Взгляд на управление: Цикл проверки гипотез en ru

Цикл обратной связи (c) Босх и ChatGPT
Обычно мы предполагаем, что если у нашего продукта будут такие-то и такие-то свойства, то люди будут готовы платить за него такие-то и такие-то деньги.
Иногда мы делаем предположения в явном виде:
Если перекрасить вывеску в красный и подсветить, посещаемость ресторана в вечернее время увеличится на 10%.
иногда — в неявном:
У меня будет самый крутой парк развлечений на Луне с блэкджеком и инопланетянками.
но, рискну предположить, что вообще без предположений не обходится никогда.
Эти предположения мы называем гипотезами.
Основываясь на гипотезах, мы изменяем продукт, измеряем результаты, после чего решаем какие гипотезы верны, какие нет. Верные гипотезы остаются в нашей картине мира и продукте, от неверных мы отказываемся. После чего формируем новые гипотезы и повторяем цикл.
Этот цикл крутится вечно, пока существует продукт и является частным случаем цикла обратной связи.
Существует огромное количество литературы об этом цикле, его запуске и прочих нюансах. Лучшие практики собраны в наборы на любой вкус: от заумной системной инженерии до Lean Startup и Agile. Сам цикл называется, наверное, десятками аббревиатур: PDCA, OODA, DMAIC, 8D — не счесть их — каждый уважающий себя гуру-консультант с книгой добавляет новую.
Запуск цикла обратной связи критически важен, без него совсем никуда — смерть, смерть, гроб для вашего продукта, как и для любого другого начинания.
Но кроме самого факта запуска важно и что конкретно вы в этом цикле делаете.
Этот вопрос в литературе раскрыт не так хорошо, как хотелось бы. Одно дело — рассматривать упрощённые кейсы в книгах. Другое — пытаться в реальном времени направлять реальный продукт со всеми его переусложнённостью, непрозрачностью, запутанностью, задержками, отсутствием данных и так далее.
Поэтому в этом очень длинном эссе я попробую глубже копнуть один из конкретных этапов цикла обратной связи, которому уделено незаслуженно мало внимания — синтез гипотез.
Ещё одно описание цикла обратной связи
Не буду отставать от трендов. Чтобы далее мы были с вами на одной волне, вот мой вариант цикла:
- Сбор данных — собираем данные о текущем состоянии системы и её окружения.
- Анализ — наводим порядок в данных: структурируем, определяем закономерности, разделяем на группы — выявляем ортогональные свойства системы, которыми мы сможем оперировать на следующем этапе.
- Синтез — формируем гипотезы, опираясь на выявленные свойства.
- Воплощение — производим изменения в системе на основе гипотез.
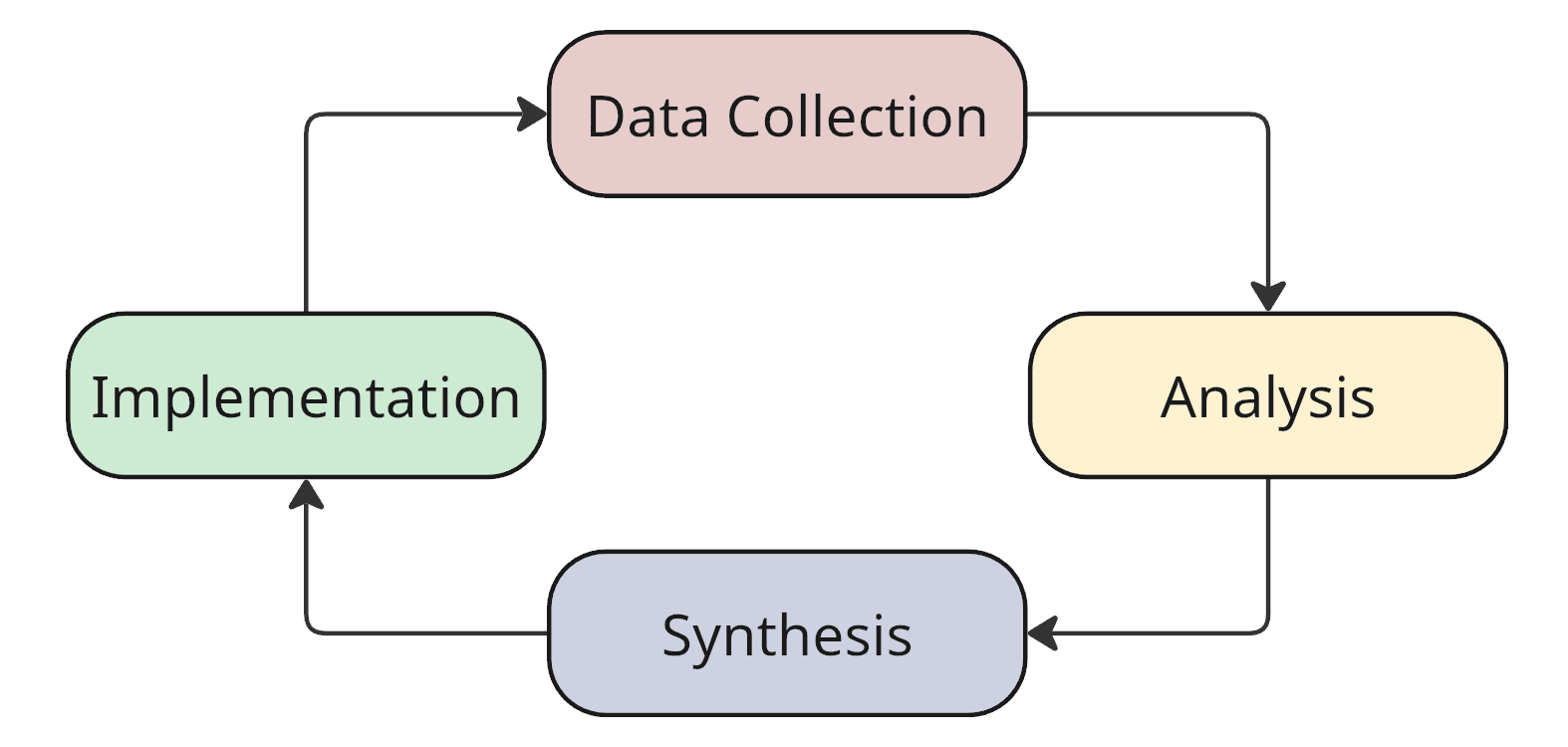
Простой цикл обратной связи
Этапы сбора данных и анализа хорошо изучены и описаны. Особенно для стартапов.
