Справочник по веб-разработке
Обратите, пожалуйста, внимание, что этот текст последний раз обновлялся в 2015 году и в некоторых местах может быть устаревшим.
Вступление
За всё время работы в области веб-разработки так и не увидел хорошего вводного текста, объясняющего новичкам что к чему, вводящего в предметную область. Человек, решивший заняться разработкой сайтов (к примеру), должен побираться по гуглу в поисках крох информации. Единственное, что можно найти, это различного качества материалы вида «HTML и JavaScript за 2 часа», или «Введение в PHP и MySQL». Всё это есть плохо.
Веб — это совокупность стандартов, соглашений, подходов, которые не ограничиваются и не определяются языками программирования или каким-то конкретным софтом. Что бы нормально работать в этой области (как и в любой другой), необходимо ориентироваться в принципах на которых она построена.
Поэтому в этом тексте не будет программного кода, примеров конфигурации софта и прочей ерунды.
Вместо этого будет максимально лаконично представлена информация о том, что в принципе можно ожидать от технологии веба, что в нём можно делать и каким образом это можно делать. Любые пояснения, по возможности, будут даваться в виде ссылок на википедию и аналогичные ресурсы (прочтение материалов по ссылкам очень желательно обязательно). Ссылки даются на русскоязычные ресурсы, но в некоторых случаях следуют обращаться к их англоязычным аналогам (например, английской википедии), так как они содержат больше информации.
Данный «учебник» отражает ситуацию с моей колокольни и не претендует на объективность и охват всей области веб разработки. По поводу исправления ошибок или дополнений смело связывайтесь со мной любым удобным вам способом.
Как оно всё работает (в общем)
Перед дальнейшим чтением убедитесь, что вы знаете, что такое клиент, сервер и браузер.
Традиционно выделяют несколько сфер ответственности в веб-разработке:
- front-end — разработка непосредственно самих страниц сайта, того, с чем работает пользователь;
- back-end — разработка «невидимой» для пользователя серверной инфраструктуры, которая предоставляет функциональность и данные для front-end;
- middle-end — иногда, когда back-end уходит слишком далеко от front-end, появляются компоненты, которые «ни рыба ни мясо». Иногда их называют middle-end.
Рассмотрим подробнее каждую часть и процесс их взаимодействия. Но сначала…
Протоколы передачи данных
Любые взаимодействия программных компонент осуществляются не просто так, а по протоколам. Протокол — это договорённость между несколькими сущностями о том, как и что должно происходить при их совместной работе. Нас, в первую очередь, будут интересовать протоколы передачи данных.
Основной протокол для веб-разработчика — HTTP. По нему, например, браузеры запрашивают страницы сайтов. Но этим его применение не ограничивается.
Кроме HTTP, полезно знать о существовании других протоколов:
- HTTPS — то же, что и HTTP, но шифрованное;
- FTP — передача файлов;
- POP и SMTP — работа с почтой;
- TCP и UDP — протоколы обмена данными более низкого уровня;
Протоколы передачи данных принято делить на уровни. Протоколы более высокого уровня работают с помощью протоколов более низкого уровня. Например HTTP обычно работает поверх TCP.
Как браузер получает страницу сайта
Когда мы вбиваем в браузере адрес страницы, наш компьютер не шлёт запрос напрямую серверу, на котором находится сайт. Этот процесс более сложен:
- Первым делом необходимо по имени сайта (его доменному имени) узнать IP-адрес сервера. Делается это с помощью обращения к системе доменных имён (DNS). Обычно адрес DNS-сервера прописан (или установлен автоматически) в настройках подключения к интернету.
- Зная IP-адрес, мы по протоколу HTTP (обычно) обращаемся к серверу с просьбой отдать нам код страницы.
- Наши сообщения не идут прямо к серверу, вместо этого они передаются через последовательность устройств, управляющих потоками данных в сетях: начиная от вашей точки доступа, заканчивая маршрутизаторами вашего провайдера и более серьёзными системами, соединяющими сегменты интернета.
- В общем случае протокол HTTP не гарантирует, что ваш запрос будет обработан сервером. Вместо этого один из промежуточных узлов, в целях оптимизации нагрузки на сервер или объёма трафика в сети, может вернуть сохранённый ранее ответ на аналогичный запрос (см. кэширование). Об этом обязательно необходимо помнить — в некоторых случаях, запрос может даже не уйти из браузера.
- Если запрос дошёл до сервера, тот анализирует его, выполняет соответствующую программу и возвращает ответ.
Как браузер отображает страницу сайта (front-end)
Отображая страницу пользователю, браузер имеет дело со следующими типами информации:
- описание структуры страницы в формате HTML (в этом описании указываются ссылки на все остальные ресурсы);
- статические файлы (в основном картинки);
- стили CSS (описание оформления внешнего вида страницы);
- код JavaScript (реализация динамического поведения страницы).
Обработка страницы начинается ещё во время загрузки. В частности, по мере загрузки HTML кода:
- начинается загрузка прочих ресурсов, указанных в коде страницы (файлы со стилями, кодом JavaScript, картинками и прочим), они могут загружаться как параллельно с кодом страницы, так и последовательно (блокируя загрузку станицы до окончания загрузки ресурса);
- браузер сразу начинает выполнять загруженный JavaScript код, который, помимо прочего, может дописывать новую информацию (HTML/CSS/JavaScript код) в ещё незагрузившуюся страницу (такая практика сейчас используется редко).
Загружая страницу, браузер строит представление документа в виде DOM, которым может оперировать JavaScript и на которое распространяется влияние CSS стилей.
Поведение страницы (включая выполнение JavaScript кода) управляется событиями. В частности, события шлются по таким поводам, как окончание загрузки страницы, картинки или нажатие на ссылку.
Как сервер формирует страницу сайта (back-end)
В обработке запроса пользователя на стороне сервиса (например, сайта) может участвовать более одной машины, поэтому называть всю инфраструктуру «сервером» не совсем корректно.
В общем случае, обработка запроса пользователя будет происходить в следующем порядке (в реальных проектах некоторые пункты могут отсутствовать):
- В самом начале запрос попадает в систему балансировки нагрузки (если она есть), которая позволяет распределить поток запросов от пользователей на несколько физических серверов. Это позволяет выдерживать бОльшие нагрузки и сокращать среднее время ответа пользователю.
- Тут может быть система кэширования.
- Попадая на физический сервер, запрос проходит по цепочке программных серверов, которые могут его частично преобразовывать. Несколько серверов в цепочке может быть необходимо для оптимальной обработки разных типов запросов: одни сервера лучше и быстрее отдают статическую информацию (изображения и прочие файлы), другие удобны при обработке HTTP запросов. Сервер имеет достаточно свободы в обработке запроса:
- может отказать в обработке, вернув ошибку (например, если запрос не верен или у пользователя нет прав для запросов такого типа);
- перенаправить запрос по другому адресу;
- вернуть результат предыдущего ответа на аналогичный запрос (сохранённый в кэше);
- выполнить соответствующий запросу программный код и вернуть результат пользователю.
- Тут может быть система кэширования.
- Обработка запроса непосредственно конечной программой. Обычно её можно разделить на несколько этапов:
- разбор запроса (определение его типа, особых параметров и прочего) и поиск функции, отвечающей за обработку непосредственно данного запроса;
- проверка прав пользователя на проведение запроса;
- сбор данных (сюда входит обращение к базе данных, системам кэширования и другим сервисам);
- обработка данных (включая изменения информации в базе данных, кэше и т.п.);
- формирование и отправка ответа (в случае с веб-сайтом, это генерация html кода страницы).
