Интересный случай оптимизации извлечения данных с помощью Psycopg en ru
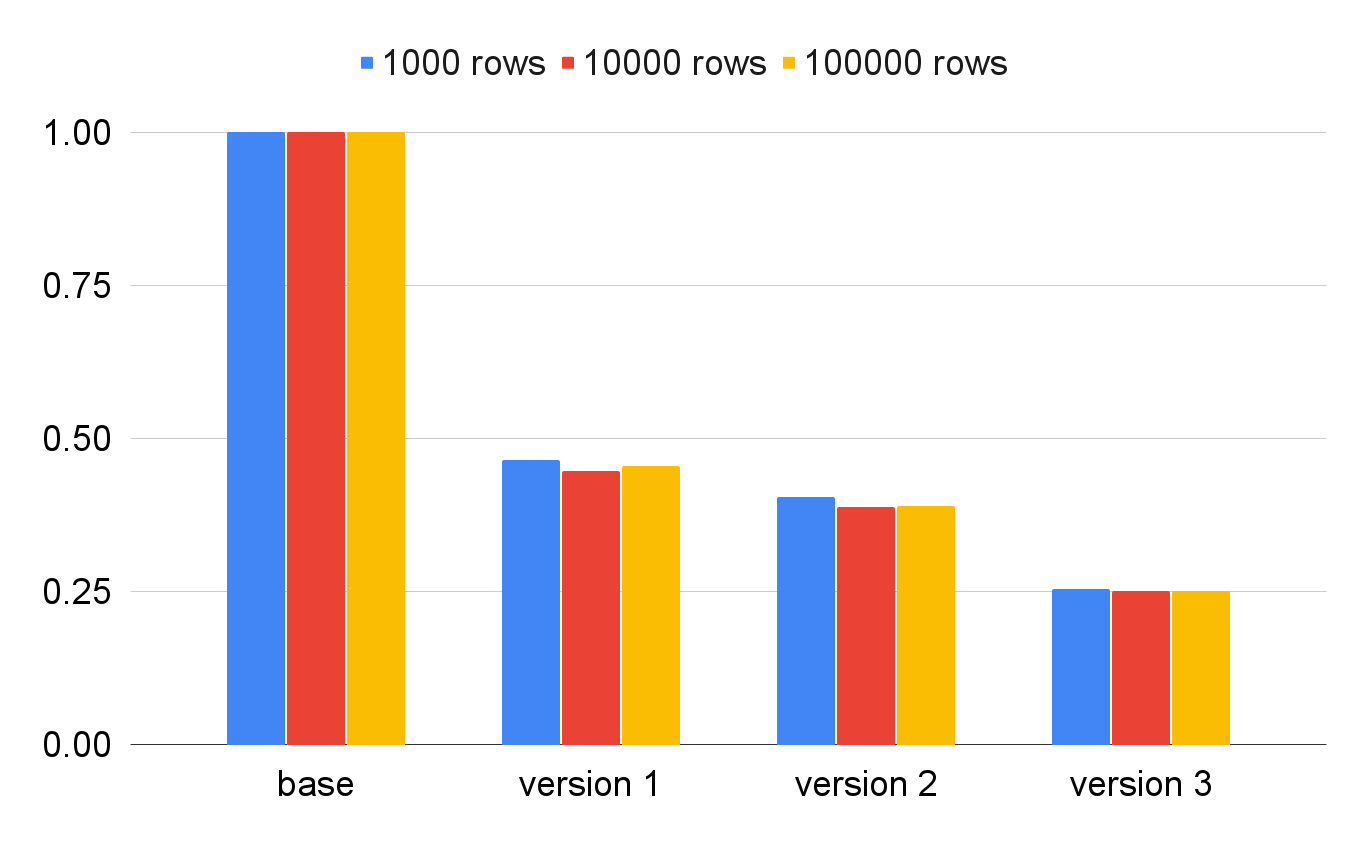
Скорость извлечения данных из базы для каждой из оптимизаций. В процентах от скорости базовой реализации. Обратите внимание, что количество извлекаемых строк слабо влияет на время выполнения.
Раз в год-два мне приходится вспоминать, что Python, ммм… не C++. Обычно, это происходит внезапно, как в этот раз.
Проведя вдумчивый анализ Надоело по 10 секунд ждать загрузки новостей в feeds.fun, поэтому я засучил рукава и полез оптимизировать. Сходу чуть не взялся за эпический рефакторинг, но вовремя вспомнил, что сначала надо измерить, а потом уже резать. Мерять в данном случае совет буквальный — взял профайлер — py-spy — и посмотрел, что конкретно тормозит.
Оказалось, тормозит не вся логика, а вполне конкретное место с извлечением из PostgreSQL таблицы ~100000 строк, плюс-минус 20000. Индексы на месте, тесты проводил с базой на RAM-диске, поэтому со стороны базы всё должно было быть ок.
Такому количеству строк не удивляйтесь:
- Во-первых, у меня большой поток новостей.
- Во-вторых, для каждой новости читалка сейчас ставит около 100 тегов.