Этап воплощения — (социо)инженерная задача. Если вы уже решили, что конкретно нужно сделать/достичь, то в большинстве случаев далее нет концептуальной сложности, только техническая: как реализовать, как запустить, как оценить результаты при доступных ресурсах.
А вот с синтезом дела обстоят сложнее. Часто он предполагается само-собой разумеющимся, очевидным: видишь данные после анализа и гипотезы сами собой в голове появляются. По нему тоже есть литература, но знакомится с ней, по моим ощущениям, куда меньшее количество людей.
Синтез гипотез
Спорить, что у людей в головах появляются мысли, я, конечно, не буду — это общеизвестный факт. Однако, спонтанные идеи — это не лучшее, что мы можем использовать. Кто работал на исполнительских позициях, когда идеи спускаются сверху, тот поймёт о чём я :-)
Для формирования гипотез разработано заметное количество практических подходов: от предопределённого списка эвристик в ТРИЗ до морфологического анализа и оптимизаций над ним. Я даже как-то делал инструмент для морфологического анализа.
Сравнительный анализ этих подходов мог бы стать отличной темой для эссе, но оставим его на будущее.
В этом тексте я попробую посмотреть на синтез гипотез не «снизу» — от конкретных практик, а «сверху» — от общих свойств продуктов и гипотез. Мы обсудим о каких свойствах продукта выгоднее формировать гипотезы и какие общие подходы к поиску гипотез существуют.
В конце эссе мы придём к алгоритму поиска гипотез, который должен заметно улучшать качество гипотез о продукте, а значит и качество самого продукта.
Вложенность систем и циклов обратной связи
Формально говоря, любая сложна система, включая любой продукт, — это множество вложеных друг в друга (под)систем, в каждой из которых может идти свой цикл обратной связи. Более того, каждый этап цикла может содержать аналогичный «дочерний» цикл, заточенный на оптимизацию конкретного этапа родительского цикла.
Например:
- Отдел маркетинга может проверять подходы к размещению рекламы.
- Разработка может пробовать альтернативные технологии.
- Этап сбора данных о рынке может оптимизироваться через проверку гипотез о лучших источника информации.
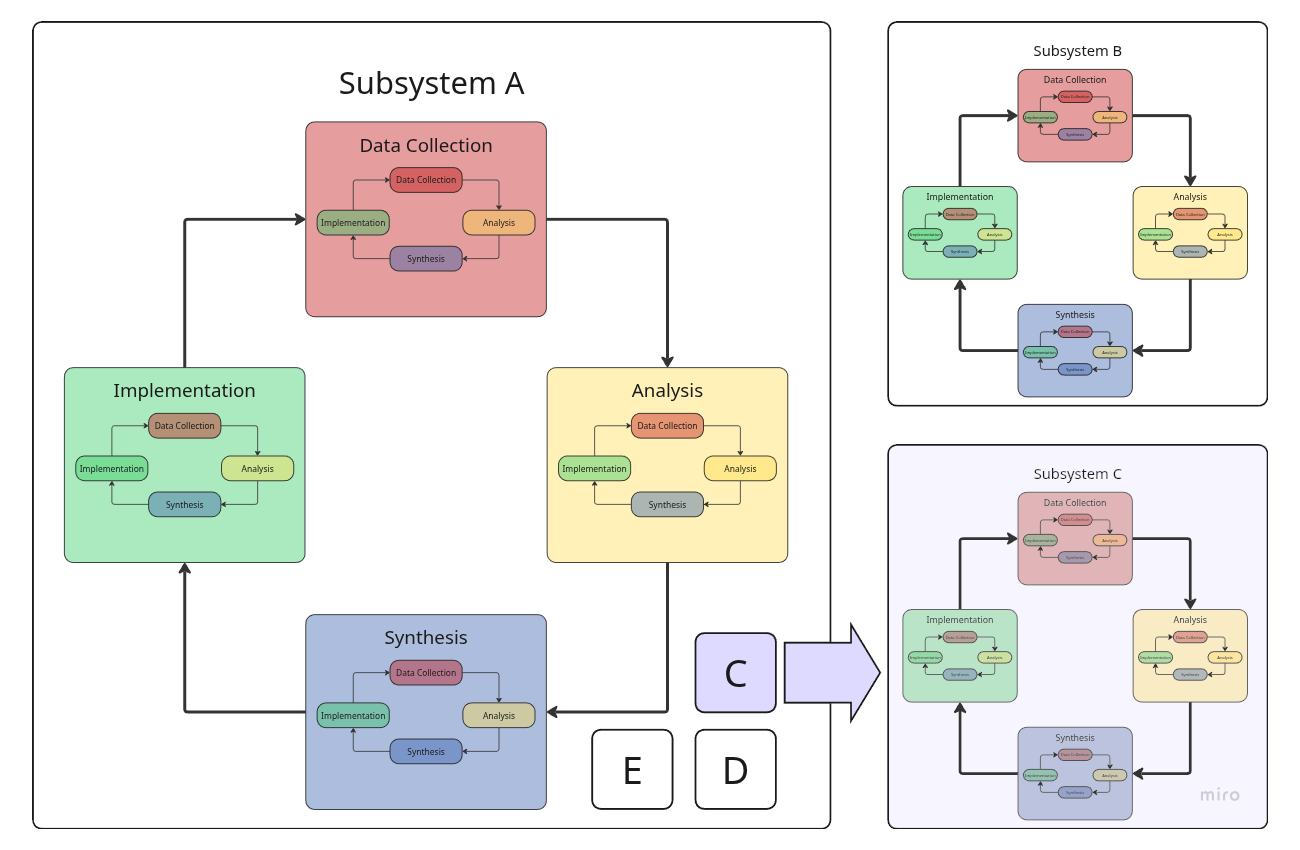
Как всё работает в реальности
Я опущу эти нюансы и буду говорить о продукте как о цельной системе и о единственном цикле обратной связи. По двум причинам.