HTTP (подробнее)
HTTP — HyperText Transfer Protocol — протокол передачи гипертекста.
Для ознакомления с темой желательно прочитать минимум статью на википедии, а лучше соответствующие RFC для разных версий протокола:
Что необходимо знать:
- протокол является одним из наиболее распространённых способов передачи данных через сеть;
- используется далеко не только для «передачи гипертекста», но во многих других случаях, в частности:
- работа протокола завязана на взаимодействие с абстрактным ресурсом (файлом, программой или чем-то ещё), на который указывает URI (не путать с URL — это немного разные вещи);
- протокол не предполагает сохранение промежуточного состояния между парами «запрос-ответ», это ограничение обходят несколькими способами:
- всегда передавая всю необходимую информацию (обычно используется, если не предполагаются длительные последовательности операций и нет дополнительных требований к безопасности передачи данных);
- реализуя хранение вспомогательной информации на стороне клиента и сервера и передавая только уникальный идентификатор, по которому общающиеся сущности могут её гарантированно извлечь из своих хранилищ (обычно используется для организации сессий при работе с сайтами из браузера);
- запрос и ответ сервера обычно содержат несколько «заголовков» (список всех заголовков), содержащих различного рода вспомогательную информацию. Вот несколько наиболее часто используемых из них:
- Content-Encoding — кодировка данных;
- Content-Type — формат данных;
- Referer — URI ресурса, после которого клиент сделал текущий запрос (говоря о сайтах, это страница с которой пришёл пользователь);
- User-Agent — строка, идентифицирующая тип клиента.
- существует несколько методов запросов, каждый из которых отличается особым поведением. Основные методы для веб-разработчика, это GET и POST:
- GET — запрос содержимого указанного ресурса (получение данных);
- POST — передач пользовательских данных заданному ресурсу (изменение данных);
- каждый ответ сервера содержит код состояния, описывающий результат обработки запроса. Наиболее часто встречающиеся коды:
- 200 — запрос обработан успешно;
- 301/302 — ресурс перемещён навсегда/временно;
- 400 — неверный запрос;
- 404 — ресурс не найден;
- 500 — внутренняя ошибка сервера;
- 503 — сервис недоступен;
- Ку́ки (cookies) — небольшой фрагмент данных, отправляемый каждый раз клиентом и сервером и хранимый на стороне клиента. Используется для хранения данных на стороне пользователя. С помощью этого механизма обычно реализуются:
- аутентификация;
- хранение настроек;
- отслеживания сессии;
- ведение статистики.
Общие проблемы разработки
безопасность
Один из самых важных нюансов веб-разработки это (в общем случае) то, что:
- сервер не может доверять клиенту;
- клиент не может доверять серверу;
- оба не могут доверять пути, по которому идут данные между ними.
Поэтому в обязательном порядке следует руководствоваться следующими правилами:
- всегда проверять данные, пришедшие от клиента;
- всегда проверять данные, пришедшие от сервера;
- никогда не хранить на сервере в открытом виде важные данные пользователя (пароль, номер кредитки) или данные позволяющие получить к ним доступ (секретный вопрос);
- если возможно, вообще не хранить у себя важные данные пользователя;
- всегда передавать важные данные между клиентом и сервером только по защищённым каналам (HTTPS);
Следствием этих правил являются ограничения, касающиеся различных аспектов веб-разработки. Например:
- Same Origin Policy — ограничения, налагаемые на код JavaScript, выполняющийся в браузере;
- Sender Policy Framework — расширение для протокола отправки электронной почты через SMTP, для проверки не подделан ли домен.
Сюда же можно отнести различные проблемы с соблюдением негласных соглашений между клиентом и сервером: негарантированность соблюдения форматов передачи данных (вплоть до различия в разделителях дробной и целой частей в числах), расхождение в значениях (например, время у клиента и сервера может отличаться и непредсказуемо изменяться).
Следует обратить внимание на тип взаимодействия программного сервера непосредственно с кодом обработчиков. Современные версии серверов обычно загружают код один раз (например, при обработке первого запроса), поэтому необходимо следить, чтобы данные от старого запроса не влияли на обработку нового (запросы могут быть от разных пользователей!).
задержки и длительные операции
Во время обработки типичного запроса клиента к серверу возникает масса задержек:
- при передаче данных от клиента серверу и обратно задержка определяется качеством канала между ними;
- сбор данных для ответа предполагает обращение к различным источникам (база данных, система кэширования), запросы к которым так же происходят не мгновенно;
- некоторые алгоритмы обработки данных могут занимать существенное время;
- генерация ответа так же может предполагать создание сложной структуры данных, которая также формируется не сразу (особенно, если возвращается большой объём информации);
Задержки влияют не только на удовлетворённость пользователя, от них также сильно зависит производительность вашего сервера (количество обрабатываемых запросов в единицу времени).
Бороться с задержками можно разными способами:
- введением кэширования на разных уровнях, чтобы возвращать ответ на запрос без прохождения всего пути обработки или экономить на обращении к сторонним источникам данных;
- оптимизацией алгоритмов обработки данных и генерации ответа;
- вынесением длительных операций в фоновую обработку, чтобы не задерживать обработку запросов от других пользователей (в этом случае пользователь, вызвавший длительную операцию, периодически опрашивает сервер, проверяя её статус).
параллелизм
Сервер может одновременно обрабатывать несколько запросов, как от разных пользователей, так и от одного. Поэтому необходимо постоянно помнить о проблемах параллельной обработки данных:
Необходимо следить за работой систем, ответственных за хранение данных на стороне сервера (системой кэширования, базой данных, файловой системой). В частности надо помнить, что:
- данные в кэше могут быть устаревшими и утратившими целостность;
- при сложной работе с базой данных полезно пользоваться транзакциями и быть готовым к тому, что запрос может быть выполнен неудачно;
конфигурация серверов и разворачивание ПО
Большим преимуществом веб-приложений является возможность их обновления сразу у всех пользователей — для этого достаточно обновить сервер.
Но следует помнить, что это влечёт за собой также и возможность сломать ПО сразу у всех клиентов, скомпрометировать их личную информацию или просто уничтожить все их данные (что практически ведёт к потере бизнеса и это в лучшем случае).
Защититься от этих проблем помогут следующие практики:
- Делать резервные копии данных в места максимально удалённые от системы, для которой они делаются.
- Любую работу с серверами необходимо максимально автоматизировать, фиксируя все знания по конфигурированию и разворачиванию ПО в коде и, по возможности, в документации. Именно в таком порядке, потому что человеку свойственно забывать, а при каждом чихе лезть в документацию никто не будет.
- Проводить постоянный мониторинг состояния серверов и ПО запущенного на них (особенно следить за базовыми параметрами, вроде свободного места на диске, памяти и нагрузки на ЦПУ).
- Особо внимательно относиться к установке параметров ПО, влияющих на работу с данными (например, на кодировку базы данных или кэширование в веб-сервере).
борьба со скачками нагрузки
Ещё одной важной особенностью веб-приложений является скачкообразная нагрузка на сервера. Количество клиентов, одновременно использующих ваш сервер может зависеть от времени дня, поры года, фазы луны, праздников, различных непредвиденных событий, работы ваших пиарщиков и, конечно, DoS атак.
Поэтому ПО должно проектироваться не из расчёта на среднюю нагрузку, а с учётом возможных скачков этой нагрузки в несколько раз (а то и на несколько порядков). Помните, что если вам «повезёт», то Вы можете столкнуться со Слэшдот-эффектом (или «хабра-эффектом», что ближе к рунету).
