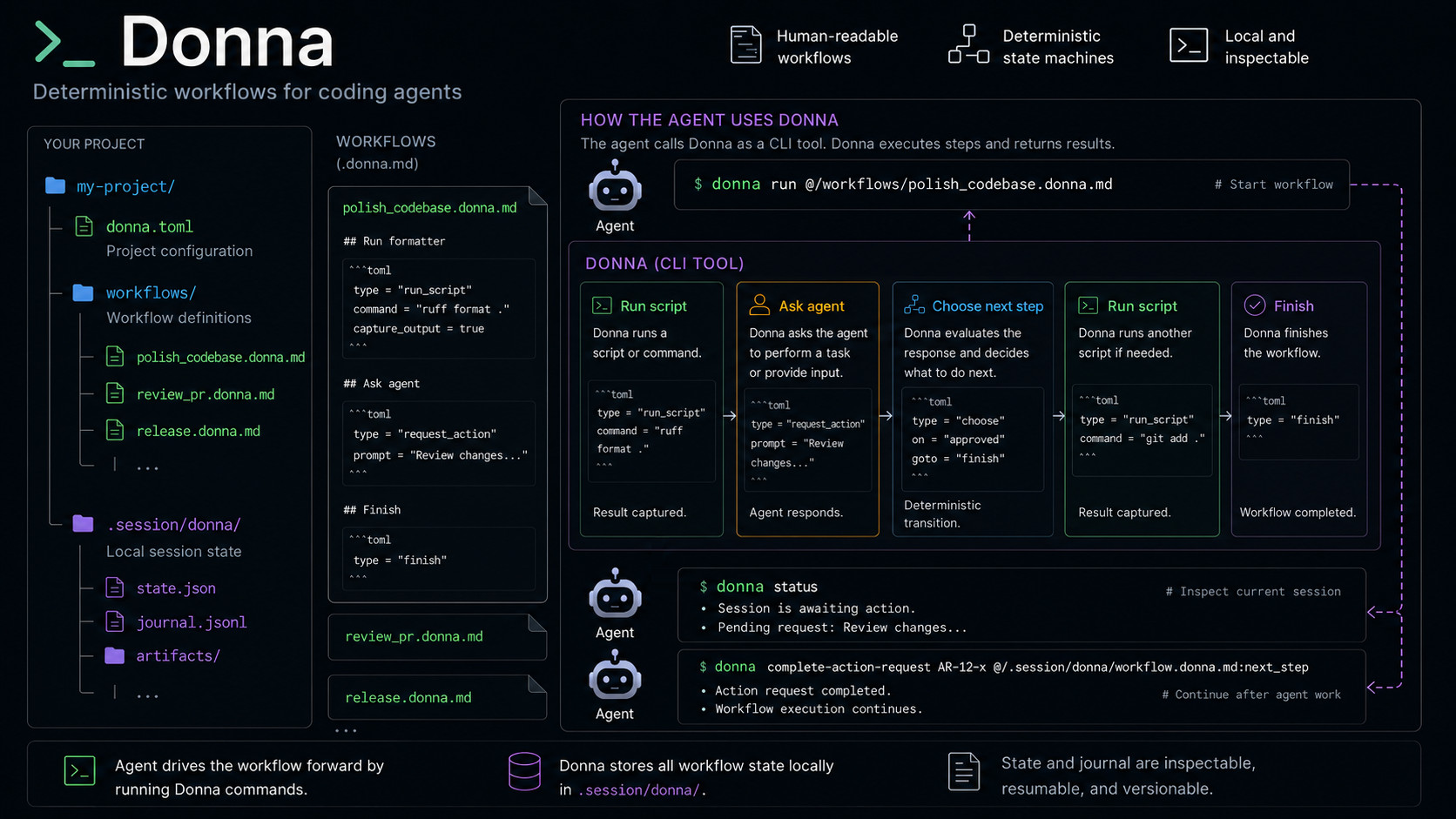
Как работает Donna.
В феврале я выпустил Donna(оригинальный пост) — CLI-утилиту для запуска агентных сценариев как стейт-машин и их описания в Markdown-файлах.
Поскольку я разрабатывал её одновременно разбираясь как работать с агентами, у меня получился переусложнённый, универсальный монстр. Donna имела много полезных функций, но совместно они слишком сильно ограничивали окружение разработчика и требовали слишком много времени на изучение.