Во-первых, так будет проще и понятнее. Чрезмерная детализация усложнит текст, но не принесёт новой информации.
Во-вторых, есть принципиальная разница между окружением, в котором существует конечный продукт, и окружением, в котором существуют его подсистемы. Окружение продукта — это реальный мир — мы его не конкролируем и плохо понимаем. Окружение компонента — это среда нашей компании — мы её контролируем (!) и понимаем значительно лучше.
Поэтому формулировать гипотезы о конечном продукте значительно сложнее, чем о его подсистемах. Именно этой сложности и посвящён текст.
В-третьих, рулить следует именно конечным продуктом, а не его компонентами. Мы частично обсуждали это в предыдущем посте и продолжим обсуждать в этом.
Гипотезы берутся из моделей
У каждого из нас в голове есть представление о том, как работает окружающий мир и штуки в нём. Эти представления называются ментальными моделями.
Мы можем применять модели к разным ситуациям и смотреть «что будет если»:
- Если я буду переходить улицу на красный свет светофора, меня собьёт машина.
- Если я буду переходить улицу на красный свет светофора в лесу в новогоднюю ночь, то скорее всего меня никто не собьёт, так как машин не будет.
Если вам кажется, что вы не пользуетесь ментальными моделями, то вам только кажется. Даже интуиция — это обращение к скрытым моделям реальности в глубине нашего мозга, которые мы не осознаём.
Модели могут быть не только ментальными:
- Электронные таблицы — для количественных метрик — посчитать EBITDA, покрутить воронку продаж, etc.
- Текстовые документы, mind maps и прочее — для штук, которые сложно выразить в числах.
- Хитровывернутыетые алгоритмические штуки — если нужна особая точность или глубина.
- Отчёты от авторитетных источников — когда мы доверяем другим больше чем себе.
- …
Не счесть всех возможных вариантов. Для нужд эссе не важно какие именно модели вы используете (их больше одной, правда?), важно как вы их используете.
Мы можем проверять как поведёт себя модель продукта при изменении его свойств в ней. Если поведение модели нам интресно, то одна гипотеза найдена: «При таком-то изменении свойств продукта он поведёт себя таким-то образом». Мы можем попробовать применить её к реальности и посмотреть что будет.
Самые храбрые из нас, конечно, не проверяют модели, а сразу изменяют реальный продукт — обратная связь ведь быстрее :-) Но я всё-таки рекомендую опираться на достижения нашей цивилизации, одним из которых, без сомнения, является здравый смысл.
О детализации гипотез
Будем честны, большинство людей редко формулирует гипотезы в сколь-нибудь явном виде. Куда чаще гипотеза звучит так:
У нас что-нибудь увеличится, если мы сделаем что-нибудь ненужное.
или
Зуб даю, все наши клиенты этого хотят, я даже их спрашивать о такой банальщине не буду.
Часто сложно добиться хотя бы чёткой качественной формулировки вроде
Мы увеличим удержание пользователей, если сделаем фичу X.
Ещё реже гипотезы формируются с явными числовыми предсказаниями. Большинство людей не понимает зачем это делать и не верит, что это возможно.
В то же время, максимально чётко формулировать гипотезу перед реализацией изменений и измерением результатов — это, извините за тавтологию, максимально необходимый шаг.
Во-первых, это требование вытекает из критериев фальсифицируемости Поппера — одной из базовых концепций на которой мы строим науку последние лет 100. Инженерию и бизнес мы, кстати, тоже на них строим, но не все об этом задумываются. Один из будущих постов я надеюсь посвятить теме близости науки и софтостроения.
Подход «Сделаем без предсказания, потом посмотрим на результаты и сделаем выводы» системно не работает. Он приводит к неверным долгосрочным выводам, потери важной информации. Этот подход настолько вреден, что учёные даже придумали для него специальный термин — HARKing — Hypothesizing After the Results are Known — чтобы шеймить тех, кто им пользуется.
Во-вторых, чем точнее вы сформулировали гипотезу, чем большему вы научитесь после её проверки.
Понятное дело, нет гарантированного эффективного способа вытащить из моделей точные предсказания, особенно числовые из наших голов. В конце-концов все модели — это упрощение реальности, следовательно — потеря точности. Но это не значит, что мы не должны пытаться это сделать. Чем более детальное (и обоснованное) предсказание мы делаем, тем более точно и детально мы сможем оценить его ошибку, тем точнее мы скорректируем работу своих моделей после проверки этого предсказания.
В-третьих, количественная формулировка полезна для сравнения гипотез. А без сравнения как выбирать что делать в первую очередь?
Пространство поиска гипотез
Независимо от формы, модель вашего продукта — это сеть причинно-следственных связей, которые определяют что на что влияет. Каждый узел в этой сети — это какое-то свойство продукта или его подсистемы. Вспомните, когда мы смотрели на продукт с разных точек зрения, мы обсуждали, что продукт — это не только то, что видит пользователь, но и команда, процессы, побочные артефакты — всё, что участвует в предоставлении пользователю желаемого.
Если мы поменяем один из узлов (свойство продукта), то изменения начнут распространяться по сети в двух направлениях:
- По цепочке причинности вперёд: к каким последствиям приведёт изменение узла — какие другие узлы изменятся и как.
- По цепочке причинности назад: какие другие узлы мы должны изменить, чтобы получить изменение в этом узле.
Экспериментировать можно с любым узлом сети, даже с несколькими одновременно. От того какой узел мы меняем, будет зависеть картина распространения изменений.