Исходя из-этого соображения следует управлять и физическими ресурсами (мощностью серверов и прочим).
При этом не обязательно ставить целью полную работоспособность ПО на максимальной нагрузке, важно чтобы пользователи знали что оно работает и ничего «страшного» не происходит.
Обычные средства противостояния скачкам нагрузки включают:
- возможность быстрого масштабирования системы;
- отключение ненужных компонент системы (обычно самый простой и кардинальный способ — отключение возможности входа в систему, оставляя возможности, разрешённые только анонимным пользователям);
- использование CDN;
- блокировку запросов по определённому признаку (например, идущих с одного IP).
Обработка HTTP запроса
Как упоминалось ранее, весь процесс обработки типичного http запроса можно условно разделить на несколько этапов:
- диспетчеризация — поиск кода, который будет обрабатывать запрос;
- проверка прав доступа к функционалу и данным;
- сбор данных;
- обработка данных;
- формирование и отправка ответа.
Необходимо помнить, что это абстрактные этапы обработки абстрактного запроса. Часть из них может отсутствовать либо пересекаться (например проверка прав и сбор/обработка данных могут идти одновременно). Кроме того, на любом из этапов обработка запроса может завершиться ошибкой или возвращением закэшированного ответа.
диспетчеризация
Выполняется на основании всех данных запроса: пути, параметров запроса, его типа, заголовков.
Включает в себя три этапа:
- балансировка нагрузки — необходима в больших проектах, когда один физический сервер не справляется с потоком запросов от пользователей. Может производиться как на уровне специализированного железа, так и программным обеспечением и заключается, собственно, в равномерном распределении запросов по физическим серверам (возможно специализированным для конкретных задач).
- поиск кода, обрабатывающего запрос — выполняется программным сервером, который в итоге передаёт данные запроса непосредственно коду, создающему ответ или специализированному фреймворку.
- диспетчеризация внутри кода — фреймворк обычно производит дополнительную «более умную/сложную» обработку запроса, после чего на основании своих правил осуществляет поиск и вызов функции, обрабатывающей данный тип запроса.
На каждом следующем этапе возрастает сложность правил, по которым обрабатывается запрос. Балансировщик нагрузки распределяет запросы на основе их базовых свойств (или просто обеспечивает примерно равную нагрузку на каждый физический сервер), программные сервера определяют то, каким образом должен обрабатываться запрос (в основном выбор идёт между отдачей статического файла и вызовом специализированного кода), фреймворк обрабатывает запрос пользуясь непосредственно логикой определяемой предметной областью.
проверка прав
Прежде чем предпринимать какие-либо действия, необходимо убедиться, что субъект, запрашивающий их, обладает необходимыми правами доступа. Права пользователя могут распространяться как только на конкретный объект, так и на группу или тип объектов.
Один из возможных наборов прав:
- право на создание объекта (или группы/типа объектов);
- право на редактирование объекта (или группы/типа объектов);
- право на удаление объекта (или группы/типа объектов);
- право на просмотр объекта (или группы/типа объектов);
Часть прав обычно является следствием отношения владения между пользователем и объектом (например, автор статьи владеет ей и поэтому имеет права на редактирование и удаление) или административной должности пользователя (например, модератор форума может удалить даже чужую тему).
сбор данных
Обычно наиболее ресурсоёмкий этап, так как данные не располагаются прямо в коде, а хранятся в сторонних хранилищах (файловая система, база данных, кэш). Подключение к каждому из них и последующие запросы занимают существенное временя, так как хранилища подчиняются собственной логике и одновременно взаимодействуют с множеством других процессов. Следует учитывать следующие моменты:
- базы данных (в меньшей степени файловые системы) ориентированы на сохранение целостности данных, что отрицательно сказывается на скорости их ответа;
- данные могут иметь сложную структуру и/или большой объём, что замедляет их выборку;
- для ускорение сбора данных выгодно использовать системы кэширования, которые ориентированы на быстрое извлечение данных, но не гарантируют их целостность или сохранность;
- существенное время в получение данных занимает подключение к хранилищу (к файловой системе это относится в малой степени), поэтому сохранение подключения между обработкой разных пользовательских запросов может существенно ускорить работу системы, некоторые веб-фреймворки умеют делать это автоматически.
обработка данных
В большинстве случаев обработка данных не требуется (например, если просто надо отобразить страницу) или почти не требуется (обновить или создать запись в базе данных).
Но в некоторых случаях необходимо выполнить какой-либо сложный алгоритм. Например, создать картинку, или посчитать статистику. В этом случае необходимо всегда помнить о времени выполнения этого алгоритма. Если оно может быть велико, или требует большого количества ресурсов (по сравнению с другими запросами), то следует перенести его выполнение в фон (возможно даже на другую машину). Пользователю в этом случае можно сообщить о том, что задача начала выполняться, а получить её результат он может отдельным запросом. Конечно, это не обязательно доводить непосредственно до пользователя, достаточно реализовать нужное поведение на JavaScript.
Игнорирование запросов, отбирающих на себя большое количество ресурсов чревато существенными задержками в обработке всех остальных запросов. А при большом количестве пользователей возможна ситуация, когда несколько подобных задач будет вызвано одновременно (на самом деле такая ситуация гарантирована), что может полностью остановить работу сервера.
формирование и отправка ответа
Ответ (html-текст или данные в другом виде) можно подготовить к отправке несколькими способами:
- Некоторые данные (например, файл) никак подготавливать не надо.
- Построить структуру ответа непосредственно программными средствами, после чего конвертировать его в текст. Такой подход обычно применяется для машиночитаемых форматов данных (например, JSON, XML), т.к. для работы с ними обычно есть специализированные библиотеки.
- Воспользоваться одним из шаблонизаторов, позволяющих формировать тело ответа на основе шаблона, подставляя в него нужные данные. Обычно используется для формирование HTML, но может быть использован и для любого другого текстового представления.
В большинстве случаев в ответ на запрос по конкретному адресу достаточно отдавать данные в строго определённом формате (например, на запрос HTML-страницы возвращать только HTML). Но протокол HTTP позволяет клиенту указывать желаемый формат возвращаемых данных (с помощью заголовка Accept), опираясь на который сервер может выбирать между разными форматами.
При отправке ответа к нему также имеет смысла добавить несколько HTTP-заголовков, указывающих на формат и кодировку возвращаемых данных, особенности кэширования, и другие моменты. «Хорошие» фреймворки многие из заголовков устанавливают автоматически.
Базы данных
В общем случае база данных — это совокупность структурированных данных и связей между ними представленная в форме, удобной для обработки вычислительной техникой. Следует отличать понятие базы данных и системы управления базами данных: если 1-я — это набор данных, то 2-я — это программные средства, для работы с этими данными.
Существует большое количество разных типов баз данных, но в общем случае их можно разделить на два типа:
- реляционные БД — базы данных основанные на реляционной модели данных — наиболее математически строгой и проработанной модели. На текущий момент всё ещё являются наиболее распространённым типом БД.
- NoSQL БД — позиционируются как альтернатива реляционным БД («Not only SQL»; SQL — стандартный язык запросов в реляционных БД) — отличаются нереляционным представлением данных (т.е. могут использовать, в зависимости от конкретной СУБД, любое другое представление, кроме реляционного). Позволяют обходить некоторые проблемные места реляционных баз за счёт потери части их полезных свойств. Наиболее часто встречающиеся разновидности NoSQL БД:
Кроме того, в областях, связанных с искусственным интеллектом, любят говорить о базах знаний, но это скорее характеристика хранящихся в них данных или подхода к работе с ними, а не типа базы или её структуры.
