Мигрируем с GPT-3.5-turbo на GPT-4o-mini ru en
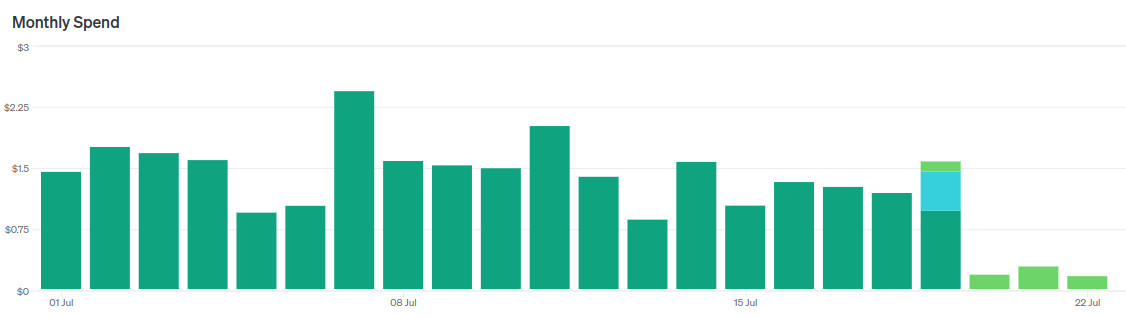
Угадайте когда я переключил модели.
На днях OpenAI выпустила GPT-4o-mini — новую флагманскую модель для дешёвого сегмента, так сказать.
- Говорят, работает «почти как» GPT-4o, а иногда даже круче GPT-4.
- Почти в 3 раза дешевле GPT-3.5-turbo.
- Размер контекста 128k токенов, против 16k у GPT-3.5-turbo.
Конечно я сразу побежал переводить на эту модель свою читалку новостей.
Если кратко подвести итоги, то это крутая замена GPT-3.5-turbo. У меня получилось сходу, не меняя промпты, заменить двух LLM агентов на одного и суммарно удешевить работу читалки раз в 5 без потери качества.
Но потом я полез тюнить промпт, чтобы сделать ещё круче, и начал сталкиваться с нюансами. О них расскажу далее.
Насколько хороша GPT-4o-mini?
Далее, если не указал иное, я буду сравнивать GPT-4o-mini с GPT-3.5-turbo, так как это модели одного ценового сегмента.
В целом, модель однозначно лучше следует инструкциям.
Отлично следует общим инструкциям, которым не нужен контекст. Например, спецификациям формата ответа Allowed tag format: "@word", "@word-word-..." или Output as JSON. У GPT-3.5 (и, возможно, у GPT-3.5-turbo — не проверял отдельно) с этим были сильные проблемы, мне даже пришлось писать код для разбора кривого JSON.
Модель лучше следует алгоритмам сделай 1, сделай 2, сделай 3, как в моих GPT-шках, но далеко не всегда. При некоторых конфигурациях запроса она алгоритм не видит — приходится дополнительно настраивать prompt подбором правильных слов. Выглядит такой тюнинг как гадание на кофейной гуще.
Качество ответов хуже, чем у актуальной GPT-4o. Но не так критически, как у GPT-3.5-turbo.
Особенно заметна проблема с размытием семантики промпта. Модель не забывает ранние инструкции (как это делают более слабые модели), но начинает менее точно их трактовать.
Для примера. Есть промпт:
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
1. Do bla-bla.
Модель даёт отличный ответ на него. Добавляю один шаг:
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
1. Do bla-bla.
2. Do another bla-bla.
Модель следует алгоритму, но выдаёт менее чёткий, менее «профессиональный» результат. В случае тегов это может выражаться, например, в выдаче тега prompts вместо prompt-engineering для новости про промпты в ChatGPT.
Добавляю копию первой инструкции в конец запроса:
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
1. Do bla-bla.
2. Do another bla-bla.
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
Модель восстанавливает качество ответа.
Возможно по той же причине, у модели сложности с большими запросами. Чем больше запрос, тем заметнее каждое его слово размывает контекст и, тем самым, ухудшает ответ. Частично такое размытие тюнится подборкой очень правильных формулировок, но это не всегда помогает и, в целом, не воспроизводимая практика, поэтому советовать её не могу.
Соответственно, ждать комплексных рассуждений или выполнения длинных алгоритмов от GPT-4o-mini всё ещё не стоит. В остальном — огонь.
Читать далее
- Prompt engineering: строим промпты от бизнес кейсов
- Мои GPT-шки и prompt engineering
- Ценообразование на старте монетизации Feeds Fun
- Feeds Fun — читалка новостей с тегами и ChatGPT
- DepMesh — делаем зависимости между файлами частью архитектуры проекта
- Donna готова к использованию
- Donna — предсказуемость и управляемость для ваших агентов
- OpenAI Chat для геймдева
- Используем DALL-E для геймдева
- Заметки про coding agents