Нельзя просто так взять и запустить Deep Learning

Продолжаю разбираться с Deep Learning.
Решил попробовать его на практике: сам придумал лабу, сам сделал, сам себя похвалил.
Целью было построить простейшую, но более-менее полную цепочку обучения модели с помощью Keras+TensorFlow и запустить её на своей машине.
Публикую notebook с выполненной лабой, комментариями о базовых штуках, костылях и нюансах. Надеюсь, будет полезна новичкам. Может быть меня даже поругает кто-нибудь из опытных датасаентистов.
А в этом посте покритикую инфраструктуру всего этого.
Жизнь и работа с моделями
.](https://tiendil.org/static/posts/life-and-work-with-models/images/life-and-work-with-models-cover.jpg)
Масштабная модель кораблика. Источник.
Продолжение жизни и работы с ошибками — обсудим штуки на уровень выше.
Эссе получилось большим, но точно найдутся упущенные моменты. Если я что-то забыл — пишите. Буду благодарен и за более интересные примеры.
Итак. Давайте подумаем, как мы предсказываем будущее всякое.
Предсказаниями мы занимаемся постоянно — это буквально суть нашего существования:
- Переходя из комнаты в комнату мы знаем предполагаем, что мебель будет расставлена аналогично прошлому посещению.
- В холодильнике мы ожидаем увидеть еду, которая, по нашему прогнозу, утолит голод.
- Мы ожидаем, что участники дорожного движения будут вести себя в рамках общеизвестных правил. Если машина даёт сигнал поворота, мы прогнозируем, что она повернёт.
Это примеры «гарантированных» предсказаний, но даже они могут не исполнится:
- Мебель в комнате могла быть переставлена во время нашего отсутствия. В некоторых случаях самой комнаты может уже не быть.
- Супруг мог подъесть оставшуюся еду или та могла испортиться.
- Водитель мог включить поворотник из-за ошибки, а может он просто человек такой.
Фактически, мы никогда не знаем актуальное состояние мира вокруг нас:
- Не воспринимаем весь спектр информации об окружении, например, не видим в инфракрасном свете.
- Сигналы до органов восприятия и от них до мозга передаются не мгновенно.
- Мозг тоже работает не мгновенно.
Мы даже не обладаем всей информацией о прошедших событиях.
Поэтому.
Каждое наше решение и действие основывается на предположениях о прошлом, настоящем и будущем.
Штуки, которыми мы создаём предсказания, называются моделями.
MIT 6.S191: галопом по Deep Learning
Отмучавшись с матаном, я решил, что времени на основательное разбирательство со всем машинным обучением уйдёт слишком много — надо срезать углы.
Поэтому следующей целью выбрал курс MIT 6.S191: Introduction to Deep Learning.
Потому что MIT и по темам лекций видно широкое покрытие темы.
Курсом очень доволен.
Как учить и не учить математике
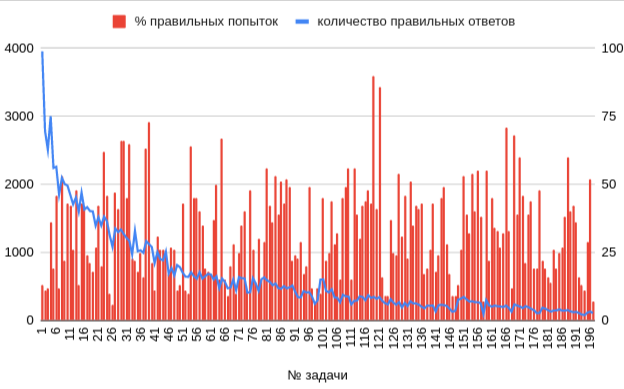
Количество успешных решений и процент успешных попыток отправки решений задач в курсе.
Чёрт дёрнул вспоминать вышку. Я планирую немного забатанить машинное обучение, но сперва решил вспомнить, чему меня в университетах учили. Тем более, что математического анализа мне иногда не хватает.
Поэтому я нагуглил на Stepik курс с пятью звёздами сразу в двух частях (1, 2) за авторством Александра Храброва.
Первую часть я прошёл за 6 полных дней на 100%. Вторую, с перерывами, дней за 10 на 87%: стало жалко времени и сил. График в заголовке намекает на причину :-)
Попутно накопил заметок о курсе, о том как «правильно» учить математике. И как ей учить не надо.
Само собой, всё с моей колокольни.
Yet another Тарантога
Не только я пытаюсь собрать всю свою информацию в одном месте.
Вот описание созданной за год инфраструктуры от другого энтузиаста.
Знакомство с блогом karlicoss и подтолкнуло меня делать собственный велосипед. Всегда приятно узнать, что ты не один такой упоротый :-) Там же я позаимствовал пару базовых концепций.
В отличии от меня, karlicoss избрал более прагматичный подход:
- Поставил во главу угла data liberation — освобождение данных — получение копий всех сущенственных данных, которыми пытаются владеть облака и прочие сервисы. Возможно, логика в том, что владение данными первично, а как их обработать всегда можно придумать.
- Не пытается (пока) изобретать универсальные форматы или универсальный софт. Просто делает инфраструктуру экспорта, хранения и обработки информации, которая работает. То есть у него получается сеть из источников, экспортёров, обработчиков и дашбордов.
Какой из подходов лучше, не знаю. Я отказался от такого варианта потому, что не вижу как разумными силами в долгосрочной перспективе гарантировать устойчивость настолько гетерогенной сети к регрессиям. В случае с централизованной базой знаний я это хотябы в теории представлю.
Но из того, что чего-то не вижу, не следует, что этого нет.