Мои GPT-шки и prompt engineering

Понечки занимаются prompt engineering (c) DALL-E
Я пользуюсь ChatGPT практически с момента выхода её четвёртой версии (то есть уже больше года). За это время хорошо набил руку в написании запросов к этой штуке.
В какой-то момент, OpenAI разрешили настраивать свой чат с помощью собственных текстовых инструкций (ищите Customize ChatGPT в меню). Я постепенно дописывал туда команды и вот на днях размер инструкций превысил разрешённый максимум :-)
Плюс, оказалось, что универсальный набор инструкций не получается — под каждую задачу их нужно подстраивать, иначе они не будут так полезны как могли бы быть.
Поэтому покумекав, я решил вместо кастомизации своего чата, вынести инструкции в GPT ботов. OpenAI называют их GPTs, по-русски буду называть их GPT-шками. По-сути, это такие же чаты, в которых больше лимит на кастомизированные инструкции и в них можно залить дополнительные тексты как базу знаниий.
Когда-нибудь, я сделаю GPT-шку для этого блога, а пока расскажу про двух рабочих лошадок, которыми пользуюсь каждый день.
- Expert — ответы на вопросы.
- Abstractor — краткое изложение текста.
Для каждой будет описание базового промпта с моими комментариями.
OpenAI недавно открыла магазин GPT-шек, буду благодарен если пролайкаете мои. Конечно, только если они вам полезны.
Два года пишем RFC — статистика
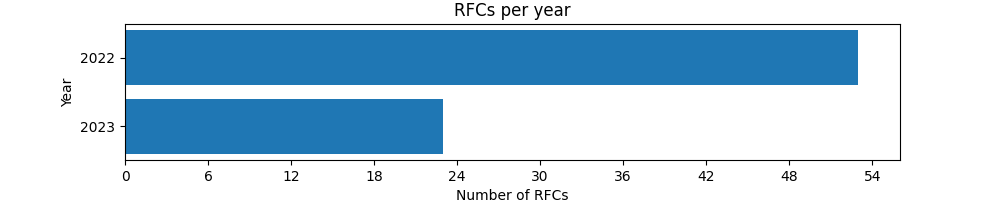
Два года как я Lead/Engineering Manager в платёжке Palta. А на следующей неделе я ухожу из компании в очередной творческий отпуск.
Время подводить итоги. Начну с моей самой любимой инициативы.
С первого месяца я начал продвигать идею предварения крупных изменений текстовыми документами — RFC — Request for Comments.
В этом посте будет анализ двух лет применения этой практики. Чтобы пошарить опыт, подвести итоги и иметь под рукой агитку для моего следующего места работы.
Как завалить собес у меня
Мы в Palta активно ищем сотрудников, поэтому я собеседую людей уровня senior & lead. А до этого в Melsoft доводилось мидлов и выше собеседовать. Накопился ряд наблюдений, которыми хочется поделиться.
Сначала хотел написать на глобальную тему, вроде разницы между junior, middle, senior & lead, но дело шло туго, поэтому сделаю проще.
Расскажу о косяках, которые с большой вероятностью помешают пройти собеседование конкретно у меня.
По отдельности каждая проблема — не приговор, но точно снижает шансы на положительное впечатление.
Для каждой проблемы я написал упрощённый пример диалога. Надеюсь получилось наглядно. Главное помните, что вопросы и ответы там придуманы специально для иллюстрации проблемы, а не взяты из реальных собесов. По большей части :-)
Экзокортекс: минимальная функциональность
](https://tiendil.org/static/posts/exocortex-minimal-functionality/images/exocortex-minimal-functionality-cover.png)
В тексте о чертах современного экзокортекса я резюмировал его суть следующим образом: единообразное автоматизируемое взаимодействие с качественной личной информацией из гетерогенных источников.
Давайте теперь подумаем о функциональности подобной системы. Пока без конкретики сформулируем требования и ограничения, которые уместно к ней применить.
Открыл исходники Morphologic
В апреле я открыл доступ к своему хобби-проекту Morphologic.
Как я и опасался, штука оказалась для очень частных случаев. Настолько, что даже я её особо за эти 3 месяца не использовал.
В то же время я всё ещё думаю, что сама по себе она полезна, а значит проект останется доступен для всех.
В рамках наведения порядка я решил открыть его исходники под лицензией BSD.
Ссылка на репозиторий: https://github.com/Tiendil/morphologic
Все заметки из Google Docs переехали в issues.
В телеграм есть группа для обсуждения проекта: https://t.me/morphologic_soft
Если кто-нибудь хочет вписаться в разработку Morphologic, я с радостью эту инициативу поддержу.
На текущий момент планы по проекту у меня следующие:
- Ждать, пока он мне реально и сильно понадобится, чтобы получить интересный пример использования.
- Если будет настроение, опубликую статью на Хабре про морфологический анализ со ссылкой на Morphologic в конце. Лишние звёзды на гитхабе и карме ещё никому не мешали :-D