Процедурные заголовки для новостей без сложной генерации текста
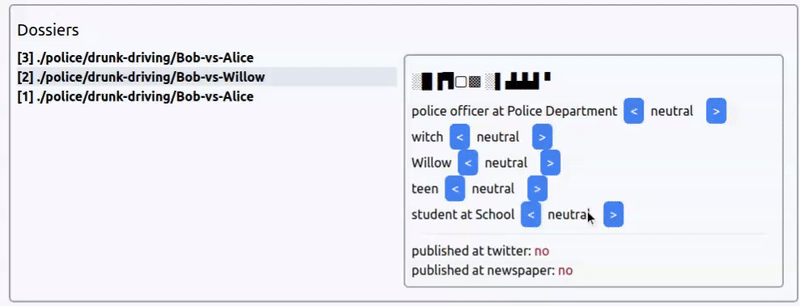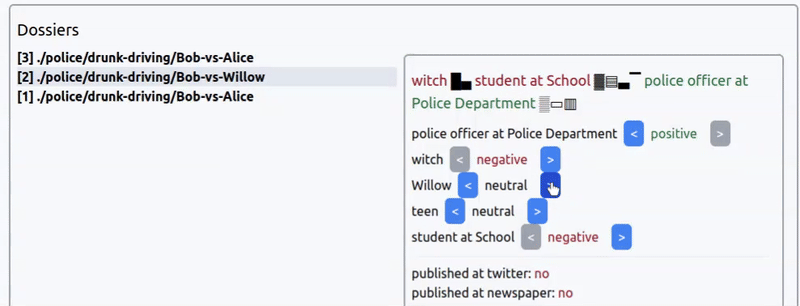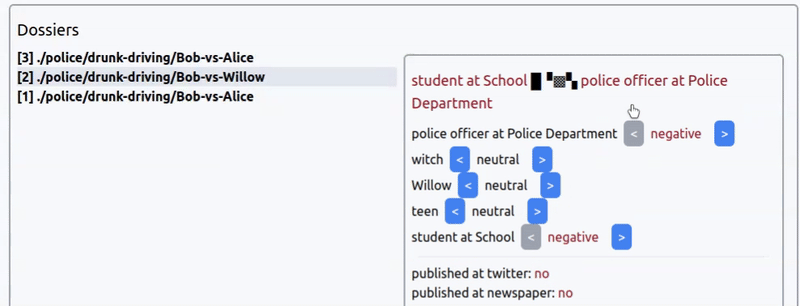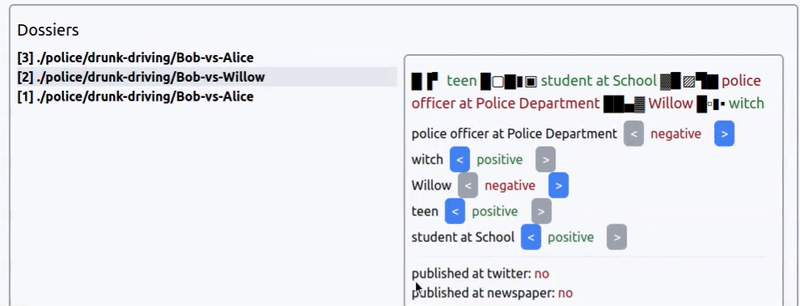
Интерфейс выбора коннотации новости из прототипа игры про агентство новостей. Новость: арест ведьмочки-подростка за пьяное вождение.
От опросов про предпочтения игроков потихоньку перешёл к работе над прототипом игры.
Игра будет про новостное агентсво, где вы — главный редаткор, а ваша задача — манипулировать общественным мнением, расследуя события и выбирая коннотацию новостей: на что обратить внимение публики, что скрыть, в каком тоне преподнести темы, etc.
Поэтому всё действие будет происходить вокруг текста новостей.
Сходу можно сказать, что создавать большие простыни текста для каждой новости нет смысла — игра не про чтение новостей, а про управление ими. Поэтому разумно взаимодействие строить только на заголовках.
Но как сделать отображение новостей одновременно интересным и простым?
Используем DALL-E-3 для геймдева

DALL-E: "Draw a Vrubel-style painting of an indie game developer working on her game, like The Demon Seated. With the accent on Vrubel style."
Получил доступ к DALL-E-3, а значит можно повторить прошлогодний эксперимент и посмотреть что изменилось.
Фантазировать, искать новые направления пока не буду, повторим идеи и запросы из прошлогоднего поста.
Осторожно, много трафика — DALL-E отдаёт png файлы размером 1-2 мегабайта. Я их немного пожал, но пост всё равно будет тяжёлым.
Делаем простой ИИ тамагочи на ChatGPT

DALL-E: Screenshot of a hamster from a game simulating artificial life, similar to the Creatures game.
Обсуждали с коллегами что ещё может современный ИИ, вспомнили про тамагочи и всякую искусственную жизнь.
Поболтали и разошлись, а я пошёл и за 15 минут получил вот такой результат.
Тюнить и украшать вывод не буду — уже есть куча примеров как получать чистый код от ботов. В данном случае интересна сама демонстрация возможности.
Спойлер: с ChatGPT не надо тратить время на разработку ИИ простых ботов, сеть подстроится под ваши требования. Просто скажите кем ChatGPT должна притвориться.
Этот пост неявно продолжает размышления из Write Your Own Adventure.
Используем DALL-E для геймдева

DALL-E: "Vrubel-style painting of an indie game developer working on her game, like The Demon Seated."
Получил доступ к DALL-E и попробовал применить его к чему-нибудь полезному — геймдеву. В конце-концов, к чему ещё прикручивать процедурную генерацию.
Сначала тезисно расскажу об общих впечатлениях, а потом посмотрим для чего в геймдеве можно использовать этот инстрмент прямо сейчас. А для чего пока не получится.
Осторожно, много трафика — DALL-E отдаёт png файлы размером 1-2 мегабайта. Я немного пожал их, но качество старался сохранить на максимуме, поэтому картинки всё-равно тяжёлые.
Больше новостей о процедурной генерации

Примеры генерации 3D модели по запросу "A capybara made of voxels sitting in a field"
На этот раз Open AI рассказали о новой нейронке (на русском) а-ля GPT-3, но для изображений. Пример её работы можно видеть на заглавной картинке. Изображения сформированы для фразы «A capybara made of voxels sitting in a field» (капибара из вокселей, которая сидит в поле).
На странице с анонсом можно посмотреть другие примеры работ, включая разные способы изображения (3D рендер, изометрию, низкополигональные модели, etc).
Результаты, конечно, кривоваты. Но, надо учесть два нюанса:
- Это первый подход к подобной архитектуре с подобными деньгами.
- Это сеть общего назначения, не натасканная на геймдев.
А вот если бы её допилить, специализировать на фэнтези, да подключить к Сказке… Но у меня столько денег нет :-) А у кого-нибудь обязательно найдутся.
Постепенно вырисовывается новый пайплайн для арта:
- нейронка для постановки задания;
- нейронка для генерации контента;
- нейронка для устранения неточностей на картинке;
- нейронка для стилизации;
- нейронка для вылизывания;
- нейронка для выделения 3D меша;
- нейронка для оптимизации меша;
- нейронка для анимации;
Интеграция контента, позиционирование камер, цвет, свет, звук и прочее — тоже нейронки. Ну вы поняли :-D
Товарищи, которые научатся делать эти лопаты, сорвут большой куш.