Вооружившись py-spy и исходниками psycopg, я прошёл через три этапа оптимизации, уменьшив время выполнения целевой функции примерно в 4 раза только за счёт изменения формата запрашиваемых колонок в SELECT запросе и кода обработки результата.
Далее я расскажу про последовательность любопытных открытий, которые сделал в процессе.
Внимание!
Этот пост — не исследование производительностие Psycopg или Python, а описание конкретного опыта на конкретной задаче со специфическими данными.
Будет неверно судить о производительности Psycopg, или Python в целом, по одному частному случаю.
Оригинальная задача
Сокращённое описание таблицы, в которой хранятся данные (убрал лишнее, чтобы не ехало форматирование):
ffun=# \d o_relations
Table "public.o_relations"
Column | Type | Collation | Nullable |
------------+--------------------------+-----------+----------+
id | bigint | | not null |
entry_id | uuid | | not null |
tag_id | bigint | | not null |
created_at | timestamp with time zone | | not null |
Indexes:
"o_relations_pkey" PRIMARY KEY, btree (id)
"idx_o_relations_entry_id_tag_id" UNIQUE, btree (entry_id, tag_id)
Задача проблемной Python функции: извлечь все tag_id для переданного списка entry_id и вернуть словарь со множеством tag_id для каждого entry_id.
Результат функции должен быть примерно такой:
{
"uuid-1": {1, 2, 3, 4, 5},
"uuid-2": {1, 7, 8},
....
}
Никакой магии, один SELECT плюс формирование словаря.
Оговорки и описание тестов
Чтобы избежать влияния сторонних факторов, я слегка упростил оригинальную задачу:
- Вместо передачи списка
entry_idя передавал количество записей, которые нужно извлечь (1000, 10000, 100000). - Не использовал фабрику строк Psycopg dict_row, чтобы исключить лишние преобразования.
- Замеряемые функции синхронны, оригинальный код был асинхронным.
- Тестовые данные брал с прода.
Также обратите внимание:
- Измерялось время выполнения Python функции с необходимым преобразованием данных, а не чистое время работы Psycopg. Так как важна именно скорость получения необходимого результата.
- Пробовал явно включать использование бинарного протокола коммуникации с PostgreSQL, но изменения были незаметны, поэтому далее об этом варианте не говорю.
- Перед измерением каждая из тестовых функций выполнялась 1 раз, чтобы прогреть базу.
- Для измерения каждой функции я делал 100 запусков и усреднял результаты.
Среднее время выполнения функции было:
- Для базовой версии: 2.28, 23.18, 227.91 секунд для 1000, 10000, 100000 записей соответственно.
- Для финальной версии: 0.58, 5.83, 57.27 секунд для 1000, 10000, 100000 записей соответственно.
Но помните, задача и данные специфичны для конкретного проекта, и даже для моего конкретного аккаунта в нём, поэтому мало что скажут стороннему читателю.
Полный код теста
import uuid
import psycopg
import timeit
N = 1000
M = 100
def version_1(conn, n):
data = {}
with conn.cursor() as cur:
cur.execute("SELECT * FROM o_relations ORDER BY id DESC LIMIT %(limit)s", {"limit": n})
results = cur.fetchall()
for row in results:
entry_id = row[1]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(row[2])
return data
def version_2(conn, n):
data = {}
with conn.cursor() as cur:
cur.execute("SELECT entry_id, tag_id FROM o_relations ORDER BY id DESC LIMIT %(limit)s", {"limit": n})
results = cur.fetchall()
for row in results:
entry_id = row[0]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(row[1])
return data
def version_3(conn, n):
data = {}
entry_ids_mapping = {}
with conn.cursor() as cur:
cur.execute(
"SELECT entry_id::text, tag_id FROM o_relations ORDER BY id DESC LIMIT %(limit)s", {"limit": n}
)
results = cur.fetchall()
for row in results:
raw_entry_id = row[0]
if raw_entry_id not in entry_ids_mapping:
entry_ids_mapping[raw_entry_id] = uuid.UUID(raw_entry_id)
entry_id = entry_ids_mapping[raw_entry_id]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(row[1])
return data
def version_4(conn, n):
data = {}
entry_ids_mapping = {}
with conn.cursor() as cur:
cur.execute(
"SELECT CONCAT(entry_id::text, '|', tag_id::text) AS ids FROM o_relations ORDER BY id DESC LIMIT %(limit)s",
{"limit": n},
)
results = cur.fetchall()
for row in results:
raw_entry_id, raw_tag_id = row[0].split("|")
if raw_entry_id not in entry_ids_mapping:
entry_ids_mapping[raw_entry_id] = uuid.UUID(raw_entry_id)
entry_id = entry_ids_mapping[raw_entry_id]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(int(raw_tag_id))
return data
def run():
with psycopg.connect("dbname=ffun user=ffun password=ffun host=postgresql") as conn:
##########################################################################
# Demonstrate that everything works correctly and the results are the same
# Also, warm up the database
##########################################################################
data_1 = version_1(conn, N)
data_2 = version_2(conn, N)
data_3 = version_3(conn, N)
data_4 = version_4(conn, N)
print(data_1 == data_2 == data_3 == data_4)
##########################################################################
# Measure the performance of each version
##########################################################################
time_1 = timeit.timeit(lambda: version_1(conn, N), number=M)
time_2 = timeit.timeit(lambda: version_2(conn, N), number=M)
time_3 = timeit.timeit(lambda: version_3(conn, N), number=M)
time_4 = timeit.timeit(lambda: version_4(conn, N), number=M)
print(f"Number of records: {N}")
print(f"Number of measurements: {M}")
print(f"Version 1: {time_1:.2f} seconds")
print(f"Version 2: {time_2:.2f} seconds")
print(f"Version 3: {time_3:.2f} seconds")
print(f"Version 4: {time_4:.2f} seconds")
run()
Базовая версия функции:
def version_1(conn, n):
data = {}
with conn.cursor() as cur:
cur.execute("SELECT * FROM o_relations ORDER BY id DESC LIMIT %(limit)s", {"limit": n})
results = cur.fetchall()
for row in results:
entry_id = row[1]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(row[2])
return data
Оптимизация 1
Первое, что показал профайлер — большое время проведённое кодом в psycopg/types/datetime.py — больше 18%! Как вы могли заметить, никакой работы со временем в коде функции нет.