Далее, если не будет указано явно, речь пойдёт о реляционных БД.
Схема БД — это описание содержания, структуры и ограничений базы данных.
Индекс — это объект СУБД, специальная структура данных, хранящая отношение <ключ, указатель на запись> и предназначенная для ускорения поиска и доступа по ключу. «Правильные» индексы позволяют значительно ускорить обработку запросов к СУБД.
ACID и транзакции
Транзакция — группа последовательных операций, представляющая собой логически целую единицу (иными словами, частичное выполнение такой последовательности операций не имеет смысла). Является одним из ключевых понятий при работе с базами данных.
В зависимости от СУБД требования к транзакциям могут варьироваться. Одним из наиболее распространённых наборов требований является ACID:
- Atomicity — атомарность — транзакция должна выполняться как единое целое или не выполняться вовсе.
- Consistency — согласованность — база должна находиться в согласованном состоянии до начала транзакции и после её завершения. В ходе совершения транзакции согласованность не требуется. Например, при переводе денег с одного банковского счёта на другой, итоговая сумма на двух счетах не должна измениться после транзакции, но во время транзакции может отличаться (сначала можно начислить деньги на один счёт, а только потом снять с другого).
- Isolation — изолированность — параллельные транзакции не должны оказывать влияние друг на друга. Это свойство перекликается в согласованностью — нарушение согласованности внутри одной транзакции не должно оказывать влияние на другую. Выделяется несколько уровней изоляции.
- Durability — надежность — в независимости от проблем на нижних уровнях системы (например, отключения питания), результаты успешно завершённой транзакции должны оставаться в силе.
Ещё одним требованием выступает целостность данных, которая по смыслу является более узким понятием, чем согласованность и не включает в себя бизнес-логику (см. пример с переводом денег в банке).
Нормализация
Нормальная форма — это свойство схемы данных в реляционных БД, характеризующее её с точки зрения избыточности (которая может приводить к логическим ошибкам при выборке или изменении данных). Всего выделяют 6 нормальных форм.
Нормализация — это процесс приведения схемы БД в нормальную форму. Её задача — уменьшить логическую избыточность (а значит и количество потенциальных ошибок). При этом влияние на производительность СУБД или объём занимаемых данных может быть любым. Чрезмерное увлечение нормализацией может отрицательно сказаться на производительности или сложности восприятия алгоритмов обработки данных. Поэтому в некоторых случаях нормализацию специально уменьшают.
Миграции
В процессе разработки могут изменяться как схема БД, так и её содержимое. Этими изменениями необходимо управлять, чтобы при обновлении проекта не произошло непредвиденных эффектов. Механизм, организации таких изменений называется миграциями.
Миграция — это программный код, который при своём выполнении производит необходимые изменения в схеме БД или в её данных. Для удобства обычно вводят понятие версий БД или версий таблиц БД, в этом случае миграция обеспечивает преобразование БД из версии N в версию N+1 (или наоборот).
Миграции делятся на:
- прямые — преобразование БД из версии N в версию N+1 — они реализуют обновление БД;
- обратные — преобразование БД из версии N в версию N-1 — они реализуют возможность отмены изменений;
Рекомендуется на каждое изменение делать оба типа миграций, так как никто не защищён от непредвиденных обстоятельств.
Также миграции делят на:
- миграции схемы БД, изменяющие структуру данных (например, добавление колонки в таблицу);
- миграции данных БД, изменяющие сами данные (например, изменение формата хранения данных).
Важно помнить, что код миграций нельзя привязывать к коду проекта (например, ссылаться на методы, объявленные в нём), т.к. код проекта изменяется, в то время как миграции должны оставаться неизменными. Если не следить за этим, то в определённый момент может измениться логика одной из функций (или функция просто будет удалена), используемых миграцией, и она станет нерабочей (и будет «ломать» БД при своём применении).
Типичные проблемы при работе с СУБД
- Различия в кодировках — при работе с СУБД обычно существует 3 логических сущности: клиентское приложение, СУБД и соединение между ними. Каждая из этих сущностей может оперировать своей кодировкой текстов, из-за чего возможны различные проблемы с хранением и извлечением данных. Необходимо следить за правильным преобразованием передаваемых данных, желательно использовать одну кодировку для каждой сущности.
- Временные зоны — по аналогии с различием кодировок, могут различаться и временные зоны (например, СУБД может оперировать временем в UTC, а клиент локальным). Как следствие, возможны изменения значений времени в записываемых и извлекаемых данных (записывается текущее время, а при извлечении записи из БД возвращается будущее или прошлое).
- Память — существует несколько «барьеров» использования памяти, существенно (на порядки) влияющих на скорость работы СУБД:
- вся база находится в оперативной памяти — СУБД работает быстро;
- вся база не помещается в оперативной памяти, но индексы всё ещё находятся в ней — СУБД работает медленно;
- даже индексы не помещаются в памяти (БД очень большая) — всё ужасно тормозит (скорее всего, если до этого дошло, то проект перестаёт нормально функционировать).
- Параллелизм — СУБД свойственны все проблемы параллелизма: взаимная блокировка, состояние гонки, проблема ABA. Обычно они связаны с неправильным использованием (или не использованием) транзакций.
Кэширование
Кэш — промежуточное хранилище с быстрым доступом, предназначенное для временного хранения информации, получение которой связано с существенно большей тратой ресурсов, чем чтение её из кэша. Позволяет существенно сократить использование вычислительных ресурсов.
Под получением информации может пониматься как непосредственно получение (например, чтение из реляционной БД), так и выполнение любого другого ресурсоёмкого алгоритма (например, получение миллионного простого числа).
Обычный алгоритм использования:
- пытаемся получить данные из кэша
- если получили, возвращаем данные
- если не получили, делаем сложные вычисления для их получения, сохраняем результат в кэше и возвращаем данные
Обычно данные помещаются в кэш на время, после чего удаляются из него, это позволяет поддерживать актуальность информации в кэше (т.к. в нём хранится только их копия) и гарантируется, что они устареют не более, чем на указанное время жизни. Чаще всего, данные помещаются в кэш по уникальному строковому ключу.
Применение
В вебе кэширование может применяться на всех этапах обработки запроса:
- Ответ сервера может быть закэширован одним из промежуточных узлов сети или непосредственно браузером, это позволяет в случае повторного запроса:
- сразу выдать пользователю готовый ответ, не повторяя запрос;
- выдать пользователю «временный ответ», а в фоне всё-таки повторить запрос. Обычно этот способ используется для статического контента: картинок, JavaScript скриптов и подобных сущностей. Управлять таким кэшированием можно с помощью HTTP заголовка «Cache-Control».
- Сервер может кэшировать на своей стороне как результаты сбора «сложных» данных (например, сложного запроса к БД), так и сформированный (или частично-сформированный) ответ. На стороне сервера для кэширования обычно используют специализированное ПО (например, memcached). Но в общем случае для этого можно использовать что-угодно (СУБД, что-то собственной реализации), если выполняется главное условие — быстрый доступ к информации.
Типичные проблемы и ошибки
- Информация в кэше устаревает, так как там хранится только копия реальных данных. Это, в свою очередь, может привести к различным коллизиям из-за использования неактуальной информации.
