Тарантога: второй блин
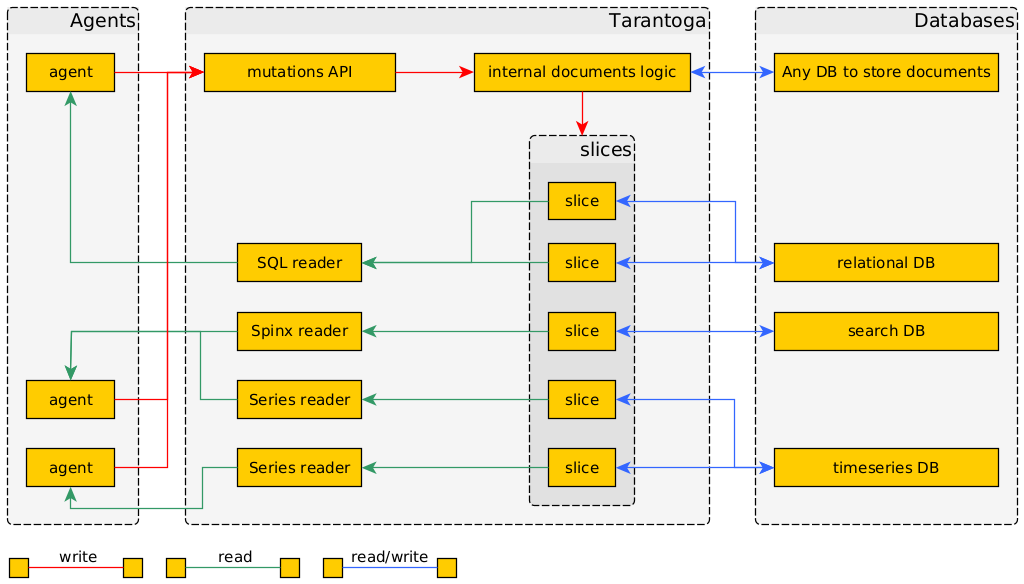
Потоки данных во второй версии прототипа Тарантоги.
Продолжаю эксперименты. Как видно из заголовка, вторая попытка тоже не удалась, хотя выглядит симпатичнее.
Реализация ушла довольно далеко от описанного в посте о первом блине. В частности, GraphQL не подошёл.
Как всегда, работа породила сторонние результаты. Я подумал об уменьшении сложности работы с данными, вынес в отдельную библиотеку логику работы с предикатами.
Вторую версию концепции я считаю жизнеспособной, но сильно затратной для развития в одного разработчика. Вот если бы меня было несколько, или проект уже существовал в рабочем виде, и надо было только дописывать новых агентов.
Но мы имеем, что имеем, поэтому буду думать дальше. Скорее всего попробую сделать в лоб: минималистично, стандартными подходами без интеллектуальных извращений. Всё-таки представление об инструменте уже несколько раз в голове перекрутил и оно значительно упростилось.
А пока расскажу что получилось на этот раз.
Тарантога: первый блин
Продолжаю прототипировать свои идеи. Ожидаемо, первый блин вышел комом: и по срокам и по качеству. Однако получилось опробовать описанные ранее концепции, посмотреть что работает, а что нет.
Фактически, реализована база знаний для хранения метаинформации, GUI для её просмотра, пара агентов. И много нареканий к выбранному пути :-)
Поэтому попробую переосмыслить архитектуру Тарантоги.
Yet another Тарантога
Не только я пытаюсь собрать всю свою информацию в одном месте.
Вот описание созданной за год инфраструктуры от другого энтузиаста.
Знакомство с блогом karlicoss и подтолкнуло меня делать собственный велосипед. Всегда приятно узнать, что ты не один такой упоротый :-) Там же я позаимствовал пару базовых концепций.
В отличии от меня, karlicoss избрал более прагматичный подход:
- Поставил во главу угла data liberation — освобождение данных — получение копий всех сущенственных данных, которыми пытаются владеть облака и прочие сервисы. Возможно, логика в том, что владение данными первично, а как их обработать всегда можно придумать.
- Не пытается (пока) изобретать универсальные форматы или универсальный софт. Просто делает инфраструктуру экспорта, хранения и обработки информации, которая работает. То есть у него получается сеть из источников, экспортёров, обработчиков и дашбордов.
Какой из подходов лучше, не знаю. Я отказался от такого варианта потому, что не вижу как разумными силами в долгосрочной перспективе гарантировать устойчивость настолько гетерогенной сети к регрессиям. В случае с централизованной базой знаний я это хотябы в теории представлю.
Но из того, что чего-то не вижу, не следует, что этого нет.
Тарантога: модель данных
Постепенно пилю Тарантогу. Дело идёт не быстро: отвлекаюсь то на праздники, то на сторонние эксперименты, то на разбирательства с современными пайплайнами. Но постепенно что-то вырисовывается. Довольно странное :-)
Кстати, я завёл отдельный тег для постов про него.
Так вот, о странном и расскажу — о модели данных. Но без обоснования решений, какие обоснования в прототипе.
Тарантога: мемплексы
Про метаинформацию поговорили, теперь можно поговорить и про тексты. Затронем в том числе и поднятый в предыдущем эссе вопрос: является ли текст отдельной сущностью или утверждением метаинформации.
По названию поста уже можно сделать вывод, что говорить мы будем не совсем про тексты, но давайте не забегать вперёд.
Сначала определимся с тем что такое текст.
Я немного схитрил в предыдущих постах, когда говорил, что экзокортекс управляет текстами. Важны не только тексты, но и картинки, видеоролики, звукозаписи, чертежи и так далее.
Поэтому под текстами я имел в виду не «последовательность символов», а скорее «текстовый документ», который может содержать разнородную информацию, включающую и сам текст и какие-то медиа-объекты.
Далее под текстом я буду понимать именно «текстовый документ», если явно не будет указано обратное.