Разработка Тарантоги: Первый блин
Заметки о разработке Тарантоги — экзокортекса для управления информацией:
Продолжаю прототипировать свои идеи. Ожидаемо, первый блин вышел комом: и по срокам и по качеству. Однако получилось опробовать описанные ранее концепции, посмотреть что работает, а что нет.
Фактически, реализована база знаний для хранения метаинформации, GUI для её просмотра, пара агентов. И много нареканий к выбранному пути :-)
Поэтому попробую переосмыслить архитектуру Тарантоги.
Проблемы
Общая база данных неудобна
Много времени было потрачено на разработку специфической базы и продумывание механизмов взаимодействия агентов с ней. Удовольствие я получил, но результат в основном «отрицательный» — понял как делать не надо.
Я недооценил сложность синхронизации схемы описания сущностей и решил поддерживать общую базу для всех агентов — этакую blackboard. В результате появились жёсткие требования к схеме описания сущностей, которой должны соответствовать все агенты.
При работе над агентом стало необходимо учитывать как с ним будут взаимодействовать все прочие. Это неудобное свойство, особенно когда неизвестны ни перечень агентов ни типы сущностей, с которыми они будут работать.
Разные агенты требуют разную детализацию описания сущностей. Для одного агента url — это свойство сущности, а для другого — отдельная сущность с названием и расписанием обновления информации. То, что можно описать просто для одного агента, должно быть описано сложно для другого. Из-за общей базы и общей схемы данных получается, что все агенты работают с переусложнённым описанием сущностей.
В такой системе, добавление или изменение агента может привести к необходимости по-цепочке зависимостей менять всю систему. Это неприемлемо.
Поиск в базе утверждений неудобен
Представление информации как последовательности утверждений о сущностях всё ещё выглядит интересно. Существенных проблем у агентов с такой формой инициирования изменений я не заметил.
Однако извлечение информации из базы утверждений показало себя плохо. На практике всё равно необходимо делать агрегацию утверждений вокруг сущностей. Например, агент, который загружает данные по url, кроме url должен получить доступ и к имени сущности (для лога), к расписанию обновления url (чтобы не перетягивать каждый раз все url), у уже загруженным данным (чтобы проверить дату загрузки).
Поэтому база знаний, работающая только с утверждениями, не подходит.
«Универсальные» правила приоритезации неудобны
Применение изменений от агентов согласно приоритету и статусу истинности теперь выглядит частным случаем общей практики приоритезации изменений. Реализация частных случаев как универсальных создаёт проблемы при работе со сложной информацией и / или сложными цепочками изменений.
Например:
- Пусть есть агенты А и Б, которые создают утверждения одного рода.
- Пусть есть агент В, который распространяет (копирует) эти изменения на другие сущности.
- Какой приоритет должен быть у утверждений, созданных агентом В из утверждений агентов А и Б?
В общем случае на этот вопрос нет ответа. В каждой конкретной ситуации надо решать исходя из контекста.
Позитивное
Представление информации как лога изменений — хороший шаг. Лог можно просматривать, анализировать. Можно откатывать изменения как целиком, так и выборочно.
Концепция представления базы в виде сети множеств, между которыми перетекает информация, всё ещё выглядит перспективной. Но следует отойти от атомарных утверждений в сторону описания сущностей и уменьшить зависимость между множествами.
GUI в виде консоли базы данных с вьюшками выглядит вполне удобным.
Агенты с атомарной областью ответственности выглядят перспективно. Например, изначальный агент для загрузки RSS я разделил на двух:
- агент, который загружает данные по любым url.
- агент, который извлекает данные из любого текста в формате rss/atom, не трогая другие типы контента.
В итоге:
- Загрузчик url инкапсулирует в себе логику, которую не потребуется реализовывать во всех прочих агентах. Это упростит код и позволит оптимизировать нагрузку на сеть.
- RSS агент (как и многие другие) не будет задумываться откуда к нему приходит информация.
Даже на примере этих двух агентов уже вырисовывается сложное взаимодействие:
- загрузчик url грузит rss ленту по url;
- rss парсер разбирает её на сущности;
- загрузчик url грузит контент каждой сущности (если тот ещё не загружен).
Новая архитектура
Исходя из выявленных нюансов, я решил пересмотреть архитектуру Тарантоги.
- От общей базы отказываюсь, но оставляю общий лог изменений.
- Вместо утверждений о сущностях, агент будет писать в лог команды на изменение их описания в своём личном хранилище.
- Агент не будет иметь непосредственный доступ на чтение ни к одному хранилищу, даже своему.
- Агент будет иметь доступ к API, которое реализует доступ на чтение данных в формате, который удобен агенту.
- API для каждого агента будет своё и фактически станет аналогом view в базах данных.
- API будет конфигурироваться пользователем на основе информации о том, какие агенты взаимодействуют с Тарантогой.
- Перед взаимодействием с Тарантогой агент сможет проверить схему предоставляемого ему API на соответствие своим требованиям.
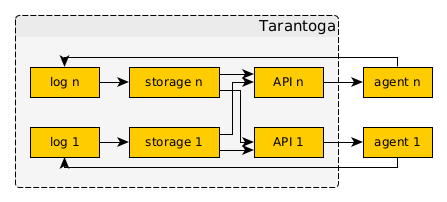
Предполагаемые потоки данных между компонентами Тарантоги.
Скорее всего, API будет реализовано с помощью GraphQL, а пользователь базы при подключении нового агента будет дописывать / конфигурировать необходимое API, пользуясь внутренними интерфейсами хранилищ Тарантоги.
Предполагаю, что в прототипе хранилища будут in memory и работать с ними можно будет обычным кодом на Python. Потом их можно будет вынести в SQL / NoSQL базу.
Изменения позволят:
- Уменьшить связанность агентов, что упростит их разработку и интеграцию.
- Явно передать пользователю управление семантикой базы, поскольку только он может определить с какими данными что должно работать.
- Уменьшить количество велосипедов. Вместо собственного API — GraphQL, вместо собственной базы — что-нибудь стандартное.
Этот пост является частью серии
- Следующий пост: Второй блин
- Предыдущий пост: Модель данных
- Первый пост: Экзокортекс 3.5
Читать далее
- Мышление письмом
- Модная типизация в Python
- Генерация подземелий — от простого к сложному
- Два года пишем RFC — статистика
- О проектировании миров
- Автоматический генератор нелинейных квестов
- World Builders 2023: Считаем бизнес-план для игры в Steam
- Feeds Fun — читалка новостей с тегами и ChatGPT
- Мои GPT-шки и prompt engineering
- Заметки про coding agents