- Частный случай предыдущего пункта, возникает при обновлении сайтов, связанных с изменением статического контента (например, JavaScript скриптов) — браузеры пользователей начинают загружать новые страницы, но берут старые данные (скрипты, картинки) из кэша, из-за чего всё перестаёт работать. Для решения проблемы можно либо уменьшить время кэширования (от чего возрастёт нагрузка на сервера) либо в каждом запросе указывать версию запрашиваемого ресурса:
- http://example.com/static-files/123/script.js — версия может указываться для всех ресурсов
- http://example.com/static-files/script.js?version=123 — либо для каждого в отдельности
-
Когда данные пропадают из кэша (по истечении времени жизни или вытесненные более важными), следующая попытка получить эти данные приведёт к выполнению «тяжёлого» кода. Следствием этого может быть:
- длительная задержка ответа клиенту;
- резкое увеличение нагрузки на сервер (особенно в случае нескольких параллельных запросов);
- задержка (блокировка) обработки новых запросов (из-за того, что все обработчики будут заняты ожиданием данных);
Для сглаживания проблемы можно использовать несколько подходов:
- сторонний процесс, который следит за нахождением данных в кэше и периодически их актуализирует;
- вместе с данными хранить ожидаемое время их удаления. В случае запроса данных в момент близкий к нему, помещать в кэш старые данные с новым временем и параллельно запускать сбор необходимых новых данных.
- В случае «плохого» алгоритма формирования ключа, по которому хранятся данные, ключи могут пересечься и из кэша будут извлечены не те данные.
- Частой ошибкой является случайное помещение приватной информации в данные, кэшируемые как общие. Например, в случае кэширования полного кода html страницы, все пользователи, получающие её из кэша, могут вместо своей личной информации (например, имени в меню) увидеть информацию пользователя, страница которого кэшировалась.
- Частным случаем предыдущей проблемы являются особенности условий кэширования ответов серверов некоторыми браузерами и промежуточными узлами сети. Например, запрос может быть закэширован по адресу и параметрам, что не всегда достаточно для разделения запросов. Например, запрос http://www.example.com/my/info?action=get_money явно одинаков для всех пользователей, но должен возвращать им персонализированную информацию. А результат запроса http://www.example.com/get/actual/info?time=last_hour неявно зависит от времени выполнения. В решении этой проблемы может помочь использование HTTP заголовка «Vary» либо добавление ничего не значащего случайного параметра, например, времени.
Версионность
В некоторых случаях может понадобится очистить часть кэша (очистить весь просто), но перебирать все ключи крайне затратно.
Для этого можно в ключ, по которому сохраняются данные, добавить их версию. Например: some_data_1, other_data_1.
Когда нам надо «удалить» данные some_data и other_data, мы увеличиваем номер версии и по новым ключам (some_data_2, other_data_2) данных уже не будет. Старые данные удалятся, когда истечёт их время жизни.
Сессии и аутентификация пользователей
Сессия — это процесс обмена сообщениями (диалог) между устройствами или между пользователями и устройствами. Сессия имеет начало, конец и может включать обмен более чем одним сообщением в каждом из направлений. В контексте этой статьи мы будем говорить о сессии между пользователем (его браузером) и веб-сервером (сайтом).
Как указывалось ранее, протокол HTTP не предполагает сохранение состояния между запросами, из-за чего приходится либо передавать всю необходимую информацию вместе с каждым запросом либо организовывать сессии.
В этом случае сервер, при первом обращении нового пользователя, создаёт у себя хранилище данных, доступное по уникальному идентификатору, который и передаётся между запросами. Идентификатор обычно хранится в cookies. За счёт этого появляется возможность несколькими путями управлять длительностью сессии:
- сервер может установить максимальное время жизни cookie (как точное так и «до закрытия браузера»), после которого браузер её удалит (соответственно, пользователь потеряет сессию);
- сервер может самостоятельно следить за временем жизни хранилищ и удалять просроченные.
В сессии обычно хранятся результаты аутентификации (идентификатор пользователя, если тот «вошёл» на сайт), различная статистика и дополнительная информация, которую допустимо утратить в случае потери сессии. Важные данные хранить в сессионном хранилище нельзя:
- они будут утеряны при завершении сессии;
- они могут дублироваться т.к. у одного пользователя может быть несколько активных сессий (из разных браузеров, например: дома, на работе, на мобильном устройстве).
Наиболее удобным подходом к хранению сессионных данных, с точки зрения соотношения производительность/надёжность, является использование базы данных с дублированием информации в кэше. Так как изменение данных происходит достаточно редко, обращений к базе практически не происходит (что ускоряет обработку запросов), в то же время гарантируется сохранность данных.
Следует помнить, что злоумышленник может получить доступ к сессии пользователя, получив её идентификатор (например, перехватив один из запросов с ним). Поэтому, для проведения всех важных операций (изменение пароля/почты, оплаты, удаления аккаунта) необходимо требовать явного подтверждения от пользователя (например, ввода пароля).
Аутентификация пользователей
Следует различать несколько важных понятий:
Аутентификация — процедура проверки подлинности, например: проверка подлинности пользователя путём сравнения введённого им пароля с паролем в базе данных.
Авторизация — предоставление определённому лицу или группе лиц прав на выполнение определённых действий; а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Идентификация — процедура, в результате выполнения которой для субъекта идентификации выявляется его идентификатор, однозначно идентифицирующий этого субъекта в информационной системе.
Таким образом, при «входе» пользователя на сайт, происходят следующие операции:
- сервер проводит идентификацию пользователя (например, по логину);
- пользователь проходит процедуру аутентификации (проверку логина и пароля);
- при успешной аутентификации идентификатор пользователя сохраняется в сессии;
- далее, при каждой операции пользователя проверяется авторизован ли он проводить данное действие.
Распространённые способы получения доступа к ресурсу (сайту)
- Аутентификация с помощью логина и пароля (в разных вариантах). При этом может проходить с использованием защищённых соединений (например, по протоколу HTTPS) и с дополнительной защитой пароля.
- Многофакторная аутентификация (обычно двухфакторная) — характеризуется использованием нескольких факторов аутентификации различной природы:
- свойство, которым обладает субъект (например, биометрические данные);
- знание — информация, которую знает субъект (например, пин-код);
- владение — вещь, которой владеет субъект (например, специальная карта доступа);Наиболее распространённый в настоящее время подход — использование персональных устройств, позволяющих генерировать или хранить одноразовые пароли (в простейшем случае этим может заниматься мобильный телефон).
- OpenID — открытый стандарт децентрализованной системы аутентификации, предоставляющей пользователю возможность создать единую учётную запись для аутентификации на множестве не связанных друг с другом интернет-ресурсов, используя услуги третьих лиц.
- OAuth — открытый протокол авторизации, который позволяет предоставить третьей стороне ограниченный доступ к защищенным ресурсам пользователя без необходимости передавать ей (третьей стороне) логин и пароль.
Обратите внимание, что OpenID позволяет проводить аутентификацию пользователя, а OAuth — только авторизацию на произведение определённых действий.
Безопасность (и близкие к ней темы)
Внутренняя безопасность
На текущий момент существует большое число проверенных временем (и людьми) компонент, которые мы можем смело использовать в разработке. Поэтому всё чаще «узким местом» в безопасности становится непосредственно разрабатываемый сервис.
При разработке всегда следует помнить, что самый надёжный код — это код, который не написан, а самый надёжный способ хранить данные — это не хранить их.
Наиболее частые ошибки, приводящие к «дырам» в безопасности:
- Неверная конфигурация используемых компонент (веб-сервер отдаёт все файлы на диске, интерфейс базы данных «смотрит» во внешний мир).
- Ошибки в коде проверки прав и привилегий (неправильно написанное условие может дать пользователю доступ к функциям, которые должны быть ему недоступны).
