Top LLM frameworks may not be as reliable as you think
Nearly a month ago, I decided to add Gemini support to Feeds Fun and did some research on top LLM frameworks — I didn't want to write my own bicycle.
As a result, I found an embarrassing bug (in my opinion, of course) in the integration with Gemini in LLamaIndex. Judging by the code, it is also present in Haystack and in the plugin for LangChain. And the root of the problem is in the Google SDK for Python.
When initializing a new client for Gemini, the framework code overwrites/replaces API keys in all clients created before. Because the API key, by default, is stored in a singleton.
It is death-like, if you have a multi-tenant application, and unnoticeable in all other cases. Multi-tenant means that your application works with multiple users.
For example, in my case, in Feeds Fun, a user can enter their API key to improve the quality of the service. Imagine what a funny situation could happen: a user entered an API key to process their news but spent tokens (paid for) for all service users.
I reported this bug only in LLamaIndex as a security issue, and there has been no reaction for 3 weeks. I'm too lazy to reproduce and report for Haystack and LangChain. So this is your chance to report a bug to a top repository. All the info will be below, reproducing is not difficult.
This error is notable for many reasons:
- The assessment of the criticality of the error depends a lot on taste, experience, and context. For me, in the projects I worked on, this is a critical security issue. However, it seems that this is not critical at all for most current projects that use LLMs. Which leads to some thoughts about mainstream near-LLM development.
- This is a good indicator of a low level of code quality control: code reviews, tests, all processes. After all, this is an integration with one of the major API providers. The problem could have been found in many different ways, but none worked.
- This is a good illustration of the vicious approach to development: "copy-paste from a tutorial and push to prod". To make such a mistake, you had to ignore both the basic architecture of your project and the logic of calling the code you are copying.
Ultimately, I gave up on these frameworks and implemented my own client over HTTP API.
My conclusion from this mess is: you can't trust the code under the hood of modern LLM frameworks. You need to double-check and proofread it. Just because they state that they are "production-ready" doesn't mean they are really production-ready.
Let me tell you more about the bug.
Places to discuss Feeds Fun
I continue developing my news reader: feeds.fun. To gather information and people together, I created several resources where you can discuss the project and find useful information:
- Blog blog.feeds.fun
- Discord server
- Reddit r/feedsfun
So far, there is no one and nothing there, but over time, there will definitely be news and people.
If you are interested in this project, join! I'll be glad to see you and will try to respond quickly to all questions.
Simulating public opinion in a game
The demonstration (in Russian) of a technical prototype of manipulating public opinion and explanation of how it works.
I continue participating in World Builders school. For the last month, I've created a technical prototype of game mechanics for manipulating public opinion.
You play as the chief editor of a news agency, who sends journalists on quests and publishes articles based on the results of investigations focusing on themes that you want to promote.
The top video is in Russian, so I'll go through the main points below.
Cleaning up the results of the strategy players survey
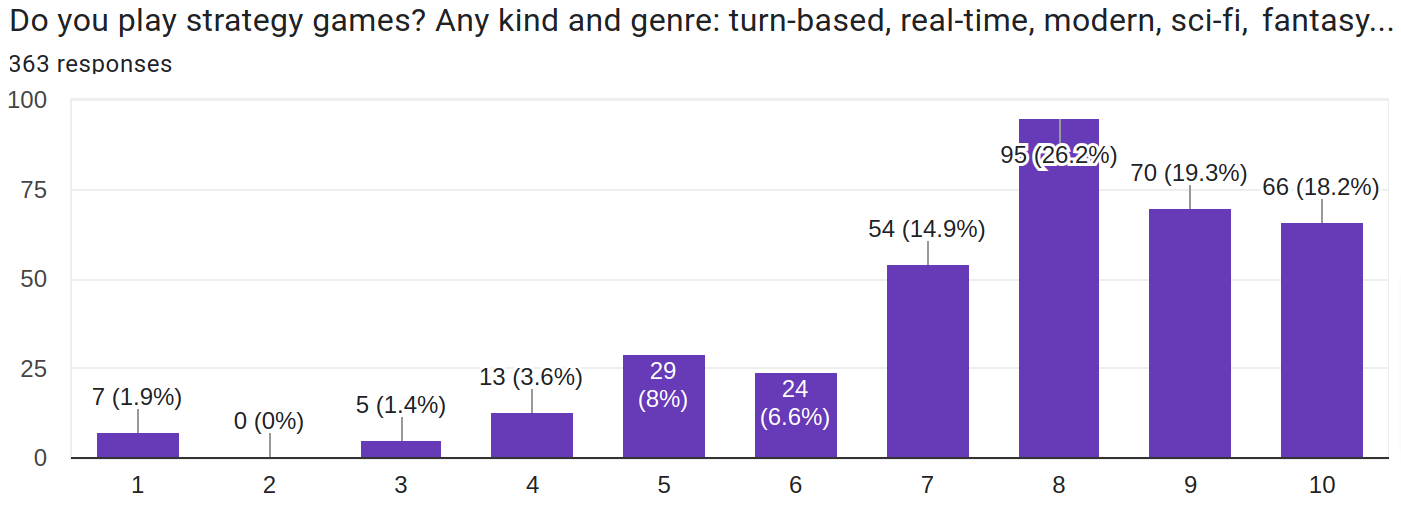
The survey was targeted at the fans of strategy games. It seems, I was able to find audience quite accurately.
Recently I asked you to fill in a survey about strategy games.
Thank you to everyone who took the time to do this. It's time to share the results.
363 respondents filled in the survey. 304 answers remained after data normalization and cleaning.
There will be two posts:
- This one — about the methodology of data collection and processing, and their cleaning. Cleaned data will be shared.
- The next one — about the analysis of the results.