Поэтому, набравшись опыта, я решил следовать философии Unix и отрефакторить монолит в набор меньших инструментов, каждый с отдельной чёткой зоной ответственности. Новая Donna — это первый из них (второй — это depmesh — я расскажу о нём в отдельном посте).
Новая Donna решает проблемы управления потоком исполнения агентов при длительной работе. Логика следующая:
- Большая часть разработки на мета-уровне повторяема: «запусти этот инструмент, что-то сделай с его выводом, запусти другой инструмент» или «реализуй функцию A, реализуй тесты для функции A, реализуй функцию B, …».
- Одни части этой работы требуют сложных рассуждений, другие — нет.
- Агенты
почтихороши в рассуждениях, но плохо держат в голове весь процесс: что уже сделали, что нужно сделать, в каком порядке, etc. - Поэтому логично отделить рассуждение от контроля потока исполнения — пусть агенты сосредоточатся на том, в чём они хороши, а поток можно отдать традиционным инструментам автоматизации.
Donna исполняет сценарии как детерминированные конечные автоматы, поэтому агент может сосредоточиться на рассуждении, генерации кода и другой агентной работе.
Rust — язык, на который переписывают
Rust медленно, но неотвратимо, перерабатывает кодовую базу человечества.
Лет 5 назад я изучал документацию Rust и решил, что Rust мне не нравится.
В прошлом году мне потребовалось прототипировать игровую логику и я выбрал для этого Rust, так как ничего лучше не нашёл: Zig выглядел сырым, а C++ с каждым стандартом становится всё мертвее сложнее и сложнее.
В итоге у меня накопилось 10 страниц заметок, которые неожиданным образом ужались в очень компактное утверждение в заголовке. И если вам лень читать дальше, то это похвала, а не критика.
Однако, я всё ещё придерживаюсь своего мнения из предыдущего поста:
Хороший инструмент не ограничивает своего пользователя, поскольку разработчик инструмента никогда не предугадает все варианты использования.
Согласно моим представлениям о прекрасном о том, как работают технологии, вероятность успеха языка программирования, построенного на принципах Rust, стремится к нулю. Однако de facto ситуация совершенно противоположная — Rust стремительно набирает популярность и поработав с ним, я признаю, что это хороший и мощный инструмент. Но, ё-моё, неправильный, ну кто ж так делает-то.
На мой взгляд, успех Rust — это следствие двух факторов:
- Огромного профессионализма и опыта его создателей и core-команды.
- Зрелости индустрии разработки софта.
Я попробую кратко описать главное концептуальное отличие Rust от других языков, почему оно одновременно является его силой и слабостью и почему уже несколько лет идёт волна переписывания всего на Rust.
Этот пост основан на строго субъективном опыте
Я использовал Rust только год; для прототипирования и экспериментирования; в геймдеве.
Соответственно, я никаким образом не могу претендовать на экспертность в языке и иметь сколь-нибудь объективное мнение на его счёт.
Например, некоторые сложности, которые я испытывал, могли быть вызваны тем, что я одгновременно прототипировал и учил язык. То есть следствием моего выбора, а не свойств языка.
В то же время у меня достаточно опыта разработки, чтобы экстраполировать этот год на более общие случаи и сформировать своё субъективное мнение о Rust. Этим я в этом эссе и займусь.
Организуем стартап? Впишусь в проект

Life is like a hurricane here in Ham-burg…
Как вы можете знать, я заканчиваю творческий отпуск. Чем буду заниматься дальше, пока неизвестно, но у меня накопился список возможных проектов, которые мне очень интересны. По этим проектам я готов обсуждать партнёрство прямо сейчас.
Если вы молодой стартап или только собираетесь его создавать, то я хорошо впишусь в роль CTO / технического Co-Founder (менеджерство и продуктовую часть тоже могу взять на себя). Если вы более зрелая компания, начинающая новый проект, то могу его вести под ролью с любым названием, которое вам будет по душе.
Если вы следите за моим блогом, то уже имеете представление обо мне. Но на всякий случай вот моё CV. У меня 19 лет опыта в разработке софта: от геймдева на C++ до платёжных бэкендов на Python, от гаражной независимой разработки до крупных проектов.
Для удобства я разбил интересные мне проекты на несколько групп:
- LLM-лопаты и лопаты для LLM.
- Virtual characters, virtual influencers.
- Gamedev.
Сходил в гости в подкаст «Две Столицы — Уютный IT Подкаст»
Запись подкаста на YouTube
Приятно пообщались про агентов, LLM и прочие ИИ штуки.