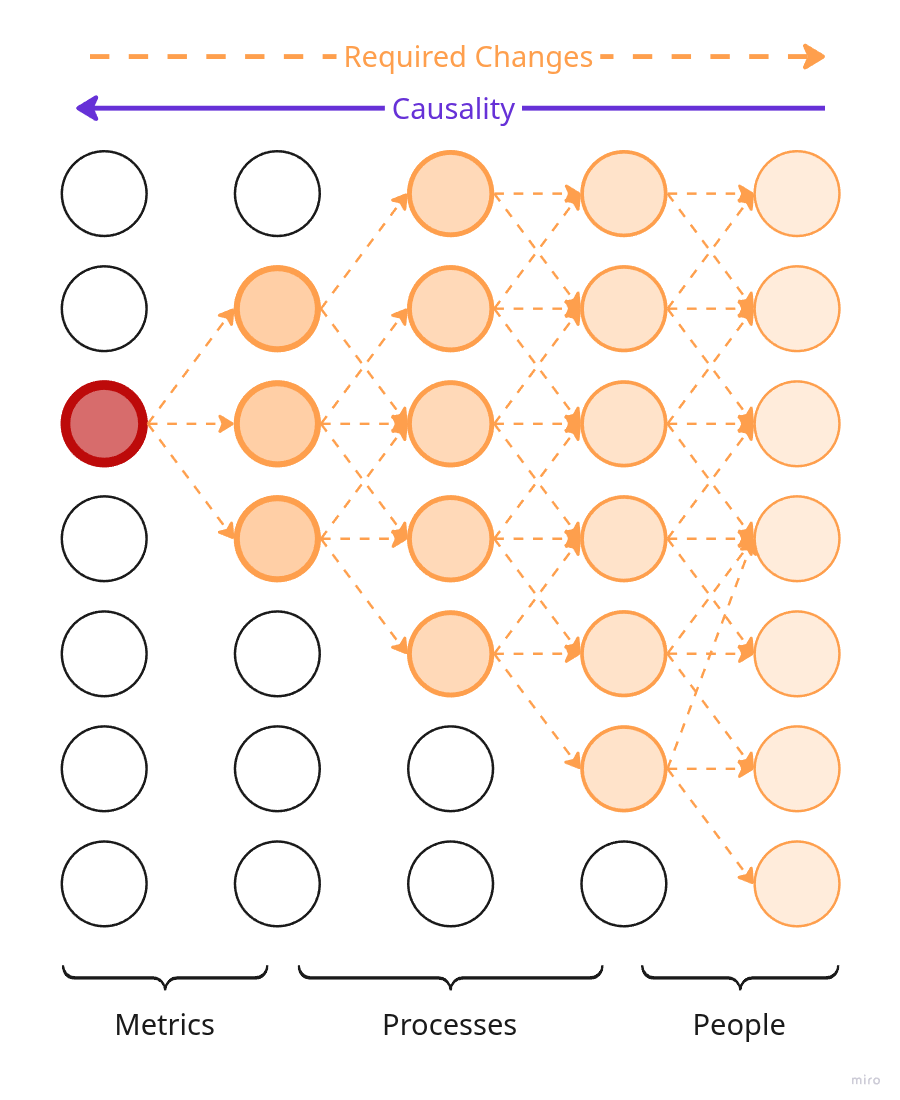
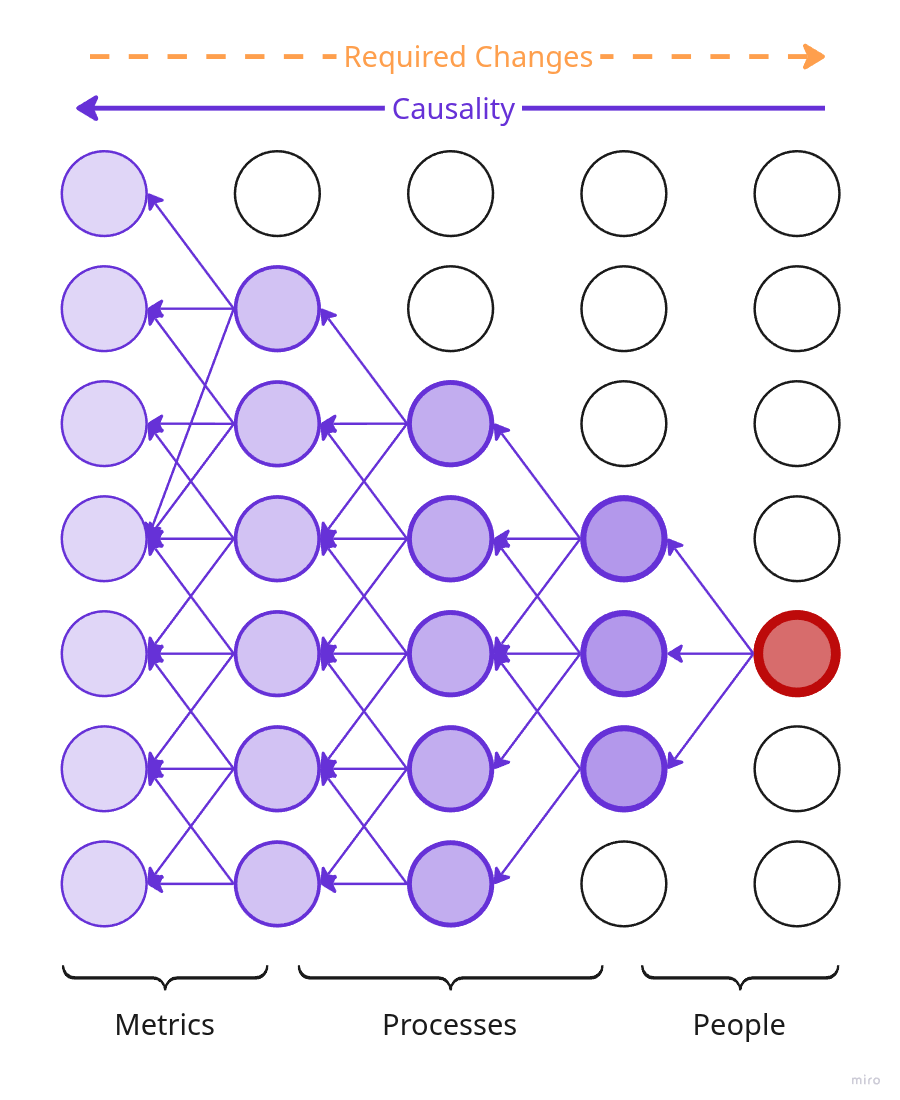
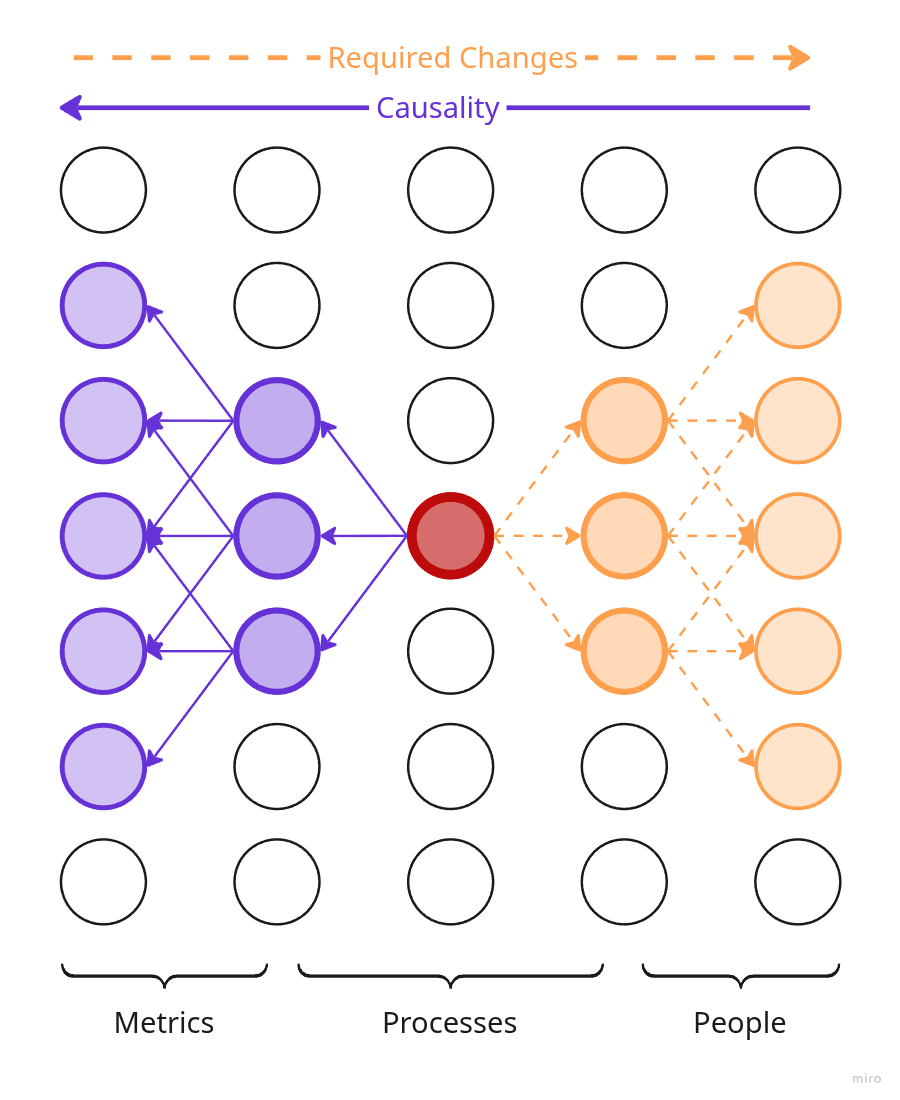