«Ага, — сказал я себе, — Зря ты, Tiendil, звёздочку в SELECT поставил, но тебе только две колонки надо, а время парсить всегда дорого».
И заменил звёздочку на конкретные колонки:
def version_2(conn, n):
data = {}
with conn.cursor() as cur:
cur.execute("SELECT entry_id, tag_id FROM o_relations ORDER BY id DESC LIMIT %(limit)s", {"limit": n})
results = cur.fetchall()
for row in results:
entry_id = row[0]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(row[1])
return data
Оптимизация 2
Следующий запуск профайлера показал, что стало лучше, но всё-ещё много времени тратится на парсинг UUID — типа колонки entry_id.
Как я уже упоминал, особенность данных в том, что для одного значения entry_id может быть порядка 100 записей в таблице. Поэтому нет смысла парсить entry_id для каждой строки.
Что если запрашивать entry_id как строку, а парсить уже на стороне Python, но только один раз для каждого уникального значения?
def version_3(conn, n):
data = {}
entry_ids_mapping = {}
with conn.cursor() as cur:
cur.execute(
"SELECT entry_id::text, tag_id FROM o_relations ORDER BY id DESC LIMIT %(limit)s", {"limit": n}
)
results = cur.fetchall()
for row in results:
raw_entry_id = row[0]
if raw_entry_id not in entry_ids_mapping:
entry_ids_mapping[raw_entry_id] = uuid.UUID(raw_entry_id)
entry_id = entry_ids_mapping[raw_entry_id]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(row[1])
return data
Оптимизация 3
Стало ещё лучше (смотрите заглавную картинку).
На этот раз py-spy завёл меня в куда более интересное место: psycopg/pq/pq_ctypes.py, а точнее в PGresult.get_value.
PGresult.get_value возвращает одно значение из результата запроса по номеру строки и колонки. Попутно в нём происходит конвертация данных из формата C в формат Python, в частности, с помощью вызова ctypes.string_at.
Так вот, преобразование данных из формата C в формат Python — очень дорогое удовольствие. Даже не так, ОЧЕНЬ ДОРОГОЕ удовольствие. Особенно когда этих преобразований много, например, по два на каждую из 100000 строк.
Можно ли сократить количество преобразований? Конечно, давайте на стороне базы собирать колонки в одну, а на стороне Python разбирать их обратно.
Сказано — сделано, вот наш финальный вариант:
def version_4(conn, n):
data = {}
entry_ids_mapping = {}
with conn.cursor() as cur:
cur.execute(
"SELECT CONCAT(entry_id::text, '|', tag_id::text) AS ids FROM o_relations ORDER BY id DESC LIMIT %(limit)s",
{"limit": n},
)
results = cur.fetchall()
for row in results:
raw_entry_id, raw_tag_id = row[0].split("|")
if raw_entry_id not in entry_ids_mapping:
entry_ids_mapping[raw_entry_id] = uuid.UUID(raw_entry_id)
entry_id = entry_ids_mapping[raw_entry_id]
if entry_id not in data:
data[entry_id] = set()
data[entry_id].add(int(raw_tag_id))
return data
Результаты этой версии примерно в 4 раза быстрее базовой (на моих данных).
На всякий случай проговорю словами
Отформатировать и склеить колонки результата на стороне PostgreSQL и распарсить Python-ом может быть быстрее, чем запрашивать колонки как отдельные значения.
По крайней мере, это справедливо для конкретного случая использования Psycopg. Я люблю эту библиотеку и верю в её качество, поэтому думаю, что у альтернатив ситуация не лучше.
Читать далее
- Миграции backend на практике
- GraphQL & Python
- Python & OpenAPI
- Open source сервисы аутентификации
- Как завалить собес у меня
- Модная типизация в Python
- Генерация подземелий — от простого к сложному
- Заметки о метриках бэкенда в 2024
- Автоматический генератор нелинейных квестов
- Как я делал и делал бы поддержку GDPR