Топовые LLM фреймворки могут быть не так надёжны, как вы думаете
Месяц назад решил добавить поддержку Gemini в Feeds Fun и под это дело изучал топовые LLM фреймворки — писать свой велосипед не хотелось.
В итоге нашёл стыдный баг в интеграции с Gemini в LLamaIndex. Судя по коду, он есть и в Haystack и в плагине для LangChain. А корень проблемы вообще в SDK Google для Python.
При инициализации нового клиента для Gemini код фреймворка перетирает/подменяет API ключи во всех клиентах, созданных до этого. Потому что API ключ, по-умолчанию, хранится в синглетоне.
Смерти подобно, если у вас multi-tenant приложение, и незаметно во всех остальных случаях. Multi-tenant — это когда ваше приложение работает с несколькими пользователями.
Например, в моём случае, в Feeds Fun пользователь может ввести свой API ключ, чтобы улучшить качество сервиса. Представьте какой забавный казус мог бы случиться: пользователь ввёл API ключ для обработки своих рассылок, а потратил токенов (заплатил) за всех пользователей сервиса.
Репортил только в LLamaIndex как security issue и уже 3 недели ноль реакции, для Haystack и LangChain лень воспроизводить. Так что это ваш шанс зарепортить багу в топовый репозиторий. Под катом будет вся инфа, воспроизвести не сложно.
Ошибка примечательна многим:
- Оценка критичности ошибки очень зависит от вкусовщины, опыта и контекста. Для меня, в проектах в которых я работал, — это критическая ошибка безопасности. Но, похоже, для большинства актуальных проектов, которые используют LLM, это вообще не принципиально. Что навевает некоторые мысли о мейнстрим около-LLM разработках.
- Это хороший индикатор низкого уровня контроля качества кода: код ревью, тестов — всех процессов. Всё-таки это интеграция с одним из топовых провайдеров API, найти проблему можно было кучей разных способов, но ни один не сработал.
- Это хорошая иллюстрация порочного подхода к разработке: «копипастим из туториала и льём на прод». Чтобы допустить эту ошибку нужно было проигнорить одновременно и базовую архитектуру твоего проекта и логику вызова кода, который ты копипастишь.
В итоге я забил на эти фреймворки и впилил свой костыль, благо HTTP API для Gemini есть.
Мой вывод из этого безобразия такой: доверять коду, который под капотом у современных LLM фреймворков нельзя. Надо перепроверять, вычитывать. То, что у них написано «production ready», не значит, что они действительно production ready.
Далее расскажу подробнее про сам баг.
Мигрируем с GPT-3.5-turbo на GPT-4o-mini
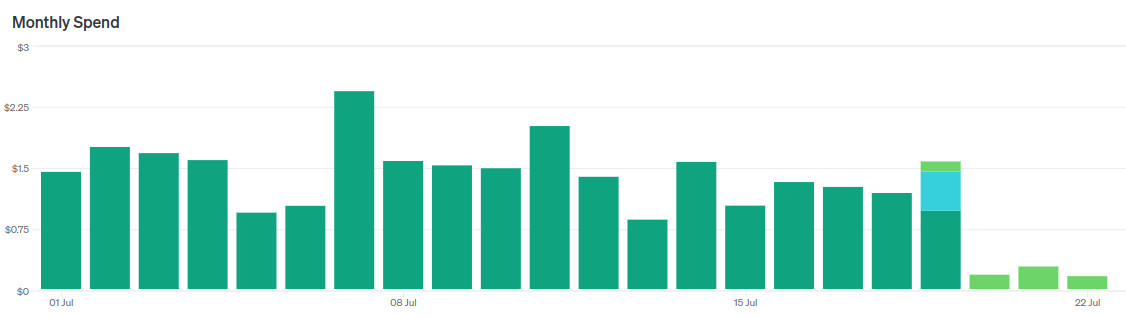
Угадайте когда я переключил модели.
На днях OpenAI выпустила GPT-4o-mini — новую флагманскую модель для дешёвого сегмента, так сказать.
- Говорят, работает «почти как» GPT-4o, а иногда даже круче GPT-4.
- Почти в 3 раза дешевле GPT-3.5-turbo.
- Размер контекста 128k токенов, против 16k у GPT-3.5-turbo.
Конечно я сразу побежал переводить на эту модель свою читалку новостей.
