Топовые LLM фреймворки могут быть не так надёжны, как вы думаете
Месяц назад решил добавить поддержку Gemini в Feeds Fun и под это дело изучал топовые LLM фреймворки — писать свой велосипед не хотелось.
В итоге нашёл стыдный баг в интеграции с Gemini в LLamaIndex. Судя по коду, он есть и в Haystack и в плагине для LangChain. А корень проблемы вообще в SDK Google для Python.
При инициализации нового клиента для Gemini код фреймворка перетирает/подменяет API ключи во всех клиентах, созданных до этого. Потому что API ключ, по-умолчанию, хранится в синглетоне.
Смерти подобно, если у вас multi-tenant приложение, и незаметно во всех остальных случаях. Multi-tenant — это когда ваше приложение работает с несколькими пользователями.
Например, в моём случае, в Feeds Fun пользователь может ввести свой API ключ, чтобы улучшить качество сервиса. Представьте какой забавный казус мог бы случиться: пользователь ввёл API ключ для обработки своих рассылок, а потратил токенов (заплатил) за всех пользователей сервиса.
Репортил только в LLamaIndex как security issue и уже 3 недели ноль реакции, для Haystack и LangChain лень воспроизводить. Так что это ваш шанс зарепортить багу в топовый репозиторий. Под катом будет вся инфа, воспроизвести не сложно.
Ошибка примечательна многим:
- Оценка критичности ошибки очень зависит от вкусовщины, опыта и контекста. Для меня, в проектах в которых я работал, — это критическая ошибка безопасности. Но, похоже, для большинства актуальных проектов, которые используют LLM, это вообще не принципиально. Что навевает некоторые мысли о мейнстрим около-LLM разработках.
- Это хороший индикатор низкого уровня контроля качества кода: код ревью, тестов — всех процессов. Всё-таки это интеграция с одним из топовых провайдеров API, найти проблему можно было кучей разных способов, но ни один не сработал.
- Это хорошая иллюстрация порочного подхода к разработке: «копипастим из туториала и льём на прод». Чтобы допустить эту ошибку нужно было проигнорить одновременно и базовую архитектуру твоего проекта и логику вызова кода, который ты копипастишь.
