Что почитать, чтобы лучше кодить?
Экспресс пост в ответ на вопрос.
Кратко: чтобы лучше кодить, надо больше кодить :-) и вдумчиво читать код.
Если чуть подробнее, то вопрос сложный и что-то посоветовать из чтения мне сложно:
- Я уже давно не читал книг для начинающих. Те, что вспомню, могут быть устаревшими лет как 10.
- У меня другой бэкграунд, о котором сейчас расскажу.
Я больше писал, чем читал :-D В итоге, когда я начал читать шаблоны проектирования, я подумал: «и что тут такого, я уже с этим сталкивался», когда листал совершенный код, я подумал аналогично. То есть моя практика обгоняла теорию.
Из книг я читал то, что советовали преподаватели в универе, благо было кому советовать, и то, что считал интересным. Страуструпа, например, 2 раза прочитал.
Тарантога: второй блин
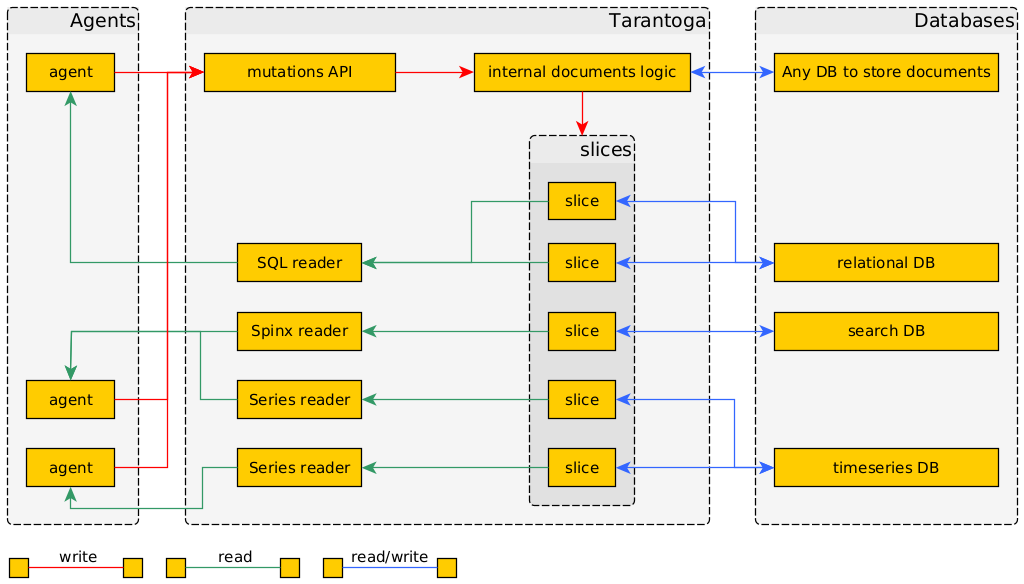
Потоки данных во второй версии прототипа Тарантоги.
Продолжаю эксперименты. Как видно из заголовка, вторая попытка тоже не удалась, хотя выглядит симпатичнее.
Реализация ушла довольно далеко от описанного в посте о первом блине. В частности, GraphQL не подошёл.
Как всегда, работа породила сторонние результаты. Я подумал об уменьшении сложности работы с данными, вынес в отдельную библиотеку логику работы с предикатами.
Вторую версию концепции я считаю жизнеспособной, но сильно затратной для развития в одного разработчика. Вот если бы меня было несколько, или проект уже существовал в рабочем виде, и надо было только дописывать новых агентов.
Но мы имеем, что имеем, поэтому буду думать дальше. Скорее всего попробую сделать в лоб: минималистично, стандартными подходами без интеллектуальных извращений. Всё-таки представление об инструменте уже несколько раз в голове перекрутил и оно значительно упростилось.
А пока расскажу что получилось на этот раз.
Тарантога: первый блин
Продолжаю прототипировать свои идеи. Ожидаемо, первый блин вышел комом: и по срокам и по качеству. Однако получилось опробовать описанные ранее концепции, посмотреть что работает, а что нет.
Фактически, реализована база знаний для хранения метаинформации, GUI для её просмотра, пара агентов. И много нареканий к выбранному пути :-)
Поэтому попробую переосмыслить архитектуру Тарантоги.
Yet another Тарантога
Не только я пытаюсь собрать всю свою информацию в одном месте.
Вот описание созданной за год инфраструктуры от другого энтузиаста.
Знакомство с блогом karlicoss и подтолкнуло меня делать собственный велосипед. Всегда приятно узнать, что ты не один такой упоротый :-) Там же я позаимствовал пару базовых концепций.
В отличии от меня, karlicoss избрал более прагматичный подход:
- Поставил во главу угла data liberation — освобождение данных — получение копий всех сущенственных данных, которыми пытаются владеть облака и прочие сервисы. Возможно, логика в том, что владение данными первично, а как их обработать всегда можно придумать.
- Не пытается (пока) изобретать универсальные форматы или универсальный софт. Просто делает инфраструктуру экспорта, хранения и обработки информации, которая работает. То есть у него получается сеть из источников, экспортёров, обработчиков и дашбордов.
Какой из подходов лучше, не знаю. Я отказался от такого варианта потому, что не вижу как разумными силами в долгосрочной перспективе гарантировать устойчивость настолько гетерогенной сети к регрессиям. В случае с централизованной базой знаний я это хотябы в теории представлю.
Но из того, что чего-то не вижу, не следует, что этого нет.
Я и «умный» GUI в IDE
](https://tiendil.org/static/posts/me-and-the-smart-gui-in-ide/images/me-and-the-smart-gui-in-ide-cover.jpg)
Updated: Этот пост написан до появления Copilot. Моё мнение о Copilot в отдельном посте.
В комментарии к модной типизации в Python мне обоснованно указали, что я не рассмотрел использование типов для помощи IDE. В частности, для автодополнения и подсказок.
Это действительно хороший повод для использования типов. Но в моей картине мира и в моём окружении разработчика подобные «умные» штуки находятся где-то на периферии полезности. Поэтому я о них периодически не помню.
Собственно году в 2010 я отказался от «умных» версий того же автодополнения и не жалею. В то же время, мои периодические порывы сменить Emacs на крутую современную IDE во многом вызваны как раз желанием проверить, не сделали ли наконец нормальный программистский CAD с действительно крутыми помощниками. Пока не сделали, так что сижу на Emacs :-)
Я ни разу не хейтер IDE. Просто не использую те фичи, для которых IDE ставят — не вижу от них существенного профита для себя на текущем уровне развития софта.
На сколько я знаю, моя позиция не распространена, поэтому расскажу про её логику подробнее.