Заметки о метриках бэкенда в 2024 en ru
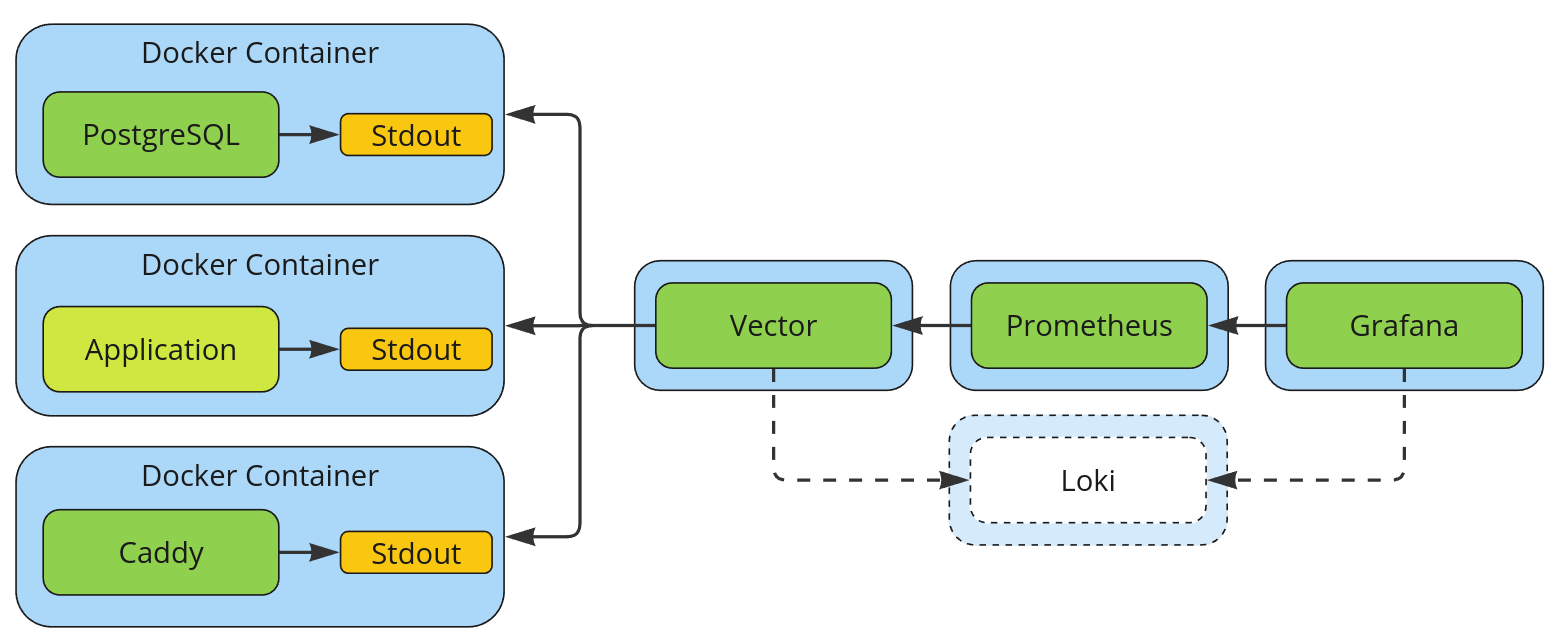
Примерно так сейчас выглядит сбор метрик в Feeds Fun. Loki добавлен как возможный следующий шаг развития инфраструктуры.
Раз в 2-3 года у меня начинается новый проект и приходится «заново» разбираться с метриками — как их собирать и рисовать на этот раз. Не то чтобы это единственное, с чем приходится разбираться, — обычно меняется много всего, но подход к метрикам меняется гарантировано.
Я слал метрики по UDP в Graphite (в 2024, пост из 2015 выглядит забавно), использовал SaaS-решения вроде Datadog и New Relic, аггрегировал метрики в приложении, чтобы их забирал Prometheus, писал метрики в логи для AWS CloudWatch.
И всегда всплывали нюансы:
- Особенности технологий проекта и его архитектуры накладывают внезапные ограничения.
- Технические требования к полноте, корректности и точности метрик сталкиваются с бизнес ограничениями на стоимость поддержки инфраструктуры.
