Топовые LLM фреймворки могут быть не так надёжны, как вы думаете
Месяц назад решил добавить поддержку Gemini в Feeds Fun и под это дело изучал топовые LLM фреймворки — писать свой велосипед не хотелось.
В итоге нашёл стыдный баг в интеграции с Gemini в LLamaIndex. Судя по коду, он есть и в Haystack и в плагине для LangChain. А корень проблемы вообще в SDK Google для Python.
При инициализации нового клиента для Gemini код фреймворка перетирает/подменяет API ключи во всех клиентах, созданных до этого. Потому что API ключ, по-умолчанию, хранится в синглетоне.
Смерти подобно, если у вас multi-tenant приложение, и незаметно во всех остальных случаях. Multi-tenant — это когда ваше приложение работает с несколькими пользователями.
Например, в моём случае, в Feeds Fun пользователь может ввести свой API ключ, чтобы улучшить качество сервиса. Представьте какой забавный казус мог бы случиться: пользователь ввёл API ключ для обработки своих рассылок, а потратил токенов (заплатил) за всех пользователей сервиса.
Репортил только в LLamaIndex как security issue и уже 3 недели ноль реакции, для Haystack и LangChain лень воспроизводить. Так что это ваш шанс зарепортить багу в топовый репозиторий. Под катом будет вся инфа, воспроизвести не сложно.
Ошибка примечательна многим:
- Оценка критичности ошибки очень зависит от вкусовщины, опыта и контекста. Для меня, в проектах в которых я работал, — это критическая ошибка безопасности. Но, похоже, для большинства актуальных проектов, которые используют LLM, это вообще не принципиально. Что навевает некоторые мысли о мейнстрим около-LLM разработках.
- Это хороший индикатор низкого уровня контроля качества кода: код ревью, тестов — всех процессов. Всё-таки это интеграция с одним из топовых провайдеров API, найти проблему можно было кучей разных способов, но ни один не сработал.
- Это хорошая иллюстрация порочного подхода к разработке: «копипастим из туториала и льём на прод». Чтобы допустить эту ошибку нужно было проигнорить одновременно и базовую архитектуру твоего проекта и логику вызова кода, который ты копипастишь.
В итоге я забил на эти фреймворки и впилил свой костыль, благо HTTP API для Gemini есть.
Мой вывод из этого безобразия такой: доверять коду, который под капотом у современных LLM фреймворков нельзя. Надо перепроверять, вычитывать. То, что у них написано «production ready», не значит, что они действительно production ready.
Далее расскажу подробнее про сам баг.
Блог переехал на новый движок

Документальная журналистика: процесс перевозки контента на новый движок (c) ChatGPT
Зима не успела закончиться, а я уже выполнил один из планов на год :-D
Причём не только перевёл блог на новый движок, но и сам этот движок написал и заопенсорсил: https://github.com/Tiendil/brigid
Что будет интересным для вас.
На индексной странице появился крутой фильтр постов по тегам. Вдохновлённый feeds.fun. Попробуйте поиграть с ним. Пока он доступен только для больших экранов — на мобилках не увидите — поправлю в будущем.
Посты должны стать читаемее, сайт — удобнее, красивее, быстрее.
Никаких cookies и корпоративных трекеров. Как трекер пока использую облачный plausible.io позже подниму свой инстанс.
Мультиязычность. Большинство новых постов будут доступны на русском и английском. Постепенно буду переводить интересные старые посты.
