Пара слов о GitHub Сopilot

DALL-E: "Vrubel style painting of pair programming Robot + Human. An robot is writing code, a human is reviewing code".
Последние несколько недель использовал GitHub Сopilot, благо для Emacs есть плагин. Поделюсь впечатлениями.
Для справки, я уже лет 15 осознанно не использовал умное автодополнение. Всё моё автодополнение — это DynamicAbbreviations, по сути — дополнение написанного слова на основе словаря из открытых исходников.
Причина отказа такая: используя «умное» автодополнение (например, подсказку аттрибутов/методов объекта) перестаёшь понимать проект. Начинаешь на автомате брать предлагаемые варианты методов/переменных, не разбираясь что они конкретно делают и есть ли альтернатинвые варианты.
В краткосрочной перспективе отказ от автодополнения повышает нагрузку на человека (особенно на память) и замедляет работу, но в доглосрочной даёт глубокое понимание проекта, возможнсоть крутить его в голове как угодно, что с лихвой окупает потери на скорости в моменте. А поскольку я работаю только над долгими проектами, долгосрочная выгода важнее.
С Copilot я, похоже, вернуcь к умному автодополнению, в его более правильном варианте.
Итак, давайте посмотрим чего умеет и не умеет Copilot.
Мышление письмом
](https://tiendil.org/static/posts/thinking-through-writing/images/thinking-through-writing-cover.jpg)
Из манги Bakuman
Мышление письмом — это практика перевода своих мыслей в письменную форму.
То, чем я преимущественно занимаюсь в этом блоге, и, по мере сил, на работе.
Наконец нашёл время рассказать про эту штуку подробнее.
Тарантога: второй блин
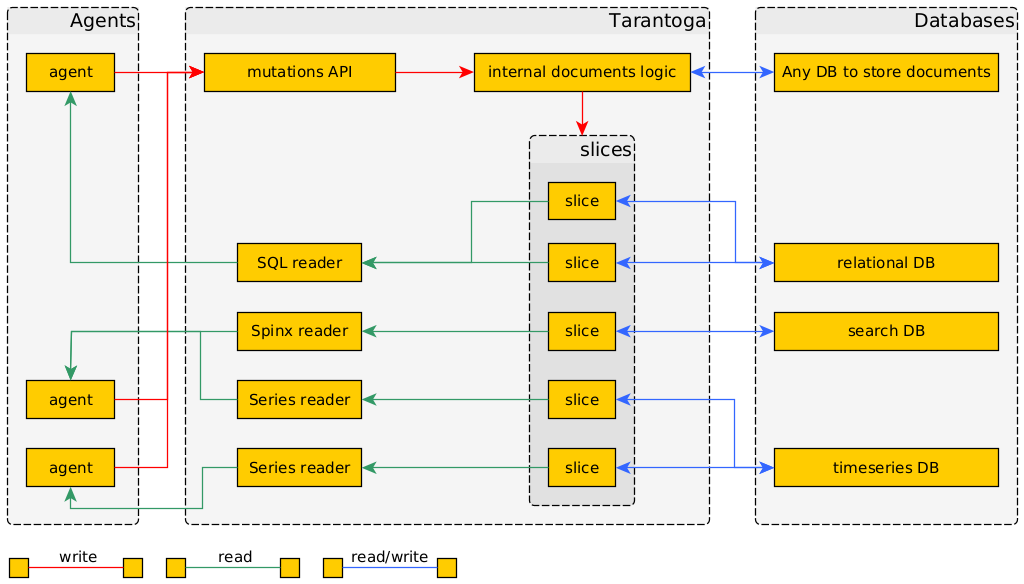
Потоки данных во второй версии прототипа Тарантоги.
Продолжаю эксперименты. Как видно из заголовка, вторая попытка тоже не удалась, хотя выглядит симпатичнее.
Реализация ушла довольно далеко от описанного в посте о первом блине. В частности, GraphQL не подошёл.
Как всегда, работа породила сторонние результаты. Я подумал об уменьшении сложности работы с данными, вынес в отдельную библиотеку логику работы с предикатами.
Вторую версию концепции я считаю жизнеспособной, но сильно затратной для развития в одного разработчика. Вот если бы меня было несколько, или проект уже существовал в рабочем виде, и надо было только дописывать новых агентов.
Но мы имеем, что имеем, поэтому буду думать дальше. Скорее всего попробую сделать в лоб: минималистично, стандартными подходами без интеллектуальных извращений. Всё-таки представление об инструменте уже несколько раз в голове перекрутил и оно значительно упростилось.
А пока расскажу что получилось на этот раз.
Тарантога: первый блин
Продолжаю прототипировать свои идеи. Ожидаемо, первый блин вышел комом: и по срокам и по качеству. Однако получилось опробовать описанные ранее концепции, посмотреть что работает, а что нет.
Фактически, реализована база знаний для хранения метаинформации, GUI для её просмотра, пара агентов. И много нареканий к выбранному пути :-)
Поэтому попробую переосмыслить архитектуру Тарантоги.
Yet another Тарантога
Не только я пытаюсь собрать всю свою информацию в одном месте.
Вот описание созданной за год инфраструктуры от другого энтузиаста.
Знакомство с блогом karlicoss и подтолкнуло меня делать собственный велосипед. Всегда приятно узнать, что ты не один такой упоротый :-) Там же я позаимствовал пару базовых концепций.
В отличии от меня, karlicoss избрал более прагматичный подход:
- Поставил во главу угла data liberation — освобождение данных — получение копий всех сущенственных данных, которыми пытаются владеть облака и прочие сервисы. Возможно, логика в том, что владение данными первично, а как их обработать всегда можно придумать.
- Не пытается (пока) изобретать универсальные форматы или универсальный софт. Просто делает инфраструктуру экспорта, хранения и обработки информации, которая работает. То есть у него получается сеть из источников, экспортёров, обработчиков и дашбордов.
Какой из подходов лучше, не знаю. Я отказался от такого варианта потому, что не вижу как разумными силами в долгосрочной перспективе гарантировать устойчивость настолько гетерогенной сети к регрессиям. В случае с централизованной базой знаний я это хотябы в теории представлю.
Но из того, что чего-то не вижу, не следует, что этого нет.