В итоге я забил на эти фреймворки и впилил свой костыль, благо HTTP API для Gemini есть.
Мой вывод из этого безобразия такой: доверять коду, который под капотом у современных LLM фреймворков нельзя. Надо перепроверять, вычитывать. То, что у них написано «production ready», не значит, что они действительно production ready.
Далее расскажу подробнее про сам баг.
Считаем бизнес-план для игры в Steam
Заработать миллионы проще простого, сейчас расскажу как :-D
Когда выкладывал отчётную презентацию (слайды) по World Builders 2023 (мои посты, сайт), обещал рассказать как делал roadmap и финансовую модель для игры. Выполняю обещание.
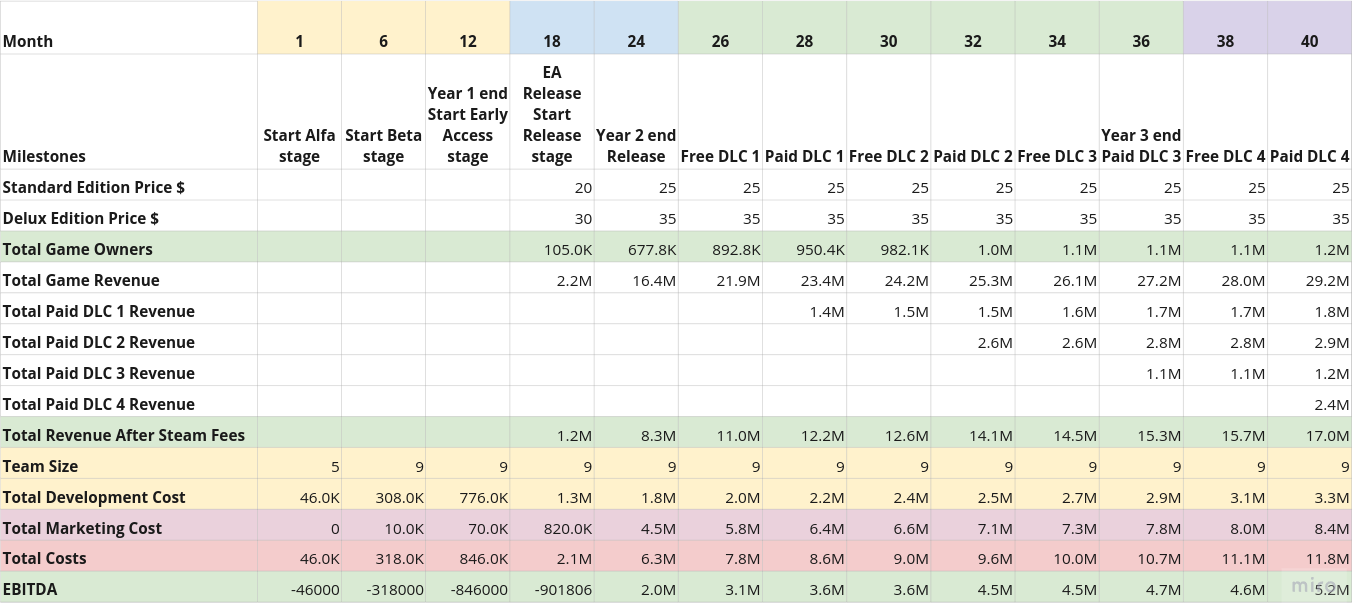
К концу поста у нас на руках будут:
- Краткая стратегия нашей компании: что мы делаем, как, зачем и почему.
- Табличка наших маяков — успешных игр, которые примерно похожи на то, что мы хотим сделать. Похожи как по геймплею, так и по размеру команды, бюджету, etc.
- Состав команды, которую нам надо собрать.
- Roadmap — план разработки нашей игры.
- Зачатки маркетинговой стратегии.
- Финансовая модель — сколько мы будем тратить, сколько зарабатывать.
- Огромное количество моих оговорок по всему посту.
- Шутки и прибаутки.
Все итоговые документы вы можете найти тут.
Мигрируем с GPT-3.5-turbo на GPT-4o-mini
Угадайте когда я переключил модели.
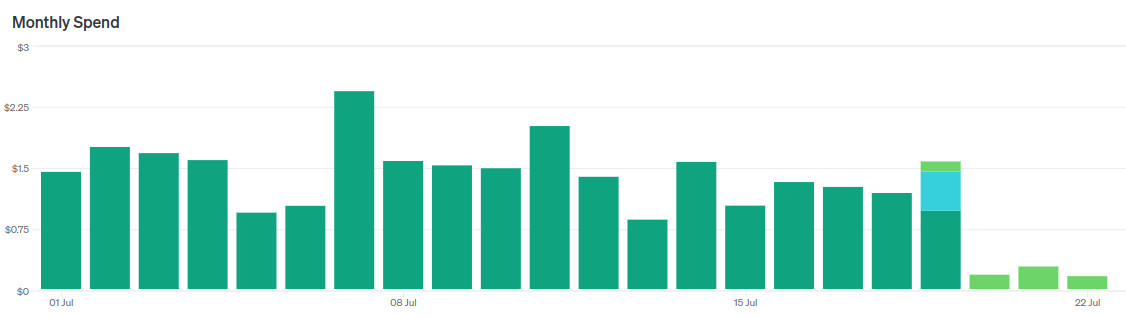
На днях OpenAI выпустила GPT-4o-mini — новую флагманскую модель для дешёвого сегмента, так сказать.
- Говорят, работает «почти как» GPT-4o, а иногда даже круче GPT-4.
- Почти в 3 раза дешевле GPT-3.5-turbo.
- Размер контекста 128k токенов, против 16k у GPT-3.5-turbo.
Конечно я сразу побежал переводить на эту модель свою читалку новостей.
Если кратко подвести итоги, то это крутая замена GPT-3.5-turbo. У меня получилось сходу, не меняя промпты, заменить двух LLM агентов на одного и суммарно удешевить работу читалки раз в 5 без потери качества.
