DepMesh — making file dependencies part of project architecture
Coding agents often need to answer practical questions before making changes, such as:
- Which tests should be read before modifying this file?
- Which specifications govern this module?
- Which modules does this code import?
- Which artifacts are affected by this specification change?
- etc.
In other words, the agent must discover all dependencies between files and add them to the context to complete the task correctly.
To answer such questions, the agent must think, form a plan of action, execute it, and analyze the results. All of this consumes tokens, context, and time, without guaranteeing completeness and correctness of the result.
For example, the agent must decide how to search for each specific type of dependency. Sometimes, as in the case of import chains, the agent must read and parse the source code to understand which modules it imports, then generate paths to the corresponding files and read them — this is resource-intensive and inefficient.
The result of such "agentic search" is not guaranteed, the agent may forget to grep by function name and lose an important dependency, or miss a niche spec because it decided it is not needed in this particular case.
Moreover, for searching, the agent uses a bunch of tools, every one of which, by its very use, increases token consumption and eats up context. For the same task, the agent may choose different tools or call them with different parameters from time to time, which kills predictability and reproducibility of the result.
The standard ways to improve the situation are to integrate LSP or something similar as an agent tool, or to deploy one of the countless RAG systems. This helps, but does not solve all problems. For example, it does not guarantee completeness, minimality, and determinism of the result.
Meanwhile, since ancient times we have had a huge pool of utilities and libraries for file searching and source code analysis that can do the same work quickly and efficiently, without any LLMs. Each of them works much better than a probabilistic model in its specific area.
It would be great, I thought, to have a single abstraction over all these tools that provides the agent with a universal interface for extracting all dependencies between files (whatever you configure) and does not require it to think about what to search for or how to search for it.
So, it could be used, for example, like this:
> depmesh dependencies -r governed_by -r tested_by ./depmesh/cli/application.py
## governed_by
Specifications that apply to the artifact.
- @/specs/architecture/entities.md
- @/specs/architecture/errors.md
- @/specs/architecture/modules_layout.md
- @/specs/architecture/naming.md
- @/specs/architecture/static_analysis.md
- @/specs/architecture/tests.md
- @/specs/behavior/cli.md
- @/specs/behavior/file_paths.md
## tested_by
Tests that verify the artifact.
- @/depmesh/cli/tests/test_application.py
As a result, DepMesh was born.
Donna is ready to use
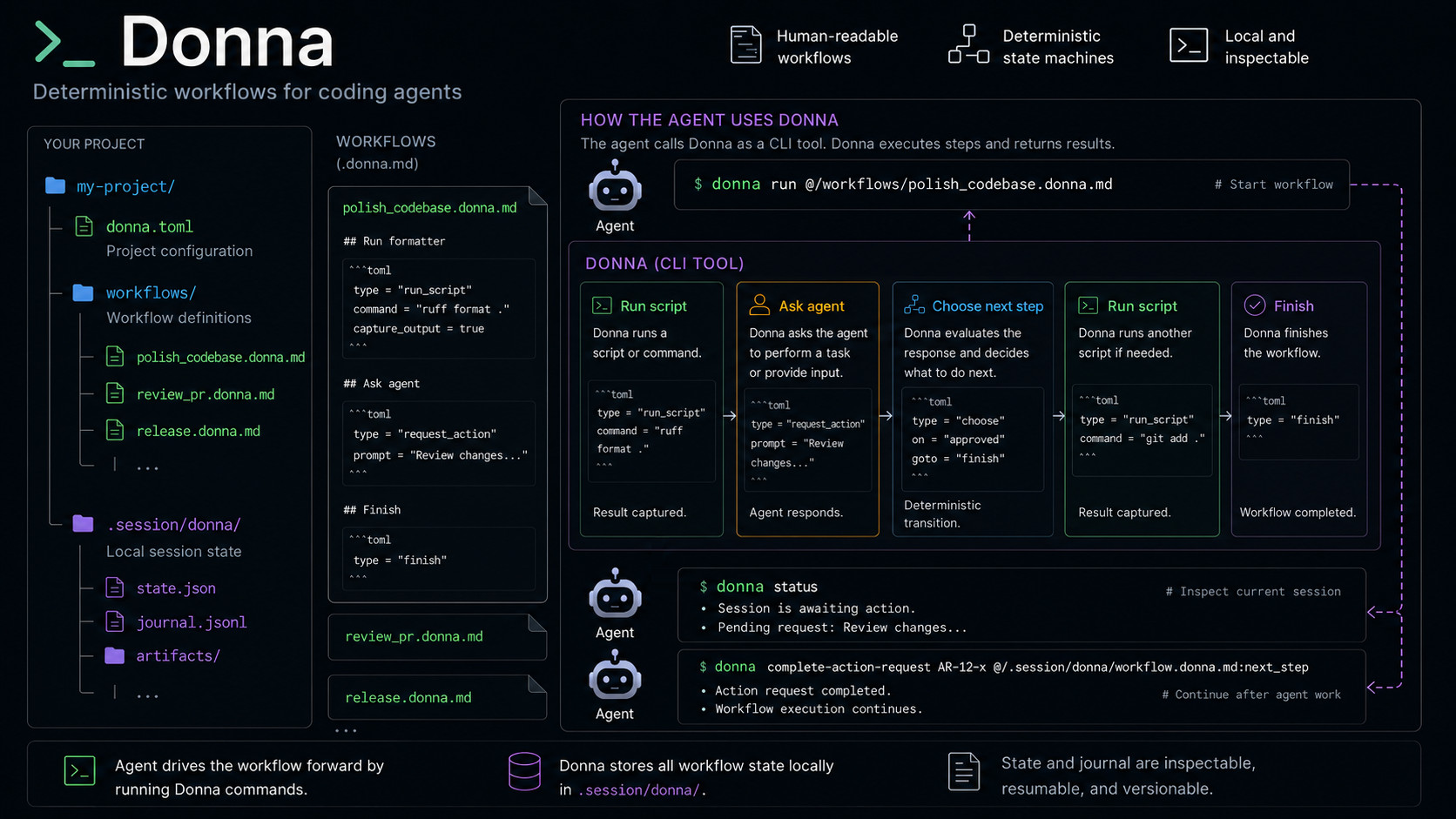
How Donna works.