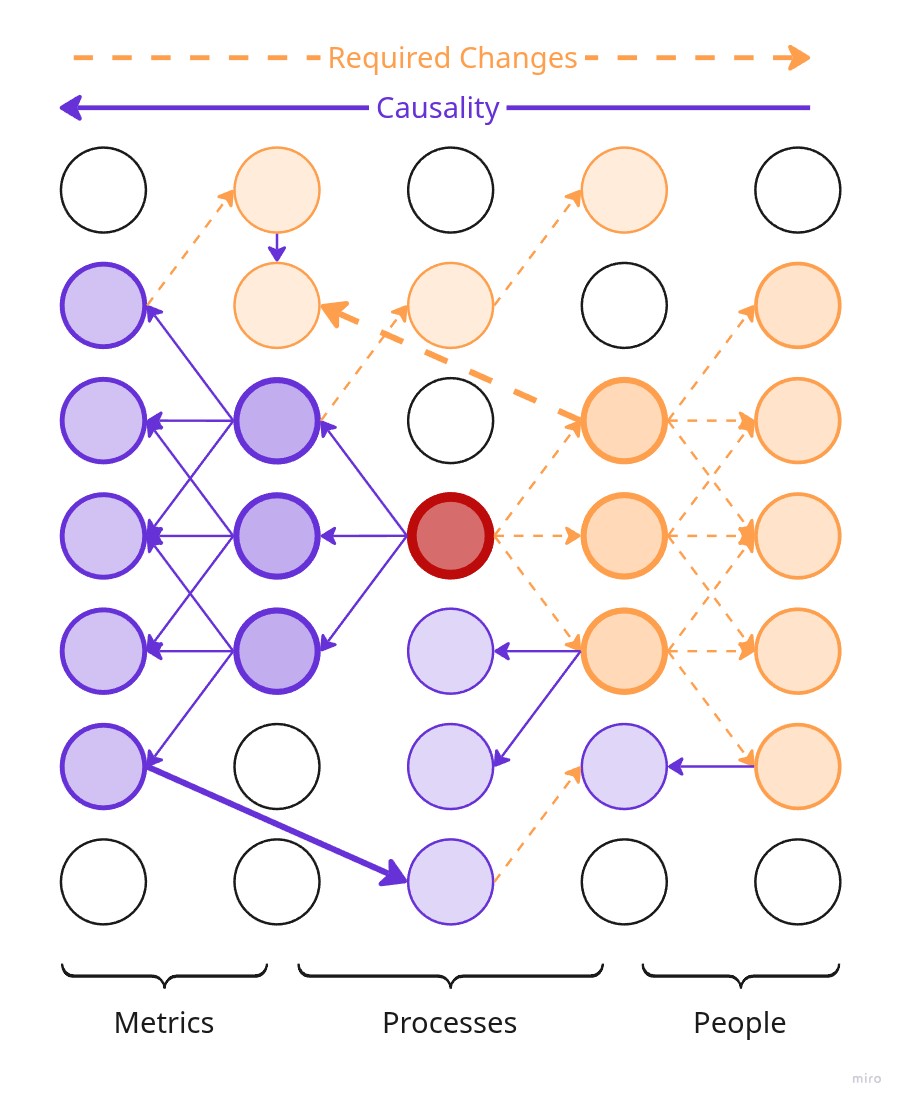
Упрощённая иллюстрация сети причинности продукта.