- Отсутствие требования подтверждения важных операций: смены пароля, удаления аккаунта, оплаты (злоумышленник может перехватить сессию и получить полный доступ к управлению аккаунтом пользователя).
- Передача важных данных по незащищённым каналам (злоумышленник может перехватить приватную информацию). Для таких коммуникаций желательно использовать протокол HTTPS или аналогичные средства.
- Хранение приватных данных (паролей, ответов на секретные вопросы) в незащищённом виде (если злоумышленник получит доступ к вашим базам данных, то сразу получит доступ и ко всем данным пользователей). Желательно их вообще не хранить, либо хранить хеш-сумму с использованием соли.
Возможные атаки
Существует большое количество типов атак, вот наиболее распространённые:
- Подмена данных — любой запрос от клиента может быть подделан, поэтому все входящие данные необходимо проверять. В частности, нельзя проводить критические для сервиса расчёты на стороне клиента.
-
Внедрение кода — использование ошибки в обработке входящих данных, для внедрения вредоносного кода на ресурс.
- XSS — Сross Site Sсriрting — межсайтовый скриптинг — внедрение в выдаваемую пользователю страницу вредоносного кода. Классическим примером служит отсутствие удаления html-тегов в сообщениях на форумах, благодаря чему в сообщение можно вставить JavaScript код, который выполнится, когда пользователь откроет страницу с сообщением.
- SQL injection — внедрение в данные, передаваемые в базу данных, вредоносного кода. Код может содержаться в любых данных, которые так или иначе попадут в SQL запрос (например, в сообщении на форуме, поисковом запросе).
В обоих случаях, достаточно эффективной защитой является либо экранирование специальных символов, либо полное их удаление. 3. CSRF — Сross Site Request Forgery — подделка межсайтовых запросов — при посещении пользователем сайта злоумышленника, от имени пользователя автоматически шлётся запрос на атакуемый ресурс. Если пользователь авторизован на нём и запрос не требует подтверждения, то он будет выполнен без ведома пользователя. Для защиты от этой атаки можно: - требовать подтверждения всех важных операций; - проверять заголовок HTTP_REFERER, если он указан в запросе; - ассоциировать с сессией пользователя секретный ключ и требовать его явное указание в каждом запросе. Например, хранить его в cookies (которые шлются автоматически и не доступны злоумышленнику) и требовать его передачу в качестве параметра во всех запросах, тогда проверка происходит сравнением этих параметров. 4. Перехват данных — атака, при которой злоумышленник получает возможность просматривать все данные, передаваемые по открытым каналам. В частности, могут быть перехвачены логин/пароль, идентификатор сессии и прочая приватная информация. 5. Человек посередине — атака, при которой злоумышленник подключается к каналу между клиентом и сервером и тем самым получает возможность просматривать и редактировать сообщения между ними, оставаясь незамеченным. При этом клиент может считать злоумышленника сервером, а сервер — клиентом. 6. DoS-атака — Denial of Service — отказ в обслуживании — атака создающая условия, при которых пользователи системы не могут получить доступ предоставляемым ей услугам (обычно, вследствие большой нагрузки на сервера).
Многие современные фреймворки (и другие компоненты) уже имеют проверенные средства защиты от большинства видов атак, поэтому, по возможности, следует использовать их. Собственная реализация защиты потребует существенного времени и может оказаться нефункциональной из-за любой допущенной ошибки.
Следствием требований безопасности также являются ограничения, касающиеся различных аспектов веб-разработки. Например:
- Same Origin Policy — ограничения, налагаемые на код JavaScript, выполняющийся в браузере;
- Sender Policy Framework — расширение для протокола отправки электронной почты через SMTP, для проверки не подделан ли домен.
Защита от автоматизации операций
Довольно часто недобросовестные пользователи пытаются получить выгоду от автоматизации взаимодействий с вашим сервисом. Выражаться это может в написании ботов для игры, скриптов для рассылки спама, подборе паролей к аккаунтам пользователей и подобных вещах. Для защиты от таких действий существует несколько подходов:
- Анализ статистики — для каждой сессии собираются метрики, описывающие поведение пользователя. В случае, если они подпадают под шаблон, определённый разработчиками как «поведение, характерное для бота», работа пользователя с ресурсом блокируется. Простейшим примером подобной статистики может быть число запросов в единицу времени.
- Защита тратой ресурсов — для проведения важных операций от пользователя требуется затратить ограниченный ресурс: время, деньги. В этом случае многие действия становятся невыгодными для злоумышленника. Классическим примером является временный запрет входа на ресурс при нескольких неудачных попытках ввести правильный пароль.
- Обратный тест Тьюринга — реализация алгоритма, призванного отличить человека от машины, и закрытие этой проверкой всех важных операций. Наиболее распространённый пример — CAPTCHA.
Видимость в сети
Для того, чтобы разрабатываемый нами продукт приносил пользу, он должен быть доступен пользователям. А значит он, как минимум, должен:
- работать на вычислительных мощностях, которые могут выдержать прогнозируемую нагрузку;
- быть доступен по статичному адресу.
Хостинг
Хостинг — услуга по предоставлению вычислительных мощностей для размещения информации на сервере, постоянно находящемся в сети.
Условно, можно выделить несколько видов хостинга:
- Размещение кода и данных на платформе с предустановленным ПО (включая операционную систему, веб-сервер, почтовый сервер и другую инфраструктуру) — обычно используется для небольших проектов без нестандартных зависимостей.
- VPS/VDS — Virtual Private Server / Virtual Dedicated Server — предоставление виртуального выделенного сервера. Управление и конфигурация VPS осуществляется практически как на обычном физическом сервере (в частности, доступна настройка ОС, установка любого ПО), но сам VPS только эмулирует работу реального сервера и может ощущать влияние других VPS, находящихся на этом же физическом сервере (например, может начать «тормозить» в случае повышения нагрузки на соседей). Обычно используется средними проектами.
- Выделенный сервер — предоставление реального физического сервера с полным доступов к любым настройкам. Имеет смысл использовать для больших, нагруженных проектов.
Независимо от типа хостинга, каждый из них в той или иной степени может быть реализован «в облаке», что, в частности, даёт дополнительные возможности по масштабированию сервиса.
Сторона, предоставляющая услуги хостинга, обычно также обеспечивает бесперебойную работу инфраструктуры (например, подачу электричества), выдаёт статический IP адрес.
Отдельно стоит указать на важность использования CDN — Content Delivery Network — сетевой инфраструктуры для оптимизации доставки контента пользователям. Распространение контента с помощью CDN позволяет как ускорить доставку данных пользователям, так и существенно сократить непрофильную нагрузку на сервера.
IP-адрес & DNS
IP-адрес — уникальный сетевой адрес узла в компьютерной сети, построенной по протоколу IP (по этому протоколу работает большинство сетей, в том числе и интернет). IP-адрес имеет каждое устройство, подключённое к интернету.
В большинстве случаев предоставляется вместе с хостингом (с возможностью докупать дополнительные адреса). На текущий момент идёт переход с формата адресов IPv4 на IPv6.
DNS — компьютерная распределённая система для получения информации о доменах. В нашем случае она интересна в первую очередь из-за возможности автоматического получения IP-адреса по читаемому имени. Именно эта система обеспечивает нахождение веб-ресурса по имени вроде «wikipedia.org».
Приобрести доменное имя можно в одной из множества компаний, занимающихся их регистрацией. После приобретения Вы должны получить доступ к редактированию файла dns зоны, в котором можно указывать соотношения доменных имён и IP-адресов, а также некоторые другие параметры.
