Top LLM frameworks may not be as reliable as you think
Nearly a month ago, I decided to add Gemini support to Feeds Fun and did some research on top LLM frameworks — I didn't want to write my own bicycle.
As a result, I found an embarrassing bug (in my opinion, of course) in the integration with Gemini in LLamaIndex. Judging by the code, it is also present in Haystack and in the plugin for LangChain. And the root of the problem is in the Google SDK for Python.
When initializing a new client for Gemini, the framework code overwrites/replaces API keys in all clients created before. Because the API key, by default, is stored in a singleton.
It is death-like, if you have a multi-tenant application, and unnoticeable in all other cases. Multi-tenant means that your application works with multiple users.
For example, in my case, in Feeds Fun, a user can enter their API key to improve the quality of the service. Imagine what a funny situation could happen: a user entered an API key to process their news but spent tokens (paid for) for all service users.
I reported this bug only in LLamaIndex as a security issue, and there has been no reaction for 3 weeks. I'm too lazy to reproduce and report for Haystack and LangChain. So this is your chance to report a bug to a top repository. All the info will be below, reproducing is not difficult.
This error is notable for many reasons:
- The assessment of the criticality of the error depends a lot on taste, experience, and context. For me, in the projects I worked on, this is a critical security issue. However, it seems that this is not critical at all for most current projects that use LLMs. Which leads to some thoughts about mainstream near-LLM development.
- This is a good indicator of a low level of code quality control: code reviews, tests, all processes. After all, this is an integration with one of the major API providers. The problem could have been found in many different ways, but none worked.
- This is a good illustration of the vicious approach to development: "copy-paste from a tutorial and push to prod". To make such a mistake, you had to ignore both the basic architecture of your project and the logic of calling the code you are copying.
Ultimately, I gave up on these frameworks and implemented my own client over HTTP API.
My conclusion from this mess is: you can't trust the code under the hood of modern LLM frameworks. You need to double-check and proofread it. Just because they state that they are "production-ready" doesn't mean they are really production-ready.
Let me tell you more about the bug.
Unexpectedly participated in a class action lawsuit in the USA
Recently, I unexpectedly encountered a justice system in the USA.
- In 2017-2018, when there was a crypto boom, I invested a little in a mining startup: I purchased their tokens and one hardware unit.
- The startup went up and began to build a mega farm, but it didn't work out — the fall of Bitcoin coincided with their spending peak, the money ran out, and the company went bankrupt. It's funny that a month or two after filing for bankruptcy, bitcoin played back everything. Sometimes you're just unlucky :-)
- I had already written off the lost money, of course. I acted on the rule "invest only 10% of the income you don't mind losing."
- Since everything legally happened in the USA, people gathered there and filed a class action lawsuit.
- I received a letter stating that I would be automatically among the plaintiffs if I did not refuse. I did not refuse; when else would I get an opportunity to participate in a class action?
- Everything calmed down until 2024.
- In the spring, another letter came: "Confirm the ownership of the tokens and indicate their quantity. We won and will share the remaining among all token holders proportionally, minus a healthy commission to the lawyers."
- But how do I confirm? More than five years have passed. The Belarusian bank account is closed, the company's admin panel is unavailable, and there was no direct transaction in the blockchain—I paid in Bitcoin directly from some exchange (although it is not recommended to do so).
- I found an email from the company confirming I bought tokens (without the amount) and printed it as a PDF. I attached it to the application with screenshots of the transactions from the exchange for the related period. I gave the address of my current wallet, where these tokens lie dead weight. I sent everything.
- Today, I received $700 in my bank account. Of course, this is not all the lost money, nearly 25%, maybe slightly more.
What conclusions can be drawn from this:
- Sometimes, you just don't get lucky in your business.
- Keep all emails. You never know what and when will come in handy.
- Class action lawsuits work and do it in an interesting way.
- Justice in the USA works slowly but, apparently, inevitably and unexpectedly (for me) loyally to minor participants in the conflict. At least sometimes.
Places to discuss Feeds Fun
I continue developing my news reader: feeds.fun. To gather information and people together, I created several resources where you can discuss the project and find useful information:
- Blog blog.feeds.fun
- Discord server
- Reddit r/feedsfun
So far, there is no one and nothing there, but over time, there will definitely be news and people.
If you are interested in this project, join! I'll be glad to see you and will try to respond quickly to all questions.
Migrating from GPT-3.5-turbo to GPT-4o-mini
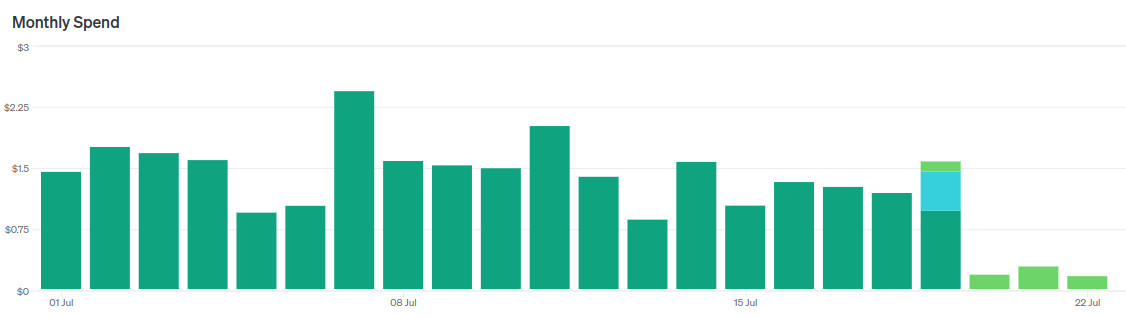
Guess when I switched models.
Recently OpenAI released GPT-4o-mini — a new flagship model for the cheap segment, as it were.
- They say it works "almost like" GPT-4o, sometimes even better than GPT-4.
- It is almost three times cheaper than GPT-3.5-turbo.
- Context size 128k tokens, against 16k for GPT-3.5-turbo.
Of course, I immediately started migrating my news reader to this model.
In short, it's a cool replacement for GPT-3.5-turbo. I immediately replaced two LLM agents with one without changing prompts, reducing costs by a factor of 5 without losing quality.
However, then I started tuning the prompt to make it even cooler and began to encounter nuances. Let me tell you about them.
«Slay The Princess» — combinatorial narrative

My favorite version of the Princess.
It's hard to impress me as a player and even harder as a game developer. The last time it happened with Owlcat Games in Pathfinder: Kingmaker, when they added a timer to the game's plot.
But Black Tabby Games managed to do it. And they did it not with some technological complexity but with a visual novel on a standard engine (RenPy), which is cool in itself.
I'll share a couple of thoughts about the game and its narrative structure, while I'm still under the impression. I need to think about how to adapt this approach to my projects.
ATTENTION: SPOILERS!
If you haven't played Slay The Princess yet, I strongly recommend you to catch up — the game takes 3-4 hours. You'll not regret it.