В реальности, конечно, всё куда запутанней: куча обратных и двунаправленных связей, типов узлов значительно больше и вообще непонятно что происходит — примерно как на четвёртой картинке.
Для примера:
- Если мы хотим изменить конечное свойство продукта, например, частоту релизов, мы должны изменить компоненты, от которых она зависит: рабочие процессы, команду, может быть технологии. В итоге изменение одного конечного свойства может потребовать изменений во многих узлах цепочки причинности, которые рассположены перед ним.
- Если мы планируем уволить человека из команды, то вызванные этим изменения распространятся вперёд по цепочкам причинности и могут затронуть сразу множество конечных свойств продукта.
- Мы можем менять и что-то в середине сети, например, какой-то рабочий процесс. В этом случае изменения и требуемые изменения начнут распространяться в обе стороны. Так как расстояние до начальных и конечных узлов меньше, то оба крыла изменений будут уже.
О «конечных» и «начальных» свойствах продукта
Для удобства я далее буду говорить о некоторых свойствах продукта как о «конечных» и «начальных». Понимать их надо именно в контексте сети причинности:
- конечные свойства — это свойства, которые в большей степени являются следствиями изменений в других узлах сети, чем причиной изменений в них. Например, частота релизов — это следствие работы команды, процессов, технологий и прочего, но на внутреннее состояние продукта влияет слабо.
- начальные свойства — это свойства, которые в большей степени являются причиной изменений в других узлах сети, чем следствием изменений в них. Например, конкретные члены команды, обычно, влияют на огромное количество конечных свойств продукта, но сами не зависят от них.
Поскольку продукт — это сложная хаотичная система, не буду чрезмерно формализировать эти понятия, например, утверждать, что конечные свойства вообще не должны ни на что влиять. Для нужд этого эссе достаточно приведённого выше нечёткого определения.
Чем прозорливее мы выбираем узлы для экспериментов с моделями, тем лучше будут наши гипотезы, тем быстрее и эффективнее будут происходить изменения, тем успешнее будет наш продукт.
Отсюда возникает резонный вопрос: какова лучшая стратегия поиска гипотез?
Тривиальные стратегии поиска гипотез
- Полный перебор — садимся и методчично думаем что будет, если изменить каждый из возможных узлов в модели продукта.
- Случайный поиск — в высшем обществе «метод научного тыка» — пробуем крутить случайные параметры модели, надеясь что повезёт.
- Использование
интуицииопыта — почти как случайный поиск, но пытаемся использовать мозг, чтобы не тратить время на совсем уж бессмысленные варианты.
Очевидно, полный перебор и случайный поиск — не самые эффективные стратегии, так как разработка любого продукта — вещь сложная и многогранная:
- Перебор всех изменений изменений займёт слишком много времени.
- Случайный поиск будет малорезультативен, так как потенциальных негативных и нейтральных изменений на порядки больше, чем позитивных. Всё как в биологии.
Против интуиции и опыта ничего не имею, сам пользуюсь, иногда работают :-) Проблем у них несколько:
- Не у всех они есть.
- Область их позитивного использования обычно уже, чем кажется. У вас может быть опыт в одной или паре очень конкретных областей, но вряд ли будет достаточный опыт во всех областях, которые существенны для продукта.
Опыт и интуиция хорошо работают для «базовых» изменений вроде «любому состоявшемуся специалисту в X понятно, что надо делать Y если Z». Следование таким гипотезам поможет сделать средний продукт, может быть чуть выше среднего, но вы упустите огромное количество более эффективных локальных изменений, которые просачаться через крупные ячейки сита интуиции и опыта.
Могут ли быть другие стратегии, более эффективные?
Конечно могут. Самое простое, что мы можем сделать — это сузить область поиска возможных гипотез. Для этого давайте подумаем какого рода гипотезы будут удобнее для управления продуктом. Я уже частично касался этого вопроса в предыдущем посте.
Эвристики об удобных продуктовых гипотезах
Гипотеза, по сути, это утверждение «если мы повернём рычаги X, Y, Z то в продукте произойдут изменения A, B, C, D, E».
Очевидно, что одними рычагами управлять удобнее, чем другими, следовательно, мы можем очертить область гипотез так, чтобы в неё попадали только гипотезы с удобными рычагами.
Для этого воспользуемся рядом эвристик, надеюсь, очевидных :-)
Чем больше рычагов нам необходимо одновременно двигать, тем сложнее это делать. Поэтому гипотезы, в идеале, должны быть про влияние на одно свойство/компонент.
Конечные свойства продукта чаще важнее для нас, чем прочие. В конце концов обычно ради них вся движуха и затевается.
«Конечные» vs «внешние» свойства
Кроме конечных и начальных свойств, если смотреть на продукт, как на целое, можно выделять внешние и внутренние свойства.
Внешние свойства — это то, как наш продукт выглядит из вне: графический интерпейс, заработанные и потреченные нами деньги, метрики поведений пользователей.
Внутренние свойства — это то, как наш продукт устроен внутри: культура компании, наши процессы, особенности коллег.
В былые времена можно было поставить достаточно сильный знак равенства между конечными и внешними свойствами, поскольку во главу угла ставилась максимальная внешняя эффективность продукта/компании.
Не люблю цветовую дифференциацию штанов, но раз уж она популярна нынче…
Утверждение о безусловной важности внешних свойств справедливо для оранжевых организаций, которые ориентированы на максимальную внешнюю эффективность. Также они справедливы для типов организаций, которые были перед оранжевыми.
Для набирающего силу нового типа организаций — бирюзовых — некоторые внутрении свойства могут быть так же важны как внешние, например, культура команды, или количество высаженных деревьев, или среднее время жизни людей в обслуживаемом медицинской организацией квартале.
В нашей логике такие внутрениие свойства также являются конечными, что соответствует их логике «точек схождения усилий компании». Соответственно, далее я говорю и про них в том числе.
Мы хотим управлять продуктом измеримо, желательно с помощью количественных метрик, которые по сути являются количественными свойствами продукта. Это просто удобнее. Нам необходимо понимать, что мы сейчас находимся в состоянии A с такими-то свойствами, если мы изменим что-то, то должны придти в состояние B с такими-то свойствами за такое-то время.