In February, I released Donna (the original post) — a CLI tool to run agent workflows as state machines and describe them in Markdown files.
Since I was developing it simultaneously with learning how to work with agents, Donna came out as an overcomplicated, versatile monster. It had many features, all of which were useful, but in total, they restricted the developers' environment too much and required too much time to learn.
So, after I gained some experience, I decided to follow the Unix philosophy and refactor a single monolithic tool into a set of smaller tools with single responsibility. New Donna is the first one of them (and the second is depmesh — I'll tell about it in a separate post).
New Donna exists to solve the control flow problems of agents in the long run. The logic is as follows:
- Most development work is repetitive on the meta level: "run this tool, do something with the output, run another tool" or "implement function A, implement tests for function A, implement function B, …".
- Some parts of that work require advanced reasoning, others do not.
- Agents are
almostgood at reasoning, but not so good at keeping the whole process in mind, remembering what they did, what they should do and in which order, etc. - Therefore, we should separate the reasoning part from the control flow part — let agents focus on what they are good at, and keep the control flow to traditional automation tools.
Donna runs predefined workflows as deterministic state machines, so the agent can focus on reasoning, code generation, and other agentic work.
Rust: the language things get rewritten in
Rust is slowly but inexorably refactoring humanity's codebase.
About 5 years ago, I was going through Rust documentation and decided that I didn't like Rust [ru].
Last year, I needed to prototype some game logic and chose Rust for that task, as I couldn't find anything better: Zig looked too immature, and C++ is getting more and more dead complicated with every standard.
As a result, I wrote 10 pages of notes on my experience, which unexpectedly boiled down to a compact statement in the title. And if you are too lazy to read further, then this is praise, not criticism.
However, I still stick to my opinion from the previous post:
A good tool shouldn't constrain its user, because the tool's developer can never anticipate every possible use case.
According to my understanding of beauty of how technology works, a programming language built on Rust's principles should have a near-zero chance of success. However, the de facto situation is exactly the opposite: Rust is rapidly gaining popularity, and after working with it, I have to admit it's a good and powerful tool. But good grief, it's just wrong. Who does things this way?
From my point of view, Rust's success is caused by two factors:
- The tremendous professionalism and experience of its creators and core team.
- The maturity of the software development industry.
I'll try to concisely describe the primary conceptual difference between Rust and other languages; why that difference is both its strength and its weakness; and why, for several years now, there has been an ongoing trend of rewriting everything in Rust.
This post is based on strictly subjective experience
I used Rust for only a year; for prototyping and experimentation; in game development.
Consequently, I'm not in a position to claim expertise in Rust or an unbiased view of it.
For example, some of the difficulties I experienced may have been due to the fact that I was simultaneously prototyping and learning the language. That is, they may have been a consequence of my choice, rather than properties of the language.
At the same time, I have enough development experience to extrapolate from that year to more general cases and form my own subjective opinion on the matter. That is what I will do in this essay.
Want to build a startup together? I could be the right fit

Life is like a hurricane here in Ham-burg…
As you may know, I'm finishing my professional sabbatical. It is still unclear what I'll be doing next, however I've gathered a list of potential projects that are very interesting to me. I'm ready to discuss partnership around those projects right now.
If you're an early-stage startup or are only just about to create one, I would fit well into the role of CTO / technical Co-Founder (I can also take on management and product work). If you're a more mature company starting a new project, I can lead it under whatever title you find appropriate.
If you follow my blog, you probably already have some idea of who I am. But just in case, here is my CV. I have 19 years of experience in software development: from gamedev in C++ to payment backends in Python, from garage-style indie development to large projects.
For convenience, I've split the kinds of projects that interest me into several groups:
- LLM shovels and shovels for LLMs.
- Virtual characters, virtual influencers.
- Gamedev.
Notes on coding agents

Agents coding something (c) ChatGPT
When I was summarizing the last year, I said that agents will be the main topic of 2026. For the last three months, I have been gradually figuring out how to use them for development, and now we can discuss the intermediate results.
Formally speaking, coding agents are a subset of AI agents, but for simplicity, these terms will be used as synonyms in this text.
How I used agents:
- I refactored and wrote some code in Rust for an experimental game logic engine.
- I used agents for the standard development tasks while working on Feeds Fun (Python/TypeScript).
- Like a true hacker, I decided that if I wanted to understand agents, I had to code something related to them. So over the course of a month, I vibecoded Donna — a planner for agents (Python).
Since agents are a new thing:
- No one knows how to use them — we are in the process of gaining experience and gathering use cases.
- No one has broad experience using them — either you choose one or two approaches and use them to do your work, or you endlessly experiment without creating value.
Thus, this post will be in the form of subjective notes and theses.