Считаем бизнес-план для игры в Steam
Заработать миллионы проще простого, сейчас расскажу как :-D
Когда выкладывал отчётную презентацию (слайды) по World Builders 2023 (мои посты, сайт), обещал рассказать как делал roadmap и финансовую модель для игры. Выполняю обещание.
К концу поста у нас на руках будут:
- Краткая стратегия нашей компании: что мы делаем, как, зачем и почему.
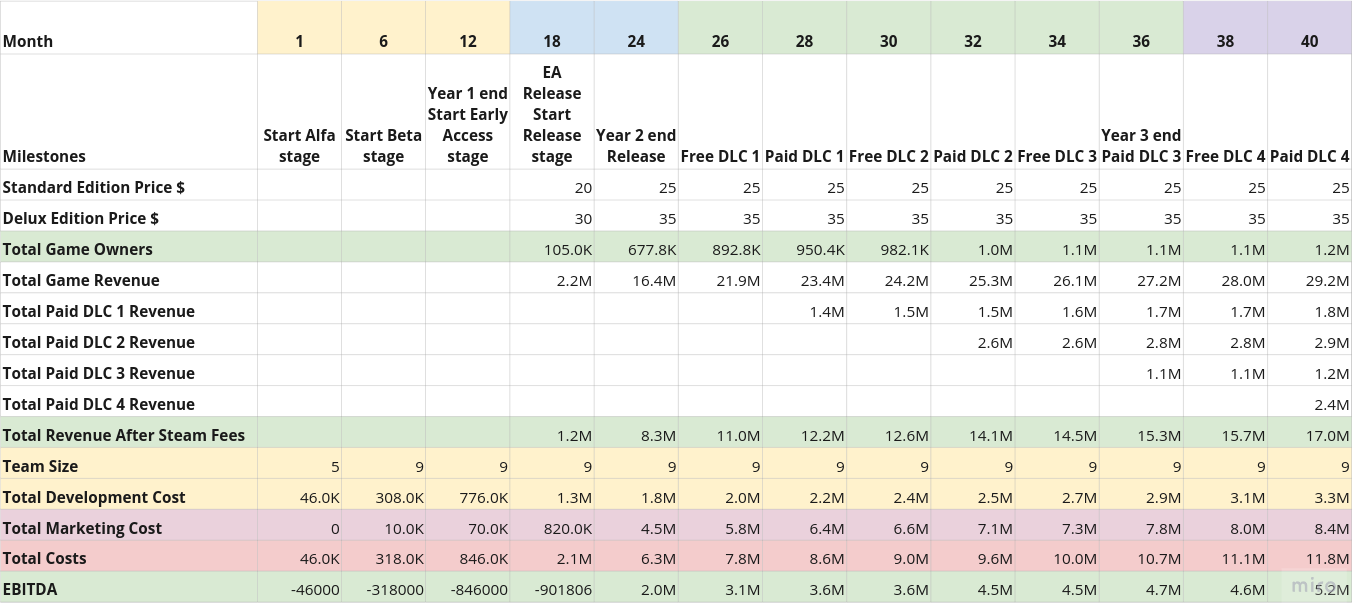
- Табличка наших маяков — успешных игр, которые примерно похожи на то, что мы хотим сделать. Похожи как по геймплею, так и по размеру команды, бюджету, etc.
- Состав команды, которую нам надо собрать.
- Roadmap — план разработки нашей игры.
- Зачатки маркетинговой стратегии.
- Финансовая модель — сколько мы будем тратить, сколько зарабатывать.
- Огромное количество моих оговорок по всему посту.
- Шутки и прибаутки.
Все итоговые документы вы можете найти тут.
Мои GPT-шки и prompt engineering

Понечки занимаются prompt engineering (c) DALL-E
Я пользуюсь ChatGPT практически с момента выхода её четвёртой версии (то есть уже больше года). За это время хорошо набил руку в написании запросов к этой штуке.
В какой-то момент, OpenAI разрешили настраивать свой чат с помощью собственных текстовых инструкций (ищите Customize ChatGPT в меню). Я постепенно дописывал туда команды и вот на днях размер инструкций превысил разрешённый максимум :-)
Плюс, оказалось, что универсальный набор инструкций не получается — под каждую задачу их нужно подстраивать, иначе они не будут так полезны как могли бы быть.
Поэтому покумекав, я решил вместо кастомизации своего чата, вынести инструкции в GPT ботов. OpenAI называют их GPTs, по-русски буду называть их GPT-шками. По-сути, это такие же чаты, в которых больше лимит на кастомизированные инструкции и в них можно залить дополнительные тексты как базу знаниий.
Когда-нибудь, я сделаю GPT-шку для этого блога, а пока расскажу про двух рабочих лошадок, которыми пользуюсь каждый день.
- Expert — ответы на вопросы.
- Abstractor — краткое изложение текста.
Для каждой будет описание базового промпта с моими комментариями.
OpenAI недавно открыла магазин GPT-шек, буду благодарен если пролайкаете мои. Конечно, только если они вам полезны.
Реализация Generative Adversarial Network
В завершение разбирательства с Deep Learning решил посмотреть что-нибудь более интересное и ориентированное на генерацию контента — реализовать GAN.
По правде говоря, большую часть времени с GAN (и Autoencoder) я экспериментировал на спрайтах карты Сказки. Ожидаемо, на таком мизере обучающих данных ничего интересного не получилось. Хотя польза и была. Поэтому для поста я подготовил отдельный notebook с более наглядными результатами — генерацией обуви по набору данных Fashion MNIST.
Ноутбук с реализацией GAN и комментариями.
Про архитектуру GAN лучше почитать в вики, интернетах или моём ноутбуке.
Краткая суть:
- Тренируются две сети: generator & discriminator.
- Генератор учится создавать картинки из шума.
- Дискриминатор учится отличать поддельные картинки от настоящих.
- Ошибка дискриминатора определяется качеством предсказания фейковости изображения.
- Ошибка генератора определяется качеством обмана дискриминатора.
Если правильно подобрать топологии сетей и параметры обучения, то в итоге генератор научается создавать картинки неотличимые от оригинальных. ??????. Profit.
Kaggle: Digit Recognizer (MNIST) точность 0.99585

Примеры цифр из набора MNIST.
Продолжаю путешествие по занимательным землям Deep Learning.
В прошлый раз я учился заводить deep learning на локальной машине и делал совсем детскую, искусственную и неспецифическую для DL задачу.
В этот раз решил попробовать что-то более диплёрничное — научиться решать задачи на Kaggle. Есть предположение, что Kaggle — самый простой и интересный способ учить DL.
На этом сервисе есть задачи для новичков, одну такую — Digit Recognizer — я выбрал для тренировки. Соревнование по распознаванию рукописных цифр из набора MNIST. Этот набор должны были встречать даже люди далёкие от ML.
Notebook с решением и комментариями опубликован на github.
На момент отправки решение занимало 467 место из ~7000. На мой взгляд неплохой результат, учитывая, что первые мест 150 занимают читерские решения. MNIST — общедоступный набор данных, их можно скачать вне kaggle и залить в качестве решения готовые ответы, или переобучить сеть на полном наборе.