Top LLM frameworks may not be as reliable as you think
Nearly a month ago, I decided to add Gemini support to Feeds Fun and did some research on top LLM frameworks — I didn't want to write my own bicycle.
As a result, I found an embarrassing bug (in my opinion, of course) in the integration with Gemini in LLamaIndex. Judging by the code, it is also present in Haystack and in the plugin for LangChain. And the root of the problem is in the Google SDK for Python.
When initializing a new client for Gemini, the framework code overwrites/replaces API keys in all clients created before. Because the API key, by default, is stored in a singleton.
It is death-like, if you have a multi-tenant application, and unnoticeable in all other cases. Multi-tenant means that your application works with multiple users.
For example, in my case, in Feeds Fun, a user can enter their API key to improve the quality of the service. Imagine what a funny situation could happen: a user entered an API key to process their news but spent tokens (paid for) for all service users.
I reported this bug only in LLamaIndex as a security issue, and there has been no reaction for 3 weeks. I'm too lazy to reproduce and report for Haystack and LangChain. So this is your chance to report a bug to a top repository. All the info will be below, reproducing is not difficult.
This error is notable for many reasons:
- The assessment of the criticality of the error depends a lot on taste, experience, and context. For me, in the projects I worked on, this is a critical security issue. However, it seems that this is not critical at all for most current projects that use LLMs. Which leads to some thoughts about mainstream near-LLM development.
- This is a good indicator of a low level of code quality control: code reviews, tests, all processes. After all, this is an integration with one of the major API providers. The problem could have been found in many different ways, but none worked.
- This is a good illustration of the vicious approach to development: "copy-paste from a tutorial and push to prod". To make such a mistake, you had to ignore both the basic architecture of your project and the logic of calling the code you are copying.
Ultimately, I gave up on these frameworks and implemented my own client over HTTP API.
My conclusion from this mess is: you can't trust the code under the hood of modern LLM frameworks. You need to double-check and proofread it. Just because they state that they are "production-ready" doesn't mean they are really production-ready.
Let me tell you more about the bug.
Migrating from GPT-3.5-turbo to GPT-4o-mini
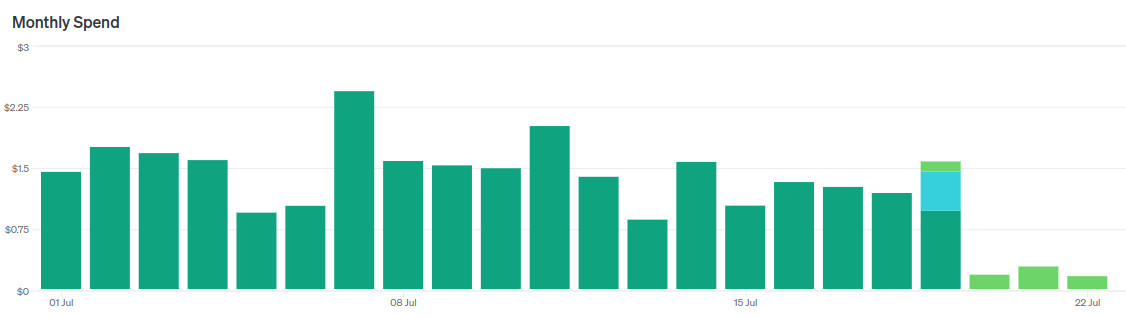
Guess when I switched models.
Recently OpenAI released GPT-4o-mini — a new flagship model for the cheap segment, as it were.
- They say it works "almost like" GPT-4o, sometimes even better than GPT-4.
- It is almost three times cheaper than GPT-3.5-turbo.
- Context size 128k tokens, against 16k for GPT-3.5-turbo.
Of course, I immediately started migrating my news reader to this model.
In short, it's a cool replacement for GPT-3.5-turbo. I immediately replaced two LLM agents with one without changing prompts, reducing costs by a factor of 5 without losing quality.
However, then I started tuning the prompt to make it even cooler and began to encounter nuances. Let me tell you about them.
Computational mechanics & ε- (epsilon) machines
I found a few new concepts for tracking.
Computational mechanics
There is computational mechanics, which deals with numerical modeling of mechanical processes and there is an article about it on the wiki. This post is not about it.
This post is about computational mechanics, which studies abstractions of complex processes: how emergent behavior arises from the sum of the behavior / statistics of low-level processes. For example, why the Big Red Spot on Jupiter is stable, or why the result of a processor calculations does not depend on the properties of each electron in it.
ε- (epsilon) machine
The concept of a device that can exist in a finite set of states and can predict its future state (or state distribution?) based on the current one.
Computational mechanics allows (or should allow) to represent complex systems as a hierarchy of ε-machines. This creates a formal language for describing complex systems and emergent behavior.
For example, our brain can be represented as an ε-machine. Formally, the state of the brain never repeats (voltages on neurons, positions of neurotransmitter molecules, etc), but there are a huge number of situations when we do the same thing in the same conditions.
Here is a popular science explanation: https://www.quantamagazine.org/the-new-math-of-how-large-scale-order-emerges-20240610/
P.S. I will try to dig into scientific articles. I will tell you if I find something interesting and practical. P.P.S. I have long been thinking in the direction of a similar thing. Unfortunately, the twists of life do not allow me to seriously dig into science and mathematics. I am always happy when I encounter the results of other people's digging.
My GPTs and prompt engineering

Ponies are doing prompt engineering (c) DALL-E
I've been using ChatGPT almost since the release of the fourth version (so for over a year now). Over this time, I've gotten pretty good at writing queries to this thing.
At some point, OpenAI allowed customizing chats with your text instructions (look for Customize ChatGPT in the menu). With time, I added more and more commands there, and recently, the size of the instructions exceeded the allowed maximum :-)
Also, it turned out that a universal instruction set is not such a good idea — you need to adjust instructions for different kinds of tasks, otherwise, they won't be as useful as they could be.
Therefore, I moved the instructions to GPT bots instead of customizing my chat. OpenAI calls them GPTs. They are the same chats but with a higher limit on the size of the customized instructions and the ability to upload additional texts as a knowledge base.
Someday, I'll make a GPT for this blog, but for now, I'll tell you about two GPTs I use daily:
- Expert — answers to questions.
- Abstractor — makes abstracts of texts.
For each, I'll provide the basic prompt with my comments.
By the way, OpenAI recently opened a GPT store, I'd be grateful if you liked mine GPTs. Of course, only if they are useful to you.
Dungeon generation — from simple to complex
What we should get.
This is a translation of a post from 2020
This is a step-by-step guide to generating dungeons in Python. If you are not a programmer, you may be interested in reading how to design a dungeon [ru].
I spent a few evenings testing the idea of generating space bases.. The space base didn't work out, but the result looks like a good dungeon. Since I went from simple to complex and didn't use rocket science, I converted the code into a tutorial on generating dungeons in Python.
By the end of this tutorial, we will have a dungeon generator with the following features:
- The rooms will be connected by corridors.
- The dungeon will have the shape of a tree. Adding cycles will be elementary, but I'll leave it as homework.
- The number of rooms, their size, and the "branching level" will be configurable.
- The dungeon will be placed on a grid and consist of square cells.
The entire code can be found on github.
There won't be any code in the post — all the approaches used can be easily described in words. At least, I think so.
Each development stage has a corresponding tag in the repository, containing the code at the end of the stage.
The aim of this tutorial is not only to teach how to generate dungeons but to demonstrate that seemingly complex tasks can be simple when properly broken down into subtasks.