Если кратко подвести итоги, то это крутая замена GPT-3.5-turbo. У меня получилось сходу, не меняя промпты, заменить двух LLM агентов на одного и суммарно удешевить работу читалки раз в 5 без потери качества.
Но потом я полез тюнить промпт, чтобы сделать ещё круче, и начал сталкиваться с нюансами. О них расскажу далее.
Обзор книги «Сигнал и Шум»
Нейт Сильвер — автор «Сигнала и Шума» — широко известен благодаря своим удачным прогнозам, например, выборов в США. Неудивительно, что книга стала бестселлером.
Собственно, прогнозам книга и посвящена: подходам к прогнозированию, сложностям, ошибкам, заблуждениям и так далее.
Как обычно, я рассчитывал на более теоретическое изложение, в духе Масштаба, но автор выбрал другой путь и подаёт свои идеи через разбор конкретных случаев: один случай на главу. Каждая глава описывает большую задачу, например, предсказание погоды, и с помощью неё даёт несколько призм для взгляда на прогнозирование. Это определённо делает материал доступнее, но лично я хотел бы больше системности и теории.
Из-за подхода через изложение кейсов, сделать краткую выдержку из книги сложно. Это возможно, было бы даже интересно попробовать, но объём работы слишком большой — автор не ставил целью свести всё в цельную систему или короткий набор тезисов.
Поэтому дам отзыв на книгу в целом, примерный перечень призм и набор прикольных фактов.
О книге «Piranesi»

Обложка книги «Piranesi»
«Piranesi» одновременно продолжение магических историй Сюзанны Кларк и независимая книга.
Прямой связи с миром английской магии из «Джонатан Стрендж и мистер Норрелл» нет. При большом желании связь можно найти и даже сказать, что мир один и тот же, только в разные времена: события «Piranesi» происходят в начале 2000-ых. Но автор не дала никаких намёков на это. Поэтому я пока считаю, что миры разные.
При этом Сюзанна продолжает очень упорно и результативно копать даже не в сторону анимизма, как основы мировосприятия, а в сторону крайне холистического взгляда на мир, в противовес доминирующему нынче редукционизму.
И от последнего, меня как технаря (а значит интуитивного редукциониста в виду профессиональной деформации), жуть как штырит. Читая «Джонатана Стренджа» и «Piranesi» я ощущал как Кларк, аки Пётр Первый, рубит мне в мозгу окно в другую картину мира, иное мировосприятие. И это прекрасно.
Кстати, не путайте холистику со, скажем, инженерным взглядом на мир, а-ля системной инженерией или даже наукой. Последние про декомпозицию реальности на составные части с чёткими границами и синтез из них «чистых» моделей мира, в то время как холистика про то, что у частей нет чётких границ и они проникают друг в друга.
Но это моя интерпретация, есть интерапретации когда холистика — просто альтернативное название системного мышления/взгляда — сейчас туго с литературой на эту тему, поэтому мне сложно сказать где правда.
Итак, «Piranesi».
Мои GPT-шки и prompt engineering

Понечки занимаются prompt engineering (c) DALL-E
Я пользуюсь ChatGPT практически с момента выхода её четвёртой версии (то есть уже больше года). За это время хорошо набил руку в написании запросов к этой штуке.
В какой-то момент, OpenAI разрешили настраивать свой чат с помощью собственных текстовых инструкций (ищите Customize ChatGPT в меню). Я постепенно дописывал туда команды и вот на днях размер инструкций превысил разрешённый максимум :-)
Плюс, оказалось, что универсальный набор инструкций не получается — под каждую задачу их нужно подстраивать, иначе они не будут так полезны как могли бы быть.
Поэтому покумекав, я решил вместо кастомизации своего чата, вынести инструкции в GPT ботов. OpenAI называют их GPTs, по-русски буду называть их GPT-шками. По-сути, это такие же чаты, в которых больше лимит на кастомизированные инструкции и в них можно залить дополнительные тексты как базу знаниий.
Когда-нибудь, я сделаю GPT-шку для этого блога, а пока расскажу про двух рабочих лошадок, которыми пользуюсь каждый день.
- Expert — ответы на вопросы.
- Abstractor — краткое изложение текста.
Для каждой будет описание базового промпта с моими комментариями.
OpenAI недавно открыла магазин GPT-шек, буду благодарен если пролайкаете мои. Конечно, только если они вам полезны.