- Всплывают специализированные базы данных для хранения time series, с которыми разработчики бэка редко имеют дело напрямую.
- Не говоря уже об идеологии и личных предпочтениях разработчиков.
Поэтому нет одного идеального способа собирать метрики. Более того, разнообразие подходов вкупе с быстрой эволюцией всей области привело к появлению огромного количества open-source кирпичей, из которых можно собрать любого франкенштейна.
Поэтому, когда дошли руки для реализации метрик в Feeds Fun, мне пришлось в очередной раз потратить несколько дней на актуализацию знаний и наведение порядка в голове.
В этом посте я поделюсь некоторыми своими мыслями и решением, которое выбрал для себя. Но не в форме урока, а в форме тезисов о темах к которым неравнодушен именно я.
Метрики — базовый инструмент для управления техническим состоянием проекта на оперативном, тактическом и стратегическом уровнях
Метрики — это буквально глаза разработчика. Без них невозможно видеть как актуальную техническую ситуацию на проекте так и её долгосрочные тренды.
Если брать классический цикл из системной инженерии (и других мемплексов):
- сбор данных;
- анализ данных;
- синтез (принятие) решения;
- реализация решения;
то метрики — это первый шаг цикла (и часть второго). Без них невозможно замкнуть обратную связь для эффективного управления проектом.
Говоря про уровни планирования, метрики помогают:
- На оперативном уровне быстрее разбираться с форс-мажорными ситуациями.
- На тактическом уровне устранять негативные тенденции (вроде деградации производительности из-за роста объёма данных) до момента, когда они срабатывают.
- На стратегическом уровне планировать дорогие изменения в архитектуре и инфраструктуре. Например, обосновывать необходимость шардирования базы или внедрения очередей.
Конечно, из этого не слудет, что первым коммитом должна идти реализация метрик — всё хорошо в меру.
При разработке прототипа и даже при начале эксплуатации можно опираться на свой опыт, чуйку, периодические ручные проверки состояния системы, дисциплинированность и компетентность команды. В конце-концов, плохо работающая бизнес-логика без метрик обычно лучше нереализованной бизнес-логики с крутыми метриками :-D
Но общая идея примерно следующая: чем сильнее последствия срабатывания рисков тем больше метрик вам надо.
За метриками надо следить глазами
Метрики нужны не только чтобы смотреть на них во время борьбы с инцидентами или планирования долгосрочных изменений; или поставлять данные для тригеров.
Метрики демонстрируют вам динамику проекта, его внутреннюю жизнь.
Привычка периодически смотреть на метрики глазами запускает цикл обратной связи для уточнения вашей ментальной модели проекта. А точная ментальная модель — залог вашей успешной работы, скорости и качества принимаемых решений.
Вы не знаете какие метрики вам потребуются
Есть базовые метрики, которые нужны всем или почти всем. Например, персентили времени ответа на запросы, количество запросов в секунду, количество ошибок, количество и персентили запросов на каждый из эндпоинтов API, размеры базы данных, таблиц, индексов и так далее.
Но базовые метрики, что логично, позволяют реагировать только на базовые проблемы. Это уже много, но каждый проект уникален, уникален путь его разработки, поэтому кроме базовых проблем у вас обязательно возникнут проблемы уникальные для вас, задачи уникальные для вас, которые потребуют уникальных метрик.
Для примера, на моём последнем месте работы мы реализовали распределённые транзакции для обработки платежей с помощью Orchestration-based saga в форме FSM. В какой-то момент нам потребовалось видеть динамику изменения распределения FSM по состояниям.
К сожалению, в большинстве случаев, при добавлении новой метрики у неё не будет истории. А история изменений — это то, что делает метрики реально полезными. Если вы столкнулись с проблемой и видите её на метриках, то вам важны не только их текущие показатели, но и динамика: направление изменений, цикличность, сезонность и так далее.
Поэтому, разумно следовать следующим эвристикам:
- Много метрик лучше, чем мало.
- Если вам придумалась метрика и добавить её легко — добавьте.
- Если у вас есть критический компонент в системе, включите режим параноика и обложите его метриками сверху до низу.
Поэтому я очень нелюблю SaaS-решения, которые берут оплату за количество уникальных метрик. Особенно, с учётом определения уникальности по сочетанию названия метрики со всеми возможными комбинациями её меток/тегов. Использование таких сервисов заставляет разработчиков заниматься проектированием метрик вместо разработкой приложения.
