Топовые LLM фреймворки могут быть не так надёжны, как вы думаете
Месяц назад решил добавить поддержку Gemini в Feeds Fun и под это дело изучал топовые LLM фреймворки — писать свой велосипед не хотелось.
В итоге нашёл стыдный баг в интеграции с Gemini в LLamaIndex. Судя по коду, он есть и в Haystack и в плагине для LangChain. А корень проблемы вообще в SDK Google для Python.
При инициализации нового клиента для Gemini код фреймворка перетирает/подменяет API ключи во всех клиентах, созданных до этого. Потому что API ключ, по-умолчанию, хранится в синглетоне.
Смерти подобно, если у вас multi-tenant приложение, и незаметно во всех остальных случаях. Multi-tenant — это когда ваше приложение работает с несколькими пользователями.
Например, в моём случае, в Feeds Fun пользователь может ввести свой API ключ, чтобы улучшить качество сервиса. Представьте какой забавный казус мог бы случиться: пользователь ввёл API ключ для обработки своих рассылок, а потратил токенов (заплатил) за всех пользователей сервиса.
Репортил только в LLamaIndex как security issue и уже 3 недели ноль реакции, для Haystack и LangChain лень воспроизводить. Так что это ваш шанс зарепортить багу в топовый репозиторий. Под катом будет вся инфа, воспроизвести не сложно.
Ошибка примечательна многим:
- Оценка критичности ошибки очень зависит от вкусовщины, опыта и контекста. Для меня, в проектах в которых я работал, — это критическая ошибка безопасности. Но, похоже, для большинства актуальных проектов, которые используют LLM, это вообще не принципиально. Что навевает некоторые мысли о мейнстрим около-LLM разработках.
- Это хороший индикатор низкого уровня контроля качества кода: код ревью, тестов — всех процессов. Всё-таки это интеграция с одним из топовых провайдеров API, найти проблему можно было кучей разных способов, но ни один не сработал.
- Это хорошая иллюстрация порочного подхода к разработке: «копипастим из туториала и льём на прод». Чтобы допустить эту ошибку нужно было проигнорить одновременно и базовую архитектуру твоего проекта и логику вызова кода, который ты копипастишь.
В итоге я забил на эти фреймворки и впилил свой костыль, благо HTTP API для Gemini есть.
Мой вывод из этого безобразия такой: доверять коду, который под капотом у современных LLM фреймворков нельзя. Надо перепроверять, вычитывать. То, что у них написано «production ready», не значит, что они действительно production ready.
Далее расскажу подробнее про сам баг.
Мои GPT-шки и prompt engineering

Понечки занимаются prompt engineering (c) DALL-E
Я пользуюсь ChatGPT практически с момента выхода её четвёртой версии (то есть уже больше года). За это время хорошо набил руку в написании запросов к этой штуке.
В какой-то момент, OpenAI разрешили настраивать свой чат с помощью собственных текстовых инструкций (ищите Customize ChatGPT в меню). Я постепенно дописывал туда команды и вот на днях размер инструкций превысил разрешённый максимум :-)
Плюс, оказалось, что универсальный набор инструкций не получается — под каждую задачу их нужно подстраивать, иначе они не будут так полезны как могли бы быть.
Поэтому покумекав, я решил вместо кастомизации своего чата, вынести инструкции в GPT ботов. OpenAI называют их GPTs, по-русски буду называть их GPT-шками. По-сути, это такие же чаты, в которых больше лимит на кастомизированные инструкции и в них можно залить дополнительные тексты как базу знаниий.
Когда-нибудь, я сделаю GPT-шку для этого блога, а пока расскажу про двух рабочих лошадок, которыми пользуюсь каждый день.
- Expert — ответы на вопросы.
- Abstractor — краткое изложение текста.
Для каждой будет описание базового промпта с моими комментариями.
OpenAI недавно открыла магазин GPT-шек, буду благодарен если пролайкаете мои. Конечно, только если они вам полезны.
Симуляция общественного мнения в игре
Демонстрация технического прототипа манипуляции общественным мнением и рассказ как он работает.
Продолжаю участвовать в школе World Builders. За последний месяц набросал технический прототип механик манипуляции общественным мнением.
Вы играете за главного редактора новостного агентства, который отправляет журналистов на задания, а по результатам расследований публикует статьи с фокусом на нужные (игроку) темы.
Всё интересное можно найти в заглавном видео, ниже текстом пройдусь по основным моментам.
