Разработка Тарантоги: Второй блин
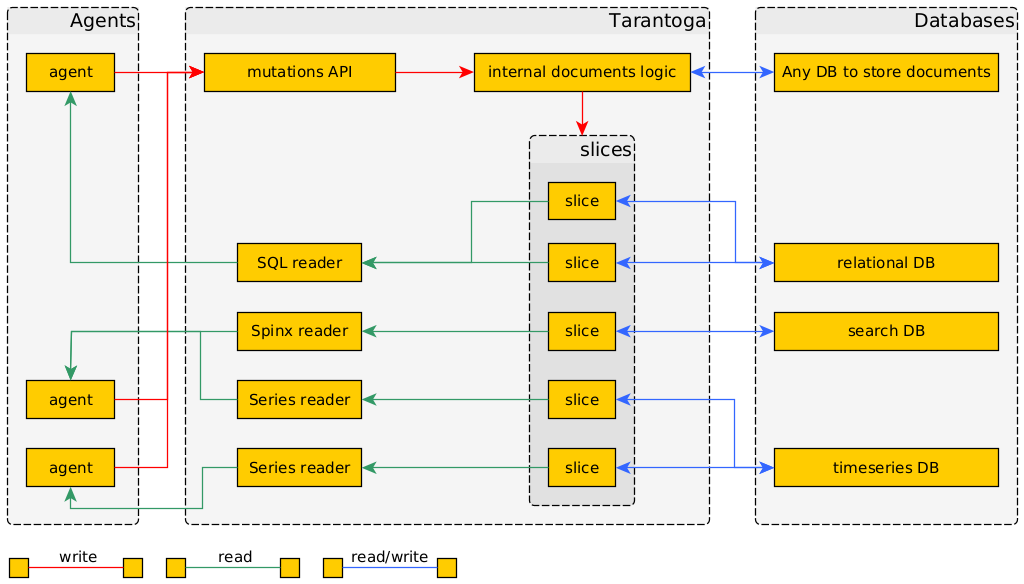
Потоки данных во второй версии прототипа Тарантоги.
Заметки о разработке Тарантоги — экзокортекса для управления информацией:
Продолжаю эксперименты. Как видно из заголовка, вторая попытка тоже не удалась, хотя выглядит симпатичнее.
Реализация ушла довольно далеко от описанного в посте о первом блине. В частности, GraphQL не подошёл.
Как всегда, работа породила сторонние результаты. Я подумал об уменьшении сложности работы с данными, вынес в отдельную библиотеку логику работы с предикатами.
Вторую версию концепции я считаю жизнеспособной, но сильно затратной для развития в одного разработчика. Вот если бы меня было несколько, или проект уже существовал в рабочем виде, и надо было только дописывать новых агентов.
Но мы имеем, что имеем, поэтому буду думать дальше. Скорее всего попробую сделать в лоб: минималистично, стандартными подходами без интеллектуальных извращений. Всё-таки представление об инструменте уже несколько раз в голове перекрутил и оно значительно упростилось.
А пока расскажу что получилось на этот раз.
Tarantoga pancake 0.2
Работа над второй версией шла под флагом борьбы со сложностью. Разница с первой версией составила ~2800 добавленных строк и ~5800 удалённых.
В работе над второй версией меня вдохновляла CouchDB. В частности, мне понравилась идея design documents. Если вы не знакомы с этой базой данных, рекомендую почитать — документации не много, подход интересный. И, в отличии от Тарантоги, она работает :-)
Поскольку в первой реализации у меня возникли большие вопросы к удобству работы с логическими утверждениями и хранению их в общей базе, вторая версия Тарантоги превратилась в документо-ориентированное хранилище — обёртку над специализированными базами данных.
Документ имеет формат JSON с некоторыми предопределёнными полями.
JSON выбран из-за распространённости и простоты: не нужно писать конвертеры в/из внутренних типов Тарантоги — в первой версии это значительно мешало.
Тарантога как обёртка над базами
Чтобы уменьшить сложность, я решил устранить лишние преобразования схем данных и прокидывать запросы на чтение от агента сразу в нужную базу.
Главными задачами Тарантоги стали:
- контроль изменений документов;
- управление срезами данных, необходимых агентам;
- контроль доступа к срезам.
Поскольку:
- большая часть нагрузки предполагается на чтение;
- предполагается использование разных баз данных, как минимум: реляционных и поисковых движков;
- нет критических требований к скорости обновления информации для агентов;
я решил, что хорошим вариантом будет создать абстракцию, позволяющую агентам управлять доступными им срезами данных. Работает она следующим образом:
- Агент описывает правила формирования среза данных в виде отдельного документа. В прототипе логика захардкожена.
- При изменении документа, Тарантога пропускает его старую и новую версии через описанную агентом логику формирования среза (для каждого среза в отдельности).
- На основе изменений, логика меняет соответствующий срез данных. Например, изменяет таблицу в реляционной базе данных.
То есть агенты описывают правила формирования срезов данных, с которыми они работают в удобном им контексте. Если нужен полнотекстовый поиск, они описывают правила обновления информации в Sphinx или ElasticSearch. Если нужен хитрый поиск по полям, то формируют таблицу с индексом в реляционной базе.
Примеры срезов:
- таблица документов, отмеченных тегами;
- таблица веб-адресов для закачки;
- таблица сообщений об ошибках;
- индекс для полнотекстового поиска.
Взаимодействие агентов с Тарантогой
Агенты могут изменять документы с помощью общего API мутаций, предоставляющих расширяемый набор операций:
- создать документ;
- заменить документ;
- удалить документ;
- применить JSON Patch к документу.
При этом делать выборки документов агенты могут через индивидуально настроенные интерфейсы. Каждый интерфейс предоставляет доступ к специфическому набору срезов. Один интерфейс принимает запросы в формате SQL для срезов в реляционных базах данных, другой — в формате запросов Sphinx для полнотекстового поиска, и так далее.
Этот пост является частью серии
- Следующий пост: Эксперименты закончены
- Предыдущий пост: Первый блин
- Первый пост: Экзокортекс 3.5
Читать далее
- Мышление письмом
- Модная типизация в Python
- Генерация подземелий — от простого к сложному
- Два года пишем RFC — статистика
- О проектировании миров
- Автоматический генератор нелинейных квестов
- World Builders 2023: Считаем бизнес-план для игры в Steam
- Feeds Fun — читалка новостей с тегами и ChatGPT
- Мои GPT-шки и prompt engineering
- Бесконечность схем данных