История метрик должна быть долгой
В моей практике я часто сталкивался с утвержденями в духе «2 недели истории метрик достаточно». Аргументация заключается в том, что за две недели всплывут любые существенные проблемы. А если проблем не было, то и долгая история не нужна — сэкономим деньги.
Это в корне неверно по следующим причинам.
Люди совершают ошибки: лажают, забывают, отвлекаются, пилят бизнес-фичи в кранче, уходят в отпуск. Из того, что никто за две недели не заметил проблему, не значит, что её нет или что она несущественная.
Наши системы не идеальны, особенно вспомогательные вроде мониторинга. Часто мониторинг обсуждают с позиции «идеальной системы когда мы её построим» — в которой уже есть все возможные метрики и все возможные детекторы аномалий. Но ни у кого никогда не было идеальной системы мониторинга. В большинстве случае она вообще делается по остаточному принципу, так как не несёт прямой пользу никому кроме технарей.
Многие процессы в жизни нелинейны. Проблема легко может нарастать экспоненциально. Например, месяцы незаметно для всех прибавлять по проценту в день к длительности запроса, после чего за неделю увеличить её в 20 раз. С короткой историей мы не сможем заметить тренд вовремя (наклон графика на коротком интервале будет слабо незаметен), но и не сможем быстро найти точку начала тренда.
Код приложения не должен знать о вашем Service Level Agreements
Задача вашего приложения — работать и отдавать чёткие честные измерения своего состояния — быть источником правды. Что делать с этими измерениями — это отдельный вопрос, который должен решаться внешними средствами.
В задачи вашего приложения не должны входить расчёты перцентилей, уменьшение точности метрик, их агрегирование и так далее.
Во-первых, это не относится к бизнес-логике, а значит не несёт пользы пользователям.
Во-вторых, это усложняет приложение, что усложняет его модификацию и поддержку. Не то, чтобы критически, но всё-таки усложняет.
В-третьих, это усложняет и замедляет внесения изменений в метрики. Для примера, если вы используете Prometheus и отдаёте ему гистограммы:
- Для любого изменения гистограмм вам надо будет, в лучшем случае, обновить конфиги приложения на проде. В худшем — обновить его код, а значит сделать полноценный релиз. И будем честными, вы будете релизить, потому что поленились вынести параметры метрик в конфиги.
- Если вам внезапно понадобится разделить метрики по типам гистограмм (например, одна для времени быстрых операций, другая — для медленных), то вам придётся менять код приложения и это могут быть не совсем тривиальные изменения.
В-четвёртых, если у вас может быть несколько версий на проде (a/b тесты, замедленная раскатка релиза, демо-сервера, etc), то у вас образуется каша из несовместимых метрик, что усложнит их анализ.
В-пятых, приложение не может самостоятельно действовать на основе метрик, поэтому не должно пытаться их как-то обрабатывать. Утрируя, оно не сможет сказать надо ли отмасштабировать горизонтально сервера с ним или вертикально отмасштабировать сервер базы. Не говоря уже о самой инициации масштабирования. Это делается системами над приложением.
Поэтому мне не нравится подход Prometheus к сбору предагрегированных метрик, я просто не понимаю как с ним можно нормально жить.
Приложение должно только пушить (push) метрики (сразу)
Не пытаться их хранить, чтобы потом кто-то их собрал.
Во-первых, могут и не собрать по огромному количеству причин. Например, из-за того, что приложение упало за секунду до того, как до него добрался Prometheus.
Во-вторых, до всего ваш коллектор всё равно не доберётся, как бы вы не старались. Всегда есть автономные скрипты, которые тоже нужно мерить. Иногда могут возникнуть и проблемы с границами систем, периметрами безопасности. Поэтому всё равно придётся делать push логику для частных случаев, а значит делать работу дважды, усложнять инфраструктуру.
Это ещё одна причина, почему мне не нравится pull подход Prometheus к сбору метрик.
Метрики и логи — одно целое
И то и другое — телеметрия.
Сообщение о метрике может быть записью в логах и запись в логах можно интерпретировать как метрику.
Поэтому, для нужд приложения, нет смысла их разделять. Пытаясь работать с метриками и логами по-разному вы усложняете архитектуру, инфраструктуру и свою жизнь в целом.