Чем длиннее цепочка причинно-следственных связей между точкой приложения усилий и управляемой штукой, тем сложнее управлять, тем больше будет расхождение реальных изменений с прогнозируемыми. Иными словами, если нас интересуют конкретные изменения в узле X, то нам следует стараться им управлять через сам узел X или через его ближашее причинное окружение.
Единичные крупные изменения работают чётче и оказывают более понятное влияние, чем множественные мелкие. Множественные мелкие изменения рождают сложную сеть зависимостей и, как следствие, комплексный поток неочевидных следствий, который сложно отслеживать и, тем более, направлять без ошибок. В этом контексте мне нравится совет Сида Мейра — легендарного дизайнера игр, создателя серии Civilization — про изменение параметров игрового баланса:
Double it or cut it in half. You are more wrong than you think.
Набрасываем стратегию поиска гипотез
Опираясь на эвристики, мы можем утверждать, что нас интересуют гипотезы об измеримом изменении единичных конечных свойств продукта через измеримые единичные изменения в их ближайшем причинном окружении. Например, всё тот же случай с уменьшением процента отказов от подписки через ускорение работы поддержки.
Соотнесём это утверждение с эвристиками:
- Мы стремимся использовать один рычаг для влияния на небольшое множество свойств.
- Мы стремимся делать гипотезы об изменении конечных свойств продукта.
- Мы стремимся делать гипотезы об измеримом влиянии на измеримые свойства, поскольку конечные свойства продукта измеримы лучше.
- Мы стремимся избегать длинных цепочек причинно-следственных связей, для чего манипулируем свойствами продукта из ближайшего причинного окружения целевого свойства. Подробнее про длинные причинно-следственные цепочки и распространение изменений будет ниже.
- Мы стремимся минимизировать количество точек изменения.
То есть мы управляем продуктом как единым целым, а не пытаемся рулить каждой его частью отдельно — это соотносится с выводами из предыдущего поста.
Аналогия с управлением автомобилем
Интерфейс управления автомобилем заточен на то, чтобы водитель управлял машиной как единым целым.
- Водитель может ускорять его, замедлять, оценивать положение в пространстве через зеркала, и так далее.
- Водитель не управляет каждым колесом отдельно, не управляет каждой свечой зажигания, не регулирует давление в шинах в реальном времени и так далее.
Есть исключения в виде спортивных автомобилей, трюковых и прочих специализированных машин, но в подавляющем большинстве случаев управление автомобилем — это управление единым целым.
Резкий рост сложности управления при увеличении его глубины можно заметить даже на примере коробки передач: переходить с автоматической на механическую довольно сложно, хотя сам автомобиль концептуально остаётся тем же самым.
Распространение изменений
Найти рычаг переключение которого приведёт к изменению единственного свойства продукта — задача непосильная. Как мы обсуждали в предыдущем посте, продукт — это сильно связанная хаотическая система — небольшое изменение неизбежно повлечёт распространение изменений по всей системе.
Поэтому суть хорошей гипотезы не в том , чтобы найти идеальное точечное изменение `X → Y; и не в том, чтобы учесть все возможные последствия, все возможные пути распространения изменений.
Суть хорошей гипотезы в том, чтобы локализировать и максимально точно предсказать существенные для нас изменения. Именно тогда мы сможем эффективно использовать предсказание: изменить продукт понятным нам образом и получить необходимый нам результат. Обратите внимание, под существенными изменениями я понимаю не только положительные, но и отрицательные.
Например, утрируя:
Если мы сделаем фичу X, то у нас вырастет LTV на 10%, DAU на 30%, мы потеряем 1% пользователей (старые ПК), а остальные показатели, как мы ожидаем, будут случайно колебаться на небольшие значения.
Все остальные «побочные» изменения, которые неизбежно распространяются дельше и глубже, мы можем считать следствиями жизнедеятельности продукта и работать с ними в рабочем порядке. Иногда это означает какие-то стандартные рутинные действия. Иногда мы будем пропускать существенные негативные следствия и у нас будет появляться новая крупная проблема — все ошибаются — это нормальный процесс, важны не факты ошибок, а их частота.
Метрики продукта как рычаги и целевые показатели
Поскольку мы:
- Заинтересованы в управлении конечными свойствами продукта через их ближайшее причинное окружение.
- Рассматриваем продукт как единое целое, а не набор отдельных частей.
- Хотим управлять продуктом через измеримые свойства.
Можно утверждать, что нам интересно манипулировать метриками поведения продукта во внешней среде — количественным измерением того как он взаимодействует с ней. Обычно это метрики взаимодействия с пользователями, клиентами, потоки ресурсов в продукт и из него, etc.
Причём метрики могут быть как нашими целевыми показателями, так и рычагами с помощью которых мы пытаемся влиять на них.
Давайте наконец обсудим что есть что.
Другие термины
Амазон использует термины input/output metrics примерно в таком же смысле как рычаги и целевые показатели в этом тексте.
Также я встречал отсылки на leading/lagging indicators, как на аналогичные по значению термины, но, на мой взгляд, они про другое.
Целевые показатели определяются нашим видением продукта, стратегией его развития и логикой его иммунной системы; они отображают наши цели, ценности и риски. Это что-то, что мы безусловно хотим достичь, увеличивать или предотвращать.
Например, если мы делаем MMORPG, одним из наших стратегических показателей будет Life Time пользователей, оно для нас критично даже в отрыве от прямых доходов, так как ценность MMORPG для игрока определяется её сообществом и нам важно наличие активных игроков, даже если некоторые из них приносят недостаточно прямого дохода. С другой стороны, если мы делаем гиперказуальную однодневку, то LT для нас имеет значительно меньший приоритет — мы знаем, что эта метрика будет низкой — это часть нашей стратегии.
Риски тоже могут порождать целевые показатели. Например, мы можем хотеть чтобы время исправления уязвимостей не превышало установленный барьер. Эта метрика также не относится непосредственно к прибыли, но она может быть частью наших гарантий для пользователей.
Мы не можем изменить целевые показатели напрямую, но можем влиять на них через сеть причинно-следственных связей, которые связывают их с рычагами.
North Star Metrics
Целевые показатели семантически близки к North Star Metrics.
Термин этот пока не до конца устаялся, но значит что-то вроде «метрики, которые наиболее хорошо предсказывают/характеризуют долгосрочный успех компании».
