Computational mechanics & ε- (epsilon) machines
Открыл для себя новые направления для мониторинга.
Computational mechanics
Авторам минус за тавтологию. Есть вычислительная механика, которая занимается численным моделированием механических процессов и про неё есть статься на вики. Этот пост не про неё.
Этот пост про computational mechanics, которая изучает абстракции сложных процессов: как эмерджентное поведения возникает из суммарного поведения / статистики низкоуровневых процессов. Например, почему стабильно Большое Красное Пятно на Юпитере, или, почему результат вычислений процессора не зависит от свойств каждого электрона в нём.
ε- (epsilon) machine
Концепт устройства, которое может существовать в конечном множестве состояний и может предсказывать своё будущее состояние (или распределения состояний?) на основе текущего.
Computational mechanics позволяет (или должно позволять) представить сложные системы как иерархию ε-machine. Тем самым появляется формальный язык для описания сложных систем и эмерджентного поведения.
Для примера, наш мозг можно представить как ε-machine. Формально, состояние мозга никогда не повторяется (напряжения на нейронах, позиции молекул нейромедиаторов, etc), но существует огромное количество ситуаций, когда мы делаем одно и то же в одних и тех же условиях.
Научно-популярное изложение: https://www.quantamagazine.org/the-new-math-of-how-large-scale-order-emerges-20240610/
P.S. Попробую копнуть в научные статьи. Расскажу, если найду что-нибудь интересное и прикладное. P.P.S. Давно думаю в сторону похожей штуки. К сожалению, повороты жизненного пути не позволяет серьёзно копать в науку и математику. Всегда радуюсь, когда сталкиваюсь с результатами копания других людей.
Мои GPT-шки и prompt engineering

Понечки занимаются prompt engineering (c) DALL-E
Я пользуюсь ChatGPT практически с момента выхода её четвёртой версии (то есть уже больше года). За это время хорошо набил руку в написании запросов к этой штуке.
В какой-то момент, OpenAI разрешили настраивать свой чат с помощью собственных текстовых инструкций (ищите Customize ChatGPT в меню). Я постепенно дописывал туда команды и вот на днях размер инструкций превысил разрешённый максимум :-)
Плюс, оказалось, что универсальный набор инструкций не получается — под каждую задачу их нужно подстраивать, иначе они не будут так полезны как могли бы быть.
Поэтому покумекав, я решил вместо кастомизации своего чата, вынести инструкции в GPT ботов. OpenAI называют их GPTs, по-русски буду называть их GPT-шками. По-сути, это такие же чаты, в которых больше лимит на кастомизированные инструкции и в них можно залить дополнительные тексты как базу знаниий.
Когда-нибудь, я сделаю GPT-шку для этого блога, а пока расскажу про двух рабочих лошадок, которыми пользуюсь каждый день.
- Expert — ответы на вопросы.
- Abstractor — краткое изложение текста.
Для каждой будет описание базового промпта с моими комментариями.
OpenAI недавно открыла магазин GPT-шек, буду благодарен если пролайкаете мои. Конечно, только если они вам полезны.
Как учить и не учить математике
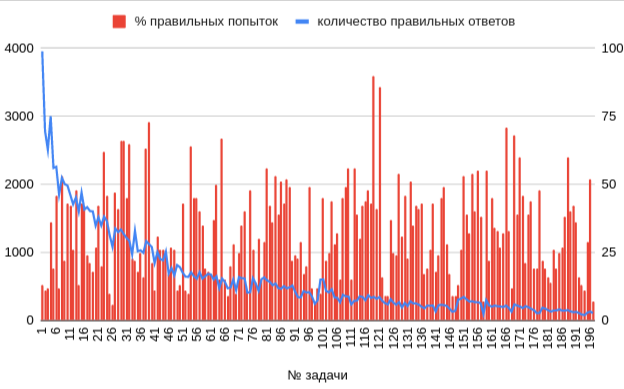
Количество успешных решений и процент успешных попыток отправки решений задач в курсе.
Чёрт дёрнул вспоминать вышку. Я планирую немного забатанить машинное обучение, но сперва решил вспомнить, чему меня в университетах учили. Тем более, что математического анализа мне иногда не хватает.
Поэтому я нагуглил на Stepik курс с пятью звёздами сразу в двух частях (1, 2) за авторством Александра Храброва.
Первую часть я прошёл за 6 полных дней на 100%. Вторую, с перерывами, дней за 10 на 87%: стало жалко времени и сил. График в заголовке намекает на причину :-)
Попутно накопил заметок о курсе, о том как «правильно» учить математике. И как ей учить не надо.
Само собой, всё с моей колокольни.
Экзокортекс: минимальная функциональность
](https://tiendil.org/static/posts/exocortex-minimal-functionality/images/exocortex-minimal-functionality-cover.png)
В тексте о чертах современного экзокортекса я резюмировал его суть следующим образом: единообразное автоматизируемое взаимодействие с качественной личной информацией из гетерогенных источников.
Давайте теперь подумаем о функциональности подобной системы. Пока без конкретики сформулируем требования и ограничения, которые уместно к ней применить.
Воля как артефакт модели реальности
Какое пафосное название я придумал, можно даже пост не писать :-D
Пока читал Я, мозг и возникновение сознания появилась следующая гипотеза:
- Мозг поддерживает модель реальности и активно ей пользуется (строит прогнозы, обновляет её).
- Моделируются внешний мир, собственное тело и даже сам мозг (мы можем задуматься о том, что подумали бы в гипотетической ситуации).
- Составляющими модели являются, в том числе, все наши: ценности, идеи, мысли, желания — всё, что нас определяет.
Тогда что первично: информация о нас в модели реальности или информация о нас в мозге вне модели?
И следующий вопрос: а есть ли информация о нас вне этой модели?