Feeds Fun — читалка новостей с тегами и ChatGPT
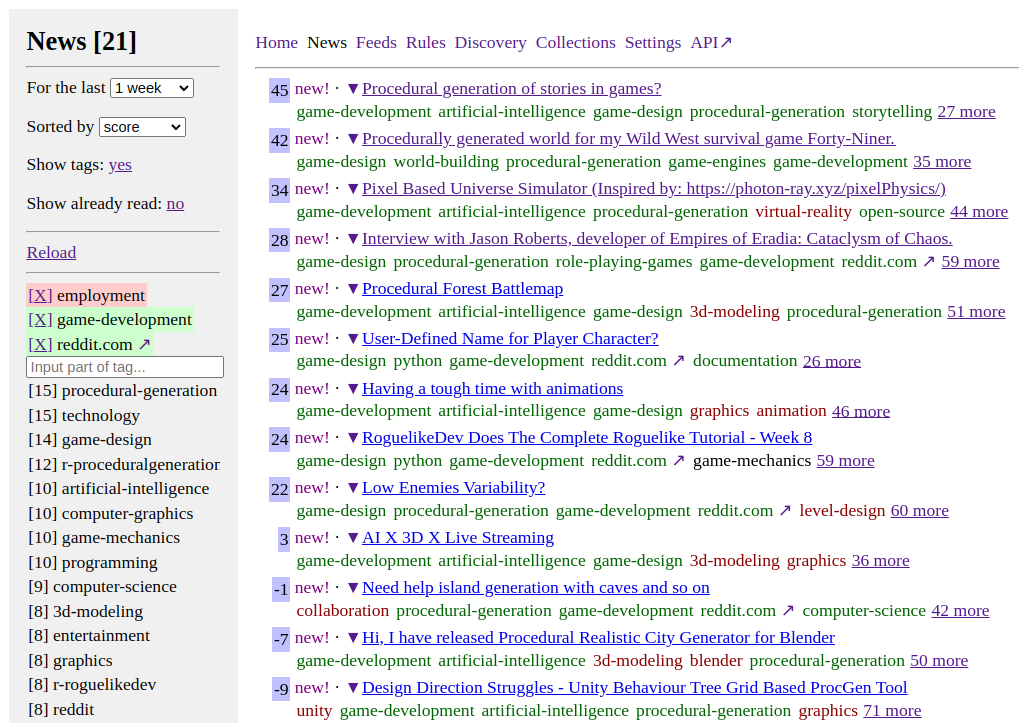
Выглядит неприглядно, но это временно.
Задержался с постом, а между тем читалка уже работает и экономит мне 4-8 часов в неделю.
Для нетерпеливых и ленивых:
- Репозиторий: github.com/tiendil/feeds.fun
- Сайт: feeds.fun — заходите, подписывайтесь на подготовленные коллекции новостей, экспериментируйте.
Суть:
- Читалка автоматически определяет теги для каждой новости. Тут очень кстати пришлась ChatGPT.
- Вы создаёте правила в духе
elon-musk & twitter => score -100500,procedural-content-generation & hentai => score +13. - В интерфейсе сортируете новости по интересности и читаете только самые-самые именно для вас.
Если есть просьбы по фичам — создавайте issue, постараюсь воплощать. Хочется, чтобы штука пошла в народ.
Open source сервисы аутентификации
Потребовалось сделать регистрацию/логин пользователей для пет-проекта. А я это жуть как не люблю, прямо до скрежета в зубах. Поэтому решил поискать что-нибудь совсем готовое, чтобы минимум кода писать и можно было однотипно использовать в будущих проектах.
В итоге нашёл несколько интересных сервисов. Забавно, при узкой предметной области они заметно отличаются друг от друга.
Далее будет моё предвзятое и не особо компетентное мнение. Сугубо для закрепления в истории результатов раскопок.
Есть три проекта, которые вызвали мой интерес:
Фич у каждого сервиса много, даже не буду пытаться перечислять. Учтите, у каждого из них уникальные их наборы. Надо проверять, что выбранный сервис умеет всё что надо и как надо.
Автоматический генератор квестов
Изначально статья была опубликована на Хабре в 2013 году, но я решил вернуть её в блог. Изменений не делал, поэтому подача может немного отличаться от традиционной.
Несмотря на то, что вопрос автоматической генерации заданий в RPG достаточно древний, общедоступных работающих версий таких генераторов почти нет (скорее совсем нет), если не считать совсем примитивных вариантов. Работ по этой теме тоже не много, хотя, если активно гуглить, кое-что можно откопать. Поэтому надеюсь, что этот текст (и сам генератор, ссылка на репозиторий есть в конце статьи) будет полезен.
Для торопливых: визуализация одного из полученных заданий.
Реализация Generative Adversarial Network
В завершение разбирательства с Deep Learning решил посмотреть что-нибудь более интересное и ориентированное на генерацию контента — реализовать GAN.
По правде говоря, большую часть времени с GAN (и Autoencoder) я экспериментировал на спрайтах карты Сказки. Ожидаемо, на таком мизере обучающих данных ничего интересного не получилось. Хотя польза и была. Поэтому для поста я подготовил отдельный notebook с более наглядными результатами — генерацией обуви по набору данных Fashion MNIST.
Ноутбук с реализацией GAN и комментариями.
Про архитектуру GAN лучше почитать в вики, интернетах или моём ноутбуке.
Краткая суть:
- Тренируются две сети: generator & discriminator.
- Генератор учится создавать картинки из шума.
- Дискриминатор учится отличать поддельные картинки от настоящих.
- Ошибка дискриминатора определяется качеством предсказания фейковости изображения.
- Ошибка генератора определяется качеством обмана дискриминатора.
Если правильно подобрать топологии сетей и параметры обучения, то в итоге генератор научается создавать картинки неотличимые от оригинальных. ??????. Profit.
Kaggle: Digit Recognizer (MNIST) точность 0.99585

Примеры цифр из набора MNIST.
Продолжаю путешествие по занимательным землям Deep Learning.
В прошлый раз я учился заводить deep learning на локальной машине и делал совсем детскую, искусственную и неспецифическую для DL задачу.
В этот раз решил попробовать что-то более диплёрничное — научиться решать задачи на Kaggle. Есть предположение, что Kaggle — самый простой и интересный способ учить DL.
На этом сервисе есть задачи для новичков, одну такую — Digit Recognizer — я выбрал для тренировки. Соревнование по распознаванию рукописных цифр из набора MNIST. Этот набор должны были встречать даже люди далёкие от ML.
Notebook с решением и комментариями опубликован на github.
На момент отправки решение занимало 467 место из ~7000. На мой взгляд неплохой результат, учитывая, что первые мест 150 занимают читерские решения. MNIST — общедоступный набор данных, их можно скачать вне kaggle и залить в качестве решения готовые ответы, или переобучить сеть на полном наборе.