Прописав в настройках зоны IP-адрес нашего сервиса, мы сделаем его доступным по соответствующему доменному имени.
Следует помнить, что DNS — иерархическая структура, узлы которой обновляют информацию с определённой периодичностью, поэтому информация о соотношении доменного имени и IP-адреса не обновляется мгновенно (и может задерживаться на несколько часов).
мониторинг
Мониторинг — процесс непрерывного наблюдения и регистрации состояния объекта. В нашем случае — веб-проекта.
Следить необходимо за всеми хоть сколь-нибудь важными параметрами (конечно, по возможности) и выявлять аномалии в их поведении. В конечном счёте, качество работы проекта хорошо характеризуют два параметра:
- доступность — процент времени за год в которое система была доступна для пользователей. Высокие уровни доступности обычно описываются числами вроде 99.99% и называются, соответственно, по числу девяток: «3 девятки», «4 девятки» и так далее.
- время отклика — время, требующееся системе на то, чтобы отреагировать на ввод пользователя.
Любые технические проблемы в Вашем проекте так или иначе скажутся на одном из этих параметров.
развертывание ПО
Развертывание ПО — все действия, связанные с подготовкой к использованию ПО. Включая, но не ограничиваясь: установку (как целевого ПО так и сопутствующего), обновление, конфигурацию.
Процесс развёртывания не менее важен, чем сама разработка, так как при неверном проведении может полностью перечеркнуть все труды разработчиков (например, уничтожив данные в БД). Это операция периодическая (необходимо делать при каждом обновлении) и достаточно однообразная, поэтому особенно подвержена ошибкам из-за человеческого фактора. Как следствие, её необходимо максимально автоматизировать и документировать. На текущий момент для этого есть достаточно средств. В идеале, обновление или установка ПО должны запускаться одной простой командой (скриптом), не требующей ввода дополнительных данных.
Кроме того, необходимо убедиться, что специалист, ответственный за эту операцию, в курсе всех необходимых вопросов как со стороны разработки так и со стороны администрирования.
При использовании кэширования, при обновлении проекта следует учитывать следующие нюансы:
- В новой версии ПО может измениться формат данных, хранящихся в кэше, из-за чего возникнут ошибки, если его не очистить (или не обеспечить конвертацию данных).
- В случае очистки кэша (которая обычно происходит при обновлении), первые запросы к проекту вызовут увеличенную нагрузку (из-за того, что будет выполняться много «тяжёлых» операций). В таких случаях следует вручную (или скриптом) пробежать по таким операциям до открытия доступа пользователям, чтобы «разогреть» проект.
Front-end
Front-end — часть проекта (и сфера ответственности), связанная с его клиентской составляющей. Это непосредственно веб-страницы, отображение информации пользователю и получение команд от него.
На каждой веб-странице можно выделить статическую и динамическую составляющие.
Статическая составляющая
Статическая составляющая страницы, обычно состоит из:
- описания её структуры (DOM)на HTML (сейчас повсеместно используется HTML5);
- описания стилей, применяемых к этой структуре с помощью CSS;
- прочего статического содержимого: изображений, видео, музыки.
Часто этого достаточно для того, чтобы получить полезный информационный ресурс, например личный блог. Тем более, сейчас существует большое количество сторонних сервисов, берущих часть функционала на себя, например, организацию комментариев.
Для удобства работы с CSS было разработано несколько мета-языков, список которых можно найти среди ссылок в конце текста.
Динамическая составляющая
Если от ресурса (веб-страницы) требуется организовать сложное поведение, то его описывают на JavaScript (в подавляющем большинстве случаев). Для этих скриптов браузер предоставляет окружение и API для манипулирования содержим страницы (атрибутами узлов DOM, стилями). Разработка на JavaScript в основном событийно-ориентированная, существует возможность «вешать» обработчики как на действия пользователей (например, клик мышью по ссылке), так и на независимые от него события (например, окончание загрузки страницы).
Скрипты могут быть как прямо встроенными в страницы, так и загружаться отдельно.
В контексте управления веб-страницей JavaScript можно назвать достаточно низкоуровневым ЯП. Поэтому разработано большое число вспомогательных библиотек, упрощающих рутинные операции.
Из-за множества нюансов, связанных с безопасностью, при выполнении кода скриптов браузеры вводят ограничения на некоторые типы действий (Same Origin Policy), часто довольно неприятные, но необходимые.
AJAX
AJAX (Asynchronous JavaScript and XML) — подход к построению интерактивных веб-страниц, заключающийся в фоновом обмена данными с сервером (т.е. без перезагрузки страницы).
При правильном использовании позволяет улучшить реакцию пользовательского интерфейса (сгладив задержки вызванные загрузкой большого объёма данных, например, можно по клику на название книги загружать её обложку, не загружая сразу все обложки) и просто сделать его удобнее, реализовав дополнительную реакцию на действия пользователя (например, подгружать подсказки при вводе пользователем поискового запроса).
Существует несколько подходов к реализации взаимодействия с сервером из JavaScript:
- XMLHttpRequest — стандартное API, доступное во всех браузерах. Просто отправляет запрос на сервер и возвращает ответ. Обычно, пользуются различного рода обёртками над этим методом, реализованными в сторонних библиотеках. Подпадает под ограничения Same Origin Policy.
- Comet — набор способов, позволяющих серверу отправлять браузеру данные без явного запроса от него. Используются, когда стандартный подход «запрос-ответ» работает слишком медленно и/или создаёт большую нагрузку. Все варианты реализации такого взаимодействия опираются на нестандартное использование стандартного API, и, как следствие, страдают всеми проблемами, свойственными такому подходу.
- Веб-сокеты — протокол двухсторонней связи поверх TCP, предназначенной для обмена сообщениями между браузером и сервером. Новое «правильное» решение для задач, ранее решаемых Comet-ом.
Поисковая оптимизация
Когда проект запущен, необходимо сделать так, чтобы потенциальные пользователи его могли найти. Не касаясь прямой рекламы, рассмотрим базовые механизмы работы поисковых сервисов.
Каждая поисковая система постоянно с помощью «пауков» (поисковых роботов) пробегает по всем доступным ей веб-страницам, анализируя информацию, расположенную на них. Задача разработчиков сделать всю необходимую информацию доступной для пауков, по возможности, в удобном для них виде и так, чтобы по определёнными поисковым запросам сайт находился в выдаче на максимально высокой позиции.
SEO (Search Engine Optimization) — комплекс мер для поднятия позиций сайта в результатах выдачи поисковых систем по необходимым запросам пользователей.
Для достижения этой цели можно проводить следующие мероприятия:
- делать информацию, размещённую на странице, удобной и полезной для пользователей — это общая и самая главная рекомендация всех современных поисковых систем;
- описывать структуру сайта в robots.txt и картах сайта;
- указывать в разметке дополнительную семантическую информацию с помощью одного из микроформатов. Сейчас рекомендуется использовать подход, описанный на Schema.org.
Кроме того, следует помнить, что поисковые системы значительно лучше воспринимают статические сайты, чем динамические.
Дополнительные ссылки
наиболее популярные языки программирования в веб-разработке (субъективно)
Сравнение популярных фреймворков
наиболее популярные СУБД (субъективно)
наиболее популярные веб-сервера (субъективно)
наиболее популярные JavaScript библиотеки (субъективно)
наиболее популярные мета-языки над CSS (субъективно)
Список заготовленных наборов стилей для быстрого внедрения стандартного и целостного дизайна на сайт.