Исходники постов также открыты и лежат в отдельном репозитории: https://github.com/Tiendil/tiendil-org-content
Feeds Fun — читалка новостей с тегами и ChatGPT
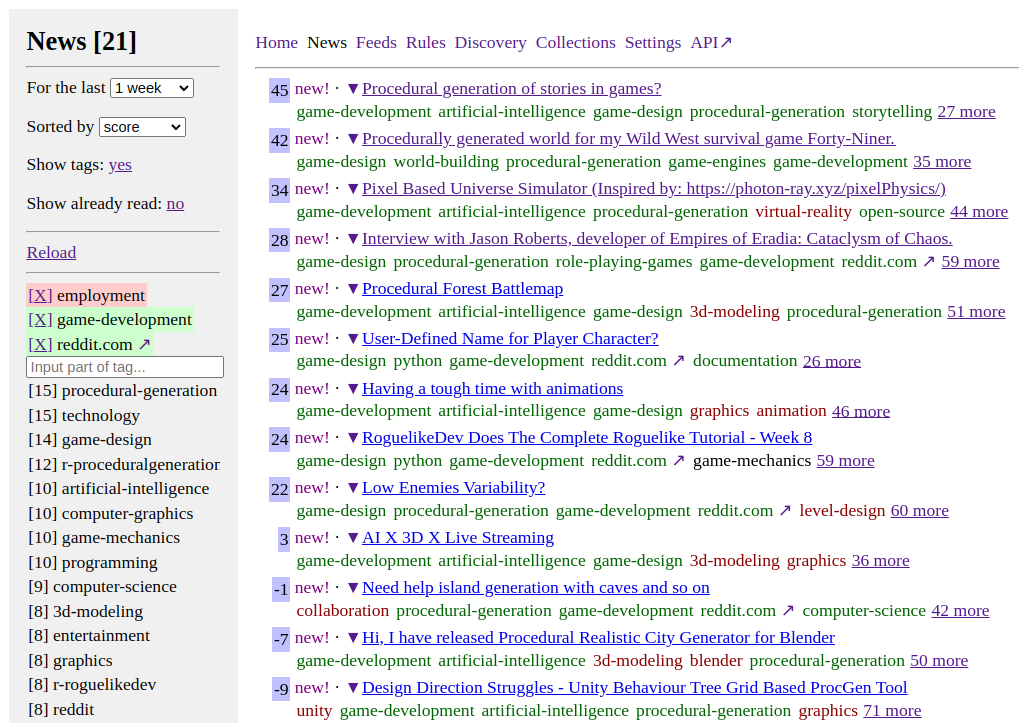
Выглядит неприглядно, но это временно.
Задержался с постом, а между тем читалка уже работает и экономит мне 4-8 часов в неделю.
Для нетерпеливых и ленивых:
- Репозиторий: github.com/tiendil/feeds.fun
- Сайт: feeds.fun — заходите, подписывайтесь на подготовленные коллекции новостей, экспериментируйте.
Суть:
- Читалка автоматически определяет теги для каждой новости. Тут очень кстати пришлась ChatGPT.
- Вы создаёте правила в духе
elon-musk & twitter => score -100500,procedural-content-generation & hentai => score +13. - В интерфейсе сортируете новости по интересности и читаете только самые-самые именно для вас.
Если есть просьбы по фичам — создавайте issue, постараюсь воплощать. Хочется, чтобы штука пошла в народ.
Open source сервисы аутентификации
Потребовалось сделать регистрацию/логин пользователей для пет-проекта. А я это жуть как не люблю, прямо до скрежета в зубах. Поэтому решил поискать что-нибудь совсем готовое, чтобы минимум кода писать и можно было однотипно использовать в будущих проектах.
В итоге нашёл несколько интересных сервисов. Забавно, при узкой предметной области они заметно отличаются друг от друга.
Далее будет моё предвзятое и не особо компетентное мнение. Сугубо для закрепления в истории результатов раскопок.
Есть три проекта, которые вызвали мой интерес:
Фич у каждого сервиса много, даже не буду пытаться перечислять. Учтите, у каждого из них уникальные их наборы. Надо проверять, что выбранный сервис умеет всё что надо и как надо.
Реализация Generative Adversarial Network
В завершение разбирательства с Deep Learning решил посмотреть что-нибудь более интересное и ориентированное на генерацию контента — реализовать GAN.
По правде говоря, большую часть времени с GAN (и Autoencoder) я экспериментировал на спрайтах карты Сказки. Ожидаемо, на таком мизере обучающих данных ничего интересного не получилось. Хотя польза и была. Поэтому для поста я подготовил отдельный notebook с более наглядными результатами — генерацией обуви по набору данных Fashion MNIST.
Ноутбук с реализацией GAN и комментариями.
Про архитектуру GAN лучше почитать в вики, интернетах или моём ноутбуке.
Краткая суть:
- Тренируются две сети: generator & discriminator.
- Генератор учится создавать картинки из шума.
- Дискриминатор учится отличать поддельные картинки от настоящих.
- Ошибка дискриминатора определяется качеством предсказания фейковости изображения.
- Ошибка генератора определяется качеством обмана дискриминатора.
Если правильно подобрать топологии сетей и параметры обучения, то в итоге генератор научается создавать картинки неотличимые от оригинальных. ??????. Profit.