Тесты, которые тестируют тесты
Или почему в них нет необходимости.
Часто, когда рассказываешь новичкам про автоматическое тестирование, всплывает один и тот же вопрос: «А кто будет проверять сами тесты? Придётся писать тесты для тестов, потом тесты для тестов для тестов…» Все любят рекурсию и ещё больше любят уесть ей собеседника.
Странно, ни разу не попадался вопрос: «Кто тестирует тестировщиков?» — по сути, та же проблема вид сбоку.
Но действительно, почему нет необходимости тестировать тесты? (и тестировщиков)
Тесты — это хороший пример дублирования, метода повышения надёжности за счёт реализации нескольких копий критической части системы. Нюанс заключается в том, что в нашем случае через дублирование контролируется не работа результирующей системы, а точность её формальной модели.
Следующая схема должна пояснить мысль.
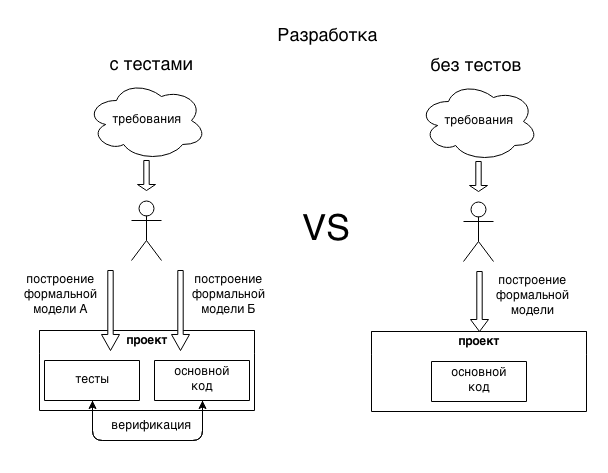
Поток разработки с тестами и без тестов.
Когда мы пишем код (не важно, тесты или функциональность), мы строим формальную модель кусочка реального мира. Эта модель, естественно, отличается как от реального положения вещей во вселенной (в следствие упрощения) так и от идеального результата, который мы хотим получить (в следствие ошибок и не понимая конечной цели).
При этом, при написании тестов и функциональности мы смотрим на предметную область под разными углами, что приводит к появлению двух отличающихся моделей одной предметной области, утрируя:
- В коде функциональности описывается модель устройства, с точки зрения его внутренних механизмов.
- В коде тестов описывается модель устройства, с точки зрения внешнего наблюдателя.
Таким образом, в проекте появляется две модели решаемой задачи, созданные по разным принципам. Сравнивая их поведение (через запуск тестов) мы можем выявить несовпадения в моделях и устранить их.
Соответственно, тесты проверяют код, код проверяет тесты. Вместе получается более надёжная модель решаемой задачи.
Камень в огород TDD
Пользуясь случаем хочу бросить камень в огород классического TDD, адепты которого проповедуют быстрые циклы переключения между моделями: написал тест, написал функциональность, повторил.
Из-за частой смены контекста сложно удержать в голове целостную структуру каждой модели (тем более, хорошо её продумать).
Поэтому я предпочитаю разработку длинными заходами:
- проектирование части одной модели (любой);
- реализация спроектированного;
- проектирование аналогичной части второй модели;
- реализация спроектированного;
Порядок (что писать первым: тесты или функциональность) не важен — главное, чтобы в итоге было реализовано две модели. Я обычно начинаю с более простой.
Больше моделей
На самом деле можно выделить не две, а три модели предметной области:
- модель в коде функциональности;
- модель в коде тестов;
- модель в голове разработчика.
Все три модели строятся на разных принципах, а значит этим можно пользоваться для определения принадлежности ошибки конкретной модели: если две модели говорят А, а третья Б, то логично предположить, что третья не права и именно она содержит ошибку.
Во время работы над статьёй ни один тест не пострадал. Спасибо за внимание.
Читать далее
- Жизнь и работа с ошибками
- Верификация через дублирование логики
- Верификация частными случаями
- Жизнь и работа с моделями
- Два года пишем RFC — статистика
- Почему разработчики не сделают эту простую штуку?
- Гены, мемы и мемплексы
- Композиция vs классификация
- Следующий фронтир геймдизайна
- Как завалить собес у меня