Migrating from GPT-3.5-turbo to GPT-4o-mini ru en
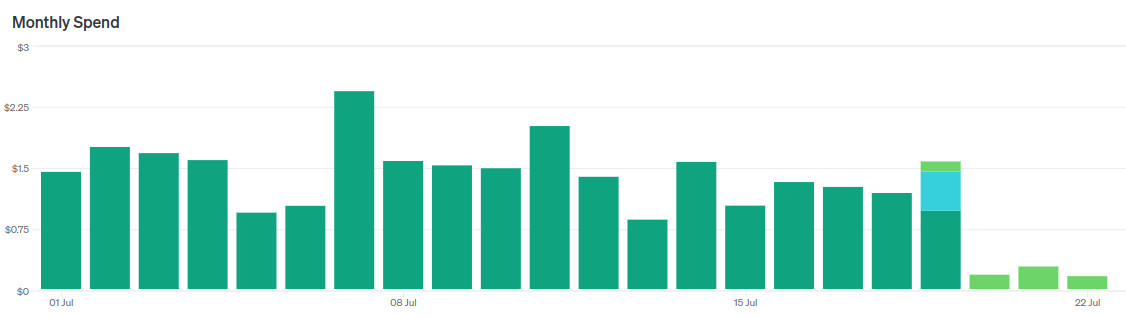
Guess when I switched models.
Recently OpenAI released GPT-4o-mini — a new flagship model for the cheap segment, as it were.
- They say it works "almost like" GPT-4o, sometimes even better than GPT-4.
- It is almost three times cheaper than GPT-3.5-turbo.
- Context size 128k tokens, against 16k for GPT-3.5-turbo.
Of course, I immediately started migrating my news reader to this model.
In short, it's a cool replacement for GPT-3.5-turbo. I immediately replaced two LLM agents with one without changing prompts, reducing costs by a factor of 5 without losing quality.
However, then I started tuning the prompt to make it even cooler and began to encounter nuances. Let me tell you about them.
How good is GPT-4o-mini?
Next, unless otherwise stated, I will compare the GPT-4o-mini with the GPT-3.5-turbo, as they are in the same price segment.
In general, the model definitely follows instructions better.
It follows general instructions (that do not require deep context) excellently. For example, specifications for the response format Allowed tag format: "@word", "@word-word-..." or Output as JSON. GPT-3.5 (and, maybe, GPT-3.5-turbo — I didn't check separately) had severe problems with this, I even had to write code for parsing the broken JSON.
The model better follows algorithms like do step 1, do step 2, do step 3, as in my GPTs, but not always. For some prompt configurations, it doesn't see the algorithm — you have to additionally tune the prompt by selecting the right words. Such tuning looks like fortune-telling on coffee grounds — not very convenient or reliable.
The quality of the answers is worse than for the current GPT-4o but not as critically worse as for GPT-3.5-turbo.
The problem of blurring the semantics of the prompt is especially noticeable. The model does not forget early instructions (as weaker models do) but starts interpreting them less accurately.
For example. There is a prompt:
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
1. Do bla-bla.
GPT-4o-mini gives an excellent answer to it. Let's add one more step:
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
1. Do bla-bla.
2. Do another bla-bla.
The model will follow the algorithm but produce a less precise, less "professional" result. In the case of tags, this can manifest itself, for example, in outputting the tag prompts instead of the prompt-engineering for a news item about prompts in ChatGPT.
But when we add a copy of the first instruction to the end of the prompt:
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
1. Do bla-bla.
2. Do another bla-bla.
You are an expert on semantic analysis, text summarization, and information extraction with PhD in Linguistics.
The model restores the quality of the answer.
Possibly for the same reason, the model has difficulty with large prompts. The larger the prompt, the more noticeable the blurring of the context and reduction in the quality of the answer. This blurring can be partially tuned by selecting precise wordings, but this does not always help and is generally not a reproducible practice, so I cannot recommend it.
So, you still shouldn't expect complex reasoning or a precise execution of long algorithms from GPT-4o-mini. For all other cases, it is excellent.
Read next
- Prompt engineering: building prompts from business cases
- My GPTs and prompt engineering
- Pricing model at the start of Feeds Fun monetization
- DepMesh — making file dependencies part of project architecture
- Donna is ready to use
- Donna — predictability and controllability for your agents
- Notes on coding agents
- LLM agents are still unfit for real-world tasks
- Top LLM frameworks may not be as reliable as you think
- Using DALL-E-3 for Game Development