Предлагаю не разбираться одно это и тоже с нашими целевыми показателями или нет, достаточно, что это концептуально близкая штука и по ним есть интересные посты в сети.
Рычаги — это метрики, на которые мы можем влиять непосредственно, они находятся под прямым контролем команды.
Например: скорость загрузки страницы сайта, время ответа поддержки, количество багов в релизе, свойства пользовательского интерфейса (выраженная количественно, например, в скорости выполнения типичных задач).
Метрики рычагов, часто могут становиться KPI.
Основная разница между рычагами и целевыми показателями в том, что целевые показатели, обычно известны, а рычаги нужно активно искать.
Мы ищем рычаги разворачивая цепочку причинности от целевых показателей к узлам, которые мы можем контролировать предсказуемым и понятным образом.
Мир сложная штука и все ошибаются, поэтому важно не только найти «какие-то рычаги», но и ретроспективно анализировать влияние их измерений на целевые показатели — проверять сработала гипотеза или нет. Если гипотеза не сработала, велика вероятность, что мы неправильно оценили влияние рычага на целевой показатель, либо неверно сформулировали саму метрику.
Пример поиска правильной метрики от Amazon
К сожалению я пока не добрался до Working Backwards — книги о рабочей культуре Amazon, но хочу привести показательный пример из неё. Сам пример взят из поста Goodhart's Law Isn't as Useful as You Might Think (у меня есть заметки по его мотивам).
В какой-то момент Amazon решил, что хорошей метрикой-рычагом будет «количество новых страниц с информацией о товарах». Метрика стала KPI.
Вскоре обнаружилось, что команды начали создавать огромное количество страниц с товарами, которые не пользовались спросом — это совершенно не влияло на рост доходов.
Пришлось запускать эволюционную оптимизацию метрики, которая в итоге прошла через ряд итераций:
- Количество страниц с информацией о товарах.
- Количество просмотров страниц с информацией о товарах.
- Процент просмотров страниц товаров с товарами на складе.
- Процент просмотров страниц товаров с товарами на складе и готовыми быть доставленными за 1-2 дня.
Последний вариант оказался достаточно скоррелирован с ростом доходов и стал рычагом, который команды начали использовать для влияния на продукт.
Алгоритм поиска гипотез
Как итог наших рассуждений, мы можем сформулировать следующий алгоритм поиска гипотез:
- Определяем наши целевые показатели (North Star Metrics).
- Рисуем карту причинности, которая связывает их с «гипотетическими» метриками-рычагами. Хорошее объяснение можно найти у Amazon.
- Анализируем каждый рычаг:
- Как он влияет на целевые показатели?
- Какое существенное влияние он может оказывать на другие свойства продукта?
- Выбираем удобные нам рычаги и формулируем гипотезы вида «Если мы достигнем увеличения метрики X (на N%), то целевой показатель Y вырастет (на M%) за T времени».
- Самые интересные гипотезы берём в работу.
- После реализации гипотез, анализируем новое поведение продукта, сравниваем с ожидаемым.
- Если гипотеза не работает:
- или пробуем улучшить её рычаговую метрику — возвращаемся на этап 2;
- или отказываемся от гипотезы — откатываем изменения или замораживаем их развитие.
- Если гипотеза работает, продолжаем ей следовать.
Микроменеджмент как следствие длинных цепочек причинности
Не забываем ограничивать длинну цепочек между рычагом и целевой метрикой — не стоит заниматься мироменеджментом.
Например, не стоит пытаться управлять выручкой через найм или увольнения людей. Увольнения могут быть частью действий по воплощению гипотезы, но не частью самой гипотезы.
Плохая гипотеза:
Мы увеличим выручку на 10% за 3 месяца, если наймём 5 новых разработчиков.
Хорошая цепочка гипотез:
- «Мы увеличим выручку на 10% за 3 месяца, если реализуем фичу X» => мы запускаем «проект X» — создаём подсистему «проект X» о которой мы тоже можем выдвигать гипотезы.
- «Чтобы реализовать «проект X» нам необходима команда из 5 человек» => мы запускаем «активность по поиску 5 человек» — создаём ещё одну подсистему со своими гипотезами.
- «Нанять 5 человек в текущей ситуации выгоднее, чем снять 5 человек с других задач» => мы запускаем «активность по найму 5 человек» — ещё более локализованная активность в которой тоже может быть свой цикл обратной связи.
- …
Гипотезы с короткой цепочкой причинности хороши ещё и тем, что каждая из них создаёт развилку в планировании — точку поиска возможностей, точку возможного манёвра (если что-то пойдёт не так).
Если мы последуем за плохой гипотезой и найм 5 разработчиков не сработает, то мы откатимся в самое начало. Если последуем цепочке хороших гипотез, то мы только отойдём на шаг назад.
Заметки на полях
Есть несколько вещей, на которые я хотел бы дополнительно обратить внимание.
Точное следование формальным процессам — это хорошо, но много хорошего тоже вредно.
Не надо терять голову и ставить формальности перед здравым смыслом. Чем меньше компания/команда — тем большую долю ресурсов будут съедать дотошный поиск гипотез, сбор метрик, поддержка дашбордов и прочее — тем меньше времени останется на саму работу. Всегда полезно искать баланс и разумно срезать углы.
Объективно измерять взаимодействие продукта со средой значительно легче, чем его внутреннее состояние. Не меряйте культуру и людей количественно, особенно с помощью прямолинейных метрик — это всегда выйдет против вас. В прошлом посте мы говорили про важность самоорганизации; формальные метрики и KPI — её главный враг. Если вы хотите чтобы ваши коллеги перестали общаться, учиться и помогать друг другу — поставьте перед ними количественное KPI, желательно мешающие друг другу.
Этот пост является частью серии
- Следующий пост: Что почитать, когда и почему
- Предыдущий пост: Точки зрения на продукт
Читать далее
- Два года пишем RFC — статистика
- Следующий фронтир геймдизайна
- World Builders 2023: Считаем бизнес-план для игры в Steam
- Об ИТ, прогрессе и нехватке спецов
- О книге «Сильнейшие»
- Почему разработчики не сделают эту простую штуку?
- Жизнь и работа с ошибками
- Монополизация машинного обучения
- Жизнь и работа с моделями
- О книге «Изобретение науки»