Нераскрытые темы
- тестирование;
- варианты взаимодействия веб-серверов;
- варианты использования СУБД;
- нагрузка: частые узкие места и борьба с ними;
- юзабилити;
- REST;
- «X» As A Service;
- CMS.
Будущее MMORPG
Недавно в одной из дискуссий на gamedev.ru удалось удачно сформулировать своё видение текущего состояния и тенденций рынка MMORPG в области игровых механик. Поскольку давно хотел написать про это дело, то не премину развить мысль.
Разговор пойдёт про «классические» MMORPG: WoW, SWTOR, Rift — все, которые претендуют на массовость, имеют общий игровой мир и признаки ролевой игры.
Главный посыл следующий: жанр в упадке. Не с финансовой точки зрения, конечно. И не с точки зрения «успешности». Деньги обсуждать не будем, только механики.
Этот текст развивает идеи предыдущего моего поста «MMOG в которую я хотел бы играть»
Верификация через дублирование логики
Привет.
В посте Тесты, которые тестируют тесты я описал свой взгляд на верификацию программ через дублирование их логики в виде отдельной модели и последующее сравнение с ней. В качестве частного случая выступили юнит-тесты.
В этот раз, опираясь на изложенные идеи, я попробую сформулировать общий подход к оценке уровня верифицированности ПО.
Зачем нужен план
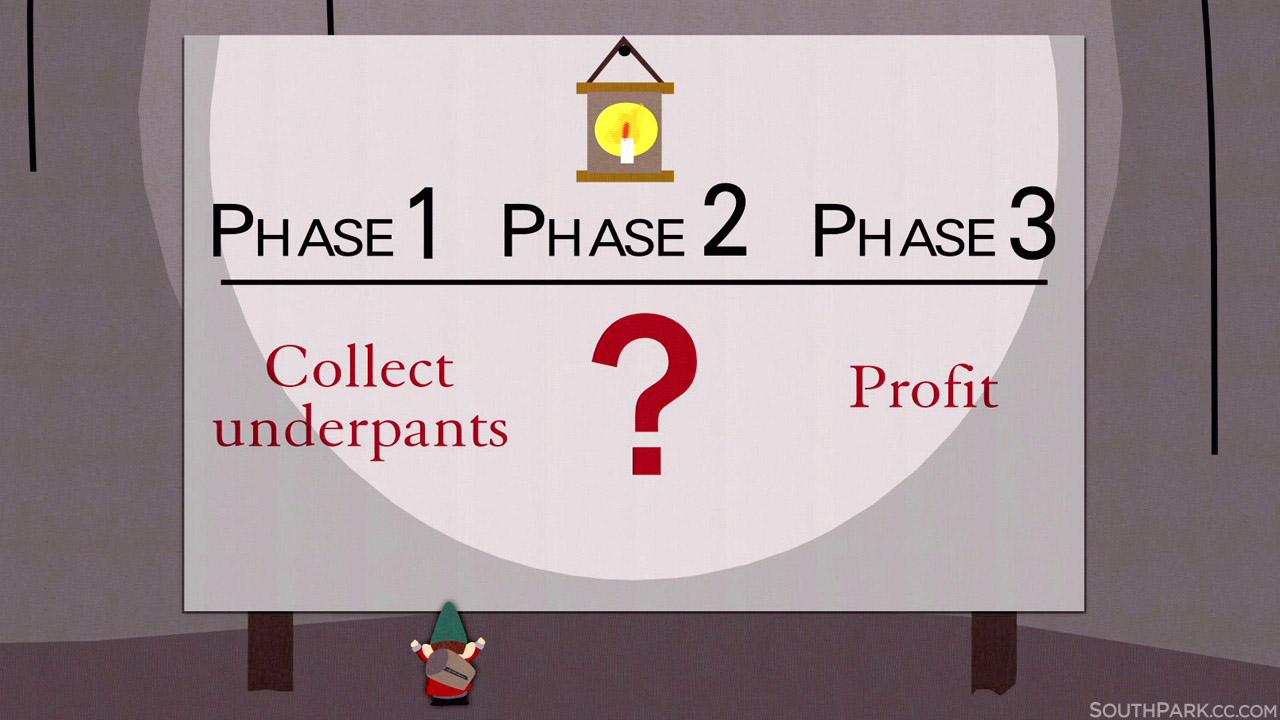
Самый известный план на планете
Сначала я хотел назвать этот текст «Зачем нужен бизнес-план», но к чему себя ограничивать? План — он и в Африке план, не важно для чего. Тот, что для бизнеса, называется бизнес-планом. Тот, что для эвакуации, называется, как ни странно, планом эвакуации. И так далее.
Но идея текста таки пришла из области, где актуальны бизнес-планы. Часто стал встречаться с высказываниями о том, что «бизнес-план, конечно, нужен, но вот конкретно в нашем случае он пользу не принесёт потому, что»:
- у нас слишком большая неопределённость, будет гадание на кофейной гуще;
- и так всё предельно ясно, план — лишняя трата сил.
Сам я тоже страдал этими тараканами, но так получилось, что периодически разного рода планы составлять всё-таки приходилось. И хочу вам сказать — планы делать полезно и нужно.
Но сначала…
Почему разработчики не сделают эту простую штуку?
Животрепещущий вопрос, не правда ли?
Меня уже 3 года как им пытают персонально, поэтому я решил попытаться рассказать всё-таки почему. Рассказывать, конечно, буду со стороны разработчика-одиночки. В командах побольше есть некоторые нюансы, но суть та же.
Для затравки приведу небольшую иллюстрацию, смысл её, думаю, понятен.
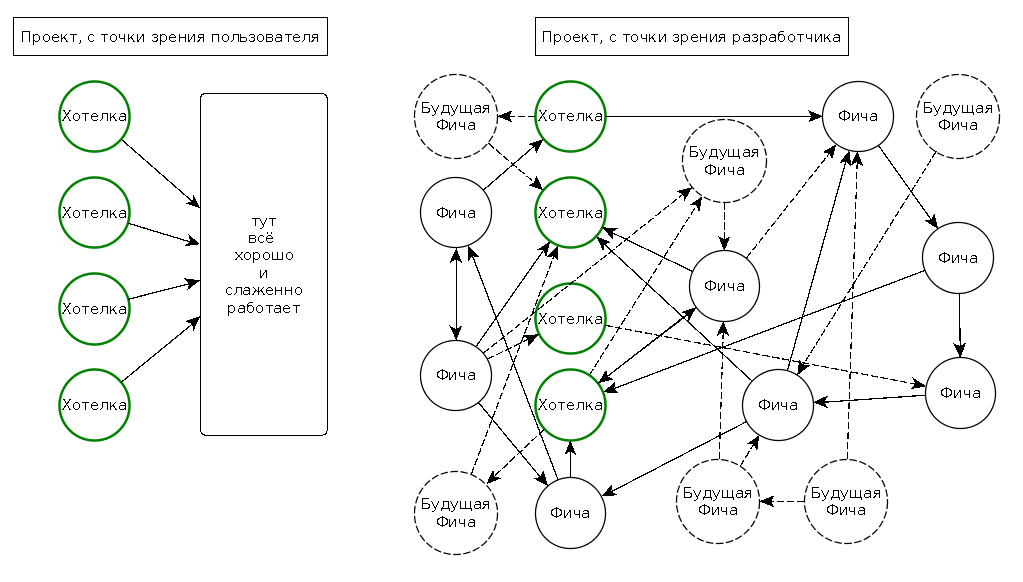
Взгляд на проект со стороны пользователя и разработчика.