Но потом я полез тюнить промпт, чтобы сделать ещё круче, и начал сталкиваться с нюансами. О них расскажу далее.
Предпочтения игроков в стратегии

Смотрим на данные опроса и пытаемся найти что-нибудь полезное.
Недавно я делал опрос о предпочтениях игроков в стратегии.
В предыдущем посте мы очищали данные, в этом попробуем чего-нибудь в них найти.
В посте вы найдёте «интерактивный исследовательский стенд» с кучей графиков, на которых можно смотреть разницу между двух выборок на ваш выбор. Выборок много — на любой вкус и цвет, поэтому щелкать можно долго — делитесь в Telegram и Discord найденными закономерностями.
Но будьте аккуратны с выводами. Данных мало, а в некоторых случаях совсем мало. Например, разница между размерами выборок мужчин и женщин примерно десятикратная => интерпретировать отличия между ними следует очень осторожно.
В целом, не воспринимайте этот пост как полноценное исследование. Уверен, многие аналитики мне бы руки за такое оторвали. Пришили и снова оторвали. Пользуйтесь постом как интерфейсом к данным, а выводы делайте свои.
Чистим результаты опроса игроков в стратегии
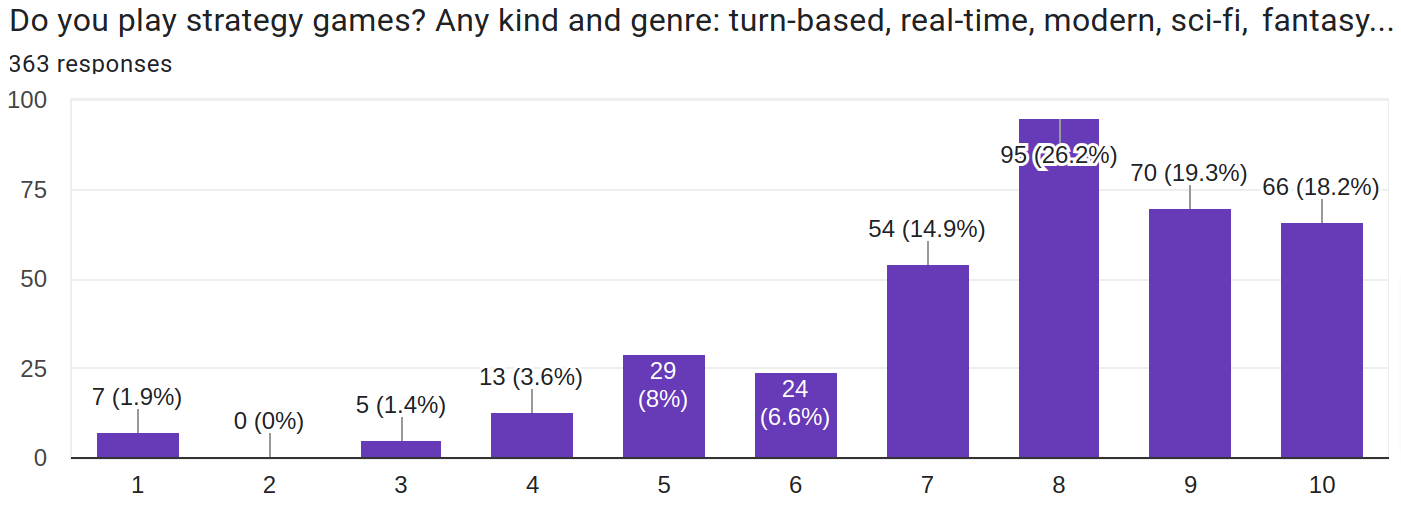
Опрос был нацелен на любителей стратегических игр, удалось попасть достаточно точно.
Недавно просил вас пройти опрос о стратегических играх.
Спасибо всем, кто уделил этому время. Пора делиться результатами.
Было заполнено 363 анкеты. После нормализации и очистки данных осталось 304.
Будет два поста:
- Этот — о методике сбора и обработки данных, их очистке. Будут пошарены очищенные данные.
- Следующий — об анализе результатов.