Feeds Fun — читалка новостей с тегами и ChatGPT
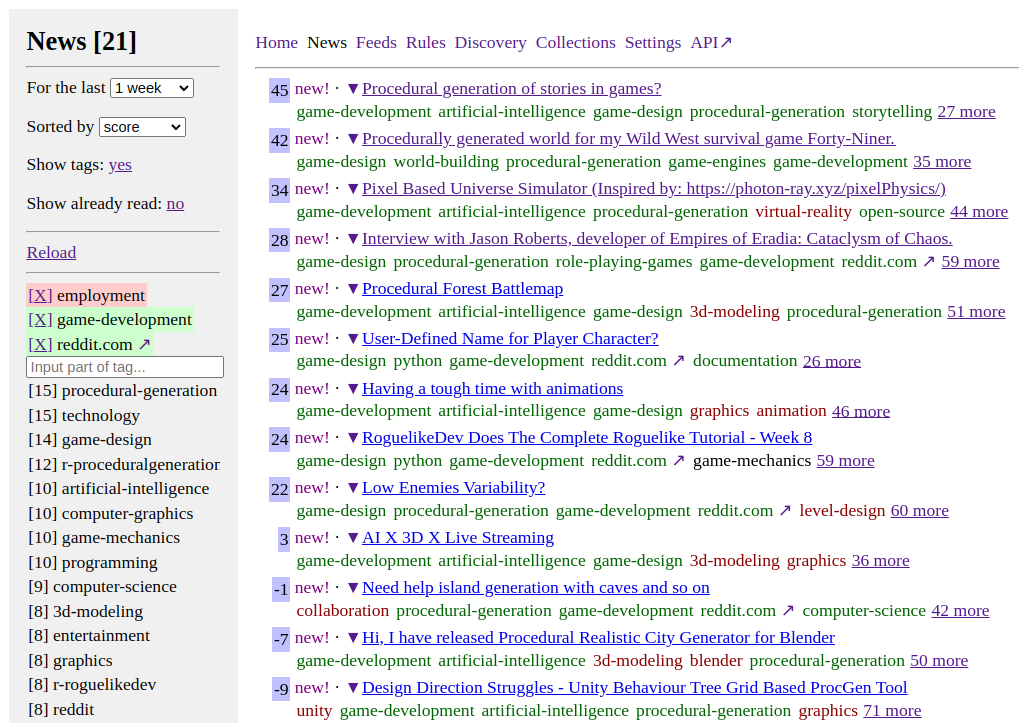
Выглядит неприглядно, но это временно.
Задержался с постом, а между тем читалка уже работает и экономит мне 4-8 часов в неделю.
Для нетерпеливых и ленивых:
- Репозиторий: github.com/tiendil/feeds.fun
- Сайт: feeds.fun — заходите, подписывайтесь на подготовленные коллекции новостей, экспериментируйте.
Суть:
- Читалка автоматически определяет теги для каждой новости. Тут очень кстати пришлась ChatGPT.
- Вы создаёте правила в духе
elon-musk & twitter => score -100500,procedural-content-generation & hentai => score +13. - В интерфейсе сортируете новости по интересности и читаете только самые-самые именно для вас.
Если есть просьбы по фичам — создавайте issue, постараюсь воплощать. Хочется, чтобы штука пошла в народ.
Реализация Generative Adversarial Network
В завершение разбирательства с Deep Learning решил посмотреть что-нибудь более интересное и ориентированное на генерацию контента — реализовать GAN.
По правде говоря, большую часть времени с GAN (и Autoencoder) я экспериментировал на спрайтах карты Сказки. Ожидаемо, на таком мизере обучающих данных ничего интересного не получилось. Хотя польза и была. Поэтому для поста я подготовил отдельный notebook с более наглядными результатами — генерацией обуви по набору данных Fashion MNIST.
Ноутбук с реализацией GAN и комментариями.
Про архитектуру GAN лучше почитать в вики, интернетах или моём ноутбуке.
Краткая суть:
- Тренируются две сети: generator & discriminator.
- Генератор учится создавать картинки из шума.
- Дискриминатор учится отличать поддельные картинки от настоящих.
- Ошибка дискриминатора определяется качеством предсказания фейковости изображения.
- Ошибка генератора определяется качеством обмана дискриминатора.
Если правильно подобрать топологии сетей и параметры обучения, то в итоге генератор научается создавать картинки неотличимые от оригинальных. ??????. Profit.
Kaggle: Digit Recognizer (MNIST) точность 0.99585

Примеры цифр из набора MNIST.
Продолжаю путешествие по занимательным землям Deep Learning.
В прошлый раз я учился заводить deep learning на локальной машине и делал совсем детскую, искусственную и неспецифическую для DL задачу.
В этот раз решил попробовать что-то более диплёрничное — научиться решать задачи на Kaggle. Есть предположение, что Kaggle — самый простой и интересный способ учить DL.
На этом сервисе есть задачи для новичков, одну такую — Digit Recognizer — я выбрал для тренировки. Соревнование по распознаванию рукописных цифр из набора MNIST. Этот набор должны были встречать даже люди далёкие от ML.
Notebook с решением и комментариями опубликован на github.
На момент отправки решение занимало 467 место из ~7000. На мой взгляд неплохой результат, учитывая, что первые мест 150 занимают читерские решения. MNIST — общедоступный набор данных, их можно скачать вне kaggle и залить в качестве решения готовые ответы, или переобучить сеть на полном наборе.
Нельзя просто так взять и запустить Deep Learning

Продолжаю разбираться с Deep Learning.
Решил попробовать его на практике: сам придумал лабу, сам сделал, сам себя похвалил.
Целью было построить простейшую, но более-менее полную цепочку обучения модели с помощью Keras+TensorFlow и запустить её на своей машине.
Публикую notebook с выполненной лабой, комментариями о базовых штуках, костылях и нюансах. Надеюсь, будет полезна новичкам. Может быть меня даже поругает кто-нибудь из опытных датасаентистов.
А в этом посте покритикую инфраструктуру всего этого.
Pydicates: предикаты для Python
Опубликовал небольшую библиотеку для работы с предикатами в Python: github, pypi. Как всегда, под BSD-3.
Позволяет конструировать функции для отложенных вычислений. Например, описывать такие условия: (OwnedBy('alex') | OwnedBy('alice')) & HasTag('game-design').
Делал для себя, так как уже несколько раз в пет-проектах писал костыли для этого дела. Решил сделать один раз правильно и больше не тратить на это время.
Минимальный пример:
from pydicates import Predicate, common
def HasTag(tag):
return Predicate('has_tag', tag)
def has_tag(context, tag, document):
return tag in document['tags']
common.register('has_tag', has_tag)
document = {'tags': ('a', 'b', 'c', 'd')}
assert common(HasTag('a') & HasTag('c'), document)
assert not common(HasTag('a') & HasTag('e'), document)
assert common(HasTag('a') & ~HasTag('e'), document)
assert common(HasTag('a') & (HasTag('e') | HasTag('d')), document)Больше примеров можно найти в репозитории ./examples
API описано чуть подробнее в ./examples/documents_check.py
Больше примеров можно найти в тестах.