Процедурные заголовки для новостей без сложной генерации текста
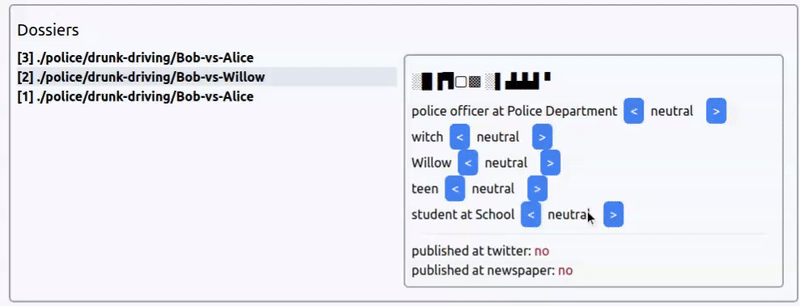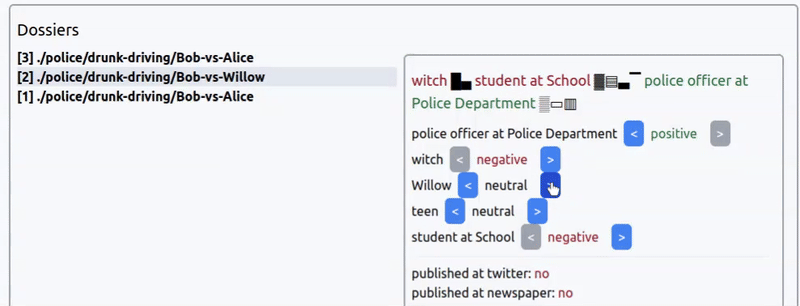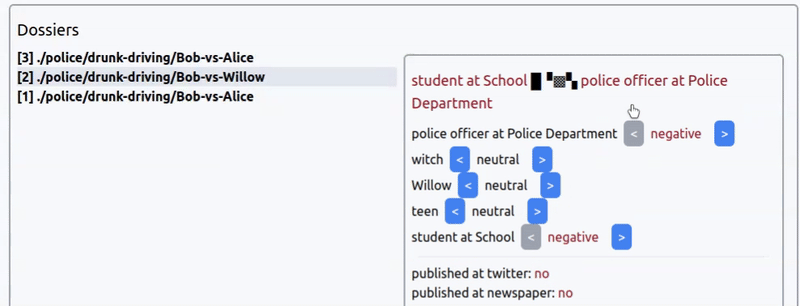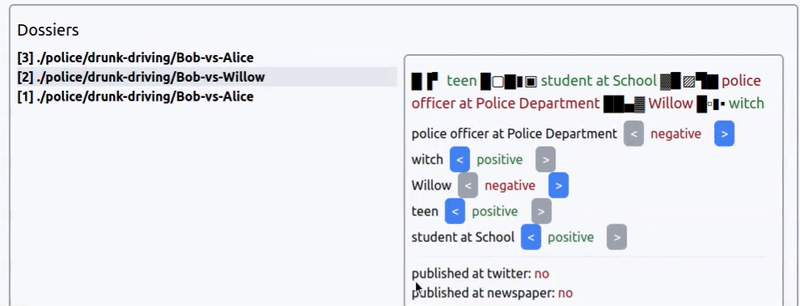
Интерфейс выбора коннотации новости из прототипа игры про агентство новостей. Новость: арест ведьмочки-подростка за пьяное вождение.
От опросов про предпочтения игроков потихоньку перешёл к работе над прототипом игры.
Игра будет про новостное агентсво, где вы — главный редаткор, а ваша задача — манипулировать общественным мнением, расследуя события и выбирая коннотацию новостей: на что обратить внимение публики, что скрыть, в каком тоне преподнести темы, etc.
Поэтому всё действие будет происходить вокруг текста новостей.
Сходу можно сказать, что создавать большие простыни текста для каждой новости нет смысла — игра не про чтение новостей, а про управление ими. Поэтому разумно взаимодействие строить только на заголовках.
Но как сделать отображение новостей одновременно интересным и простым?
Предпочтения игроков в стратегии

Смотрим на данные опроса и пытаемся найти что-нибудь полезное.
Недавно я делал опрос о предпочтениях игроков в стратегии.
В предыдущем посте мы очищали данные, в этом попробуем чего-нибудь в них найти.
В посте вы найдёте «интерактивный исследовательский стенд» с кучей графиков, на которых можно смотреть разницу между двух выборок на ваш выбор. Выборок много — на любой вкус и цвет, поэтому щелкать можно долго — делитесь в Telegram и Discord найденными закономерностями.
Но будьте аккуратны с выводами. Данных мало, а в некоторых случаях совсем мало. Например, разница между размерами выборок мужчин и женщин примерно десятикратная => интерпретировать отличия между ними следует очень осторожно.
В целом, не воспринимайте этот пост как полноценное исследование. Уверен, многие аналитики мне бы руки за такое оторвали. Пришили и снова оторвали. Пользуйтесь постом как интерфейсом к данным, а выводы делайте свои.