Учитывая текущую (сугубо позитивную) моду на структурированные логи (это когда каждая запись в логах имеет строгий формат, обычно JSON), имеет смысл просто писать всё как логи на stdout.
В таком случае от метрик на стороне приложения остаётся немного.
Во-первых, какая-нибудь функция-обёртка над логирования в духе
def measure(event: str, value: int | float):
logger.info(event, m_kind="measure", m_value=value)
Во-вторых, какой-нибудь механизм задания меток/тегов для всех записей в лог, если вы планируете использовать метки.
Реализация метрик на бэкенде Feeds Fun
Для примера, к чему пришёл я:
- Добавил метод
measureпрямо в класс логгера, благодаря чему могу регистрировать измерения везде, где есть логгер. - Для меток использую контекст процессор устанавливающий contextvars в сочетании с отдельным процессором логов из structlog, который мержит метки в каждую запись логов.
- Все логи пишутся на stdout.
Выглядит это примерно так (полный исходник):
LabelValue = int | str | None
class MeasuringBoundLoggerMixin:
def measure(self,
event: str,
value: float | int,
**labels: LabelValue) -> Any:
if not labels:
return self.info(event, m_kind="measure", m_value=value)
with bound_measure_labels(**labels):
return self.info(event, m_kind="measure", m_value=value)
@contextlib.contextmanager
def measure_block_time(self,
event: str,
**labels: LabelValue) -> Iterator[dict[str, LabelValue]]:
started_at = time.monotonic()
extra_labels: dict[str, LabelValue] = {}
with bound_measure_labels(**labels):
try:
yield extra_labels
finally:
self.measure(event,
time.monotonic() - started_at,
**extra_labels)
@contextlib.contextmanager
def bound_measure_labels(**labels: LabelValue) -> Iterator[None]:
if not labels:
yield
return
bound_vars = structlog_contextvars.get_contextvars()
if "m_labels" in bound_vars:
if labels.keys() & bound_vars["m_labels"].keys():
raise errors.DuplicatedMeasureLabels()
new_labels = copy.copy(bound_vars["m_labels"])
else:
new_labels = {}
new_labels.update(labels)
with structlog_contextvars.bound_contextvars(m_labels=new_labels):
yield
Обработка метрик на бэкенде Feeds Fun
Что происходит с метриками после их записи в лог вы могли видеть на заглавной картинке. На всякий случай продублирую её тут.
Примерно так сейчас выглядит сбор метрик в Feeds Fun. Loki добавлен как возможный следующий шаг развития инфраструктуры.
- Приложение и все утилиты запускаются в Docker контейнерах. Конкретнее, в Docker Swarm, но это не важно.
- Vector настроен собирать логи из докера и делать с ними разные штуки:
- Часть логов преобразует в метрики и агрегирует по правилам Prometheus.
- Все логи будет посылать в какой-нибудь Loki, но чуть позже, пока не тратил время на эту часть.
- Prometheus ходит в одну точку за всеми метриками.
- Grafana рисует дашборды по метрикам из Prometheus.
Большинство манипуляций с метриками: изменение структуры bucket в гистограммах, создание новых метрик, редактирование меток, игнорирование метрик, etc. я могу делать меняя конфиг Vector и никак не затрагивая работу бизнес-логики.
Удобно и то, что определение источников логов в Vector можно настраивать достаточно гибко. Например, в моём случае контейнеры приложения определяются по префиксу имени image контейнера. Соответственно, что бы новое я не запустил на бэке (сервисы, cron задачи, etc), пока у них будет тот же базовый image, их логи и метрики будут распознаваться автоматически.
Удобно и то, что при разворачивании новых серверов и сервисов мне надо будет только настроить потоки данных в Vector (или между экземплярами Vector), а не менять конфигурацию Prometheus или учить его находить сервисы.
Читать далее
- Интересный случай оптимизации извлечения данных с помощью Psycopg
- Как я делал и делал бы поддержку GDPR
- Миграции backend на практике
- GraphQL & Python
- Python & OpenAPI
- Open source сервисы аутентификации
- Как завалить собес у меня
- Модная типизация в Python
- Генерация подземелий — от простого к сложному
- Prompt engineering: строим промпты от бизнес кейсов