Блог переехал на новый движок

Документальная журналистика: процесс перевозки контента на новый движок (c) ChatGPT
Зима не успела закончиться, а я уже выполнил один из планов на год :-D
Причём не только перевёл блог на новый движок, но и сам этот движок написал и заопенсорсил: https://github.com/Tiendil/brigid
Что будет интересным для вас.
На индексной странице появился крутой фильтр постов по тегам. Вдохновлённый feeds.fun. Попробуйте поиграть с ним. Пока он доступен только для больших экранов — на мобилках не увидите — поправлю в будущем.
Посты должны стать читаемее, сайт — удобнее, красивее, быстрее.
Никаких cookies и корпоративных трекеров. Как трекер пока использую облачный plausible.io позже подниму свой инстанс.
Мультиязычность. Большинство новых постов будут доступны на русском и английском. Постепенно буду переводить интересные старые посты.
Исходники постов также открыты и лежат в отдельном репозитории: https://github.com/Tiendil/tiendil-org-content
Feeds Fun — читалка новостей с тегами и ChatGPT
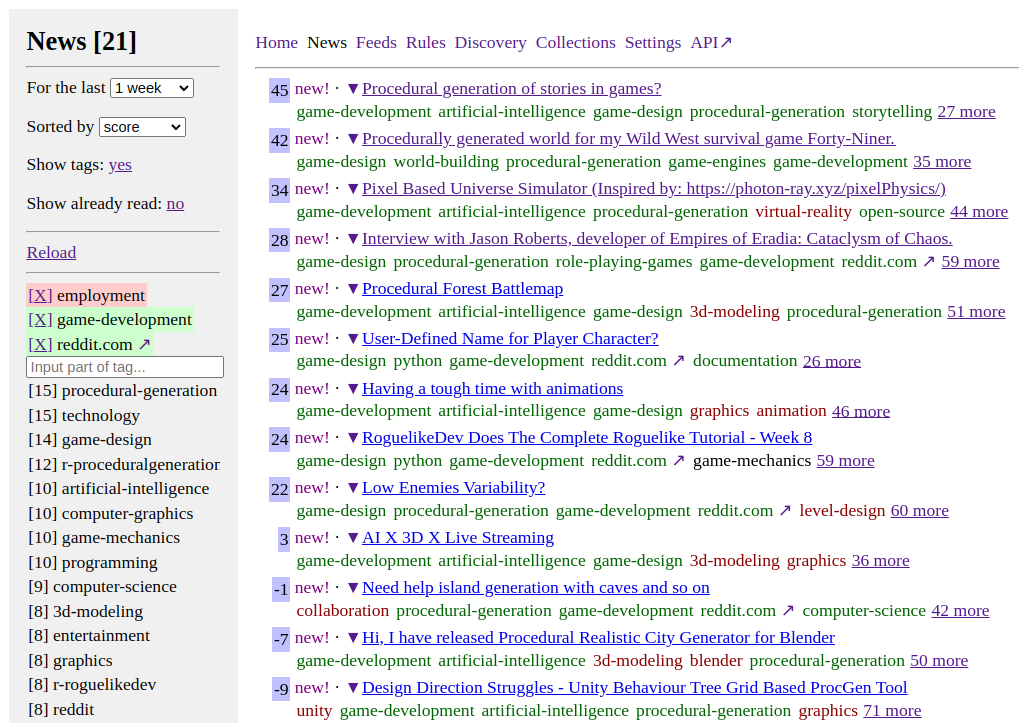
Выглядит неприглядно, но это временно.
Задержался с постом, а между тем читалка уже работает и экономит мне 4-8 часов в неделю.
Для нетерпеливых и ленивых:
- Репозиторий: github.com/tiendil/feeds.fun
- Сайт: feeds.fun — заходите, подписывайтесь на подготовленные коллекции новостей, экспериментируйте.
Суть:
- Читалка автоматически определяет теги для каждой новости. Тут очень кстати пришлась ChatGPT.
- Вы создаёте правила в духе
elon-musk & twitter => score -100500,procedural-content-generation & hentai => score +13. - В интерфейсе сортируете новости по интересности и читаете только самые-самые именно для вас.
Если есть просьбы по фичам — создавайте issue, постараюсь воплощать. Хочется, чтобы штука пошла в народ.
Open source сервисы аутентификации
Потребовалось сделать регистрацию/логин пользователей для пет-проекта. А я это жуть как не люблю, прямо до скрежета в зубах. Поэтому решил поискать что-нибудь совсем готовое, чтобы минимум кода писать и можно было однотипно использовать в будущих проектах.
В итоге нашёл несколько интересных сервисов. Забавно, при узкой предметной области они заметно отличаются друг от друга.
Далее будет моё предвзятое и не особо компетентное мнение. Сугубо для закрепления в истории результатов раскопок.
Есть три проекта, которые вызвали мой интерес:
Фич у каждого сервиса много, даже не буду пытаться перечислять. Учтите, у каждого из них уникальные их наборы. Надо проверять, что выбранный сервис умеет всё что надо и как надо.
Миграции backend на практике
В теории с миграциями всё сложно. Но на практике надо с ними работать. Или совсем отказаться от них. Посмотрим какие рабочие варианты существуют.
В основном я пишу на Python, использую реляционные БД, поэтому и инструменты буду смотреть с ориентировкой на эти технологии. Конечно, только open source. На полноту обзора не претендую.
Если я упустил какой-то софт или описал его с ошибками — пишите в комментариях или в личку — исправлю. В конце концов, досконально изучить документацию всех утилит я не пытался — это потребовало бы слишком много времени.
Pydicates: предикаты для Python
Опубликовал небольшую библиотеку для работы с предикатами в Python: github, pypi. Как всегда, под BSD-3.
Позволяет конструировать функции для отложенных вычислений. Например, описывать такие условия: (OwnedBy('alex') | OwnedBy('alice')) & HasTag('game-design').
Делал для себя, так как уже несколько раз в пет-проектах писал костыли для этого дела. Решил сделать один раз правильно и больше не тратить на это время.
Минимальный пример:
from pydicates import Predicate, common
def HasTag(tag):
return Predicate('has_tag', tag)
def has_tag(context, tag, document):
return tag in document['tags']
common.register('has_tag', has_tag)
document = {'tags': ('a', 'b', 'c', 'd')}
assert common(HasTag('a') & HasTag('c'), document)
assert not common(HasTag('a') & HasTag('e'), document)
assert common(HasTag('a') & ~HasTag('e'), document)
assert common(HasTag('a') & (HasTag('e') | HasTag('d')), document)Больше примеров можно найти в репозитории ./examples
API описано чуть подробнее в ./examples/documents_check.py
